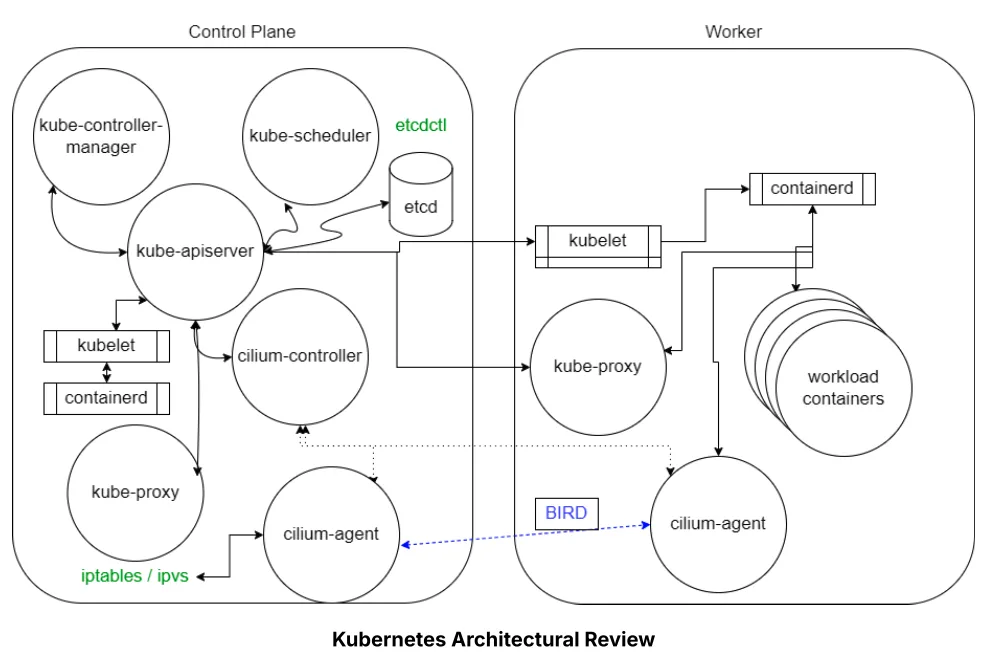
A Microsoft AI platform evolúciója: OpenAI és Foundry
Nem rég fejeztem be egy videós képzési anyagot a Mentor Klub részére, ahol a résztvevők megismerhették az Azure-on belül elérhető OpenAI megoldásokat. Ennek részeként bemutattam az Azure OpenAI Studio felületét is, ami valójában az Azure AI Foundry egyik funkcionális eleme. Mindkettőt elég gyakran használom, különböző projektekben és különböző célokra. Hogy éppen melyik a jobb egy adott feladathoz, azt többnyire az aktuális projekt igényei döntik el.
A Microsoft azonban az elmúlt hónapokban egy olyan változtatást indított el, amely alapjaiban alakítja át azt, ahogyan eddig AI-megoldásokat építettünk Azure-ban. A Foundry platform fokozatosan átveszi az Azure OpenAI Studio szerepét, kiszélesítve annak lehetőségeit és egységesítve az AI-fejlesztés teljes ökoszisztémáját.
Mi volt az Azure OpenAI Studio szerepe
A Microsoft az Azure OpenAI Studio felületet arra hozta létre, hogy egyszerű legyen kipróbálni és tesztelni az Azure által kínált OpenAI modelleket. A felület segítségével lehetett:
- modelleket kipróbálni egy játszótérben
- finomhangolt modelleket kezelni
- API-végpontokat és kulcsokat elérni
- kötegelt feldolgozást és tárolt befejezéseket használni
- értékeléseket futtatni
- és még sok hasznos AI programozást segítő funkciót.
Az Azure OpenAI Studio azonban alapvetően egy modelltípusra, az Azure által értékesített OpenAI modellekre épült. Ez a projektjeim során is érezhető volt: ha más modellgyártó megoldását szerettem volna használni, akkor azt külön kellett integrálni vagy külső szolgáltatásból kellett elérni.
Ez az a pont, ahol a Foundry teljesen más szemléletet hoz.
Mit kínál a Microsoft Foundry?
A Microsoft Foundry egy egységes AI-platform, amely több modellszolgáltatót, több szolgáltatást és teljes életciklus-kezelést egy felületre hoz. A Microsoft Learn dokumentum így fogalmaz: a Foundry egy nagyvállalati szintű platform, amely ügynököket, modelleket és fejlesztői eszközöket egy helyen kezel, kiegészítve beépített felügyeleti, monitorozási és értékelési képességekkel .
A legfontosabb különbségek a következők.
Széles modellkínálat
Az Azure OpenAI-val szemben a Foundry nem korlátozódik egyetlen gyártóra. Elérhetők többek között:
- Azure OpenAI modellek
- DeepSeek
- Meta
- Mistral
- xAI
- Black Forest Labs
- Stability, Cohere és más közösségi modellek
És ez még csak a jéghegy csúcsa.

Ügynökszolgáltatás és többügynökös alkalmazások (AgenticAI)
A Foundry API kifejezetten ügynökalapú fejlesztéshez készült, ahol több modell és komponens együttműködésére van szükség.
Egységes API különböző modellekhez
A Foundry egységes API-t biztosít, így a fejlesztőnek nem kell minden gyártó logikáját külön megtanulnia.
Vállalati funkciók beépítve
A Foundry felületén eleve jelen vannak:
- nyomkövetés
- monitorozás
- értékelések
- integrált RBAC és szabályzatok
- hálózati és biztonsági beállítások
Gyakorlatilag, minden ami a nagyvállalati és biztonságos működéshez elengedhetetlen.
Projektalapú működés
A Foundry projektek olyan elkülönített munkaterületek, amelyekhez külön hozzáférés, külön adatkészletek és külön tároló tartozik. Így egy projektben lehet modelleket, ügynököket, fájlokat és indexeket is kezelni anélkül, hogy más projektekhez keverednének.
Hogyan kapcsolódik össze a két világ
A Microsoft nem megszünteti az Azure OpenAI-t, hanem lehetővé teszi, hogy az adott erőforrás Foundry-erőforrássá alakuljon. A frissítési folyamat lényege:
- a meglévő végpontok és kulcsok megmaradnak
- a finomhangolt modellek és állapotok megmaradnak
- a Foundry funkciói azonnal elérhetővé válnak
- a fejlesztő továbbra is használhatja az Azure OpenAI API-t
Mindezt lépésről lépésre írja le a frissítési útmutató.
Egy példán keresztül…
Amikor még csak Azure OpenAI-val dolgoztam, előfordult, hogy egy ügyfél Meta vagy Mistral modellt szeretett volna kipróbálni összehasonlításként. Ezt külön rendszerben kellett megoldani.
A Foundry megjelenésével ugyanabban a projektben elérhetővé vált:
- GPT-típusú modell
- Mistral
- Meta
- DeepSeek
- és még sok más
Egy projekten belül egyszerre lehet kísérletezni, mérni és értékelni különböző modellek viselkedését.
Mit jelent ez a felhőben dolgozó szakembereknek
A Foundry nem egyszerűen egy új kezelőfelület. A gyakorlati előnyei:
- Egységes platform, kevesebb különálló eszköz
- Könnyebb modellválasztás és modellváltás
- Átláthatóbb üzemeltetés, biztonság és hálózatkezelés
- Bővíthető modellkínálat
- Konszolidált fejlesztői élmény és API
A dokumentáció többször hangsúlyozza, hogy a Foundry nemcsak kísérletezésre, hanem üzleti szintű, gyártásra kész alkalmazásokra is alkalmas. Ez a mindennapi munkában is érezhető.
Miért előnyös ez a vállalatoknak
A vállalatok számára a Foundry több szempontból stratégiai előrelépés:
- Egységes biztonsági és megfelelőségi keretrendszer
- Több modellgyártó támogatása egy platformon
- Könnyebb üzemeltetési kontroll
- Gyorsabb AI-bevezetési ciklus
- Rugalmasabb fejlesztési irányok
A Foundry megjelenésével a cégek már nem csak egyetlen modellre vagy ökoszisztémára építenek, hanem több szolgáltató képességét is bevonhatják anélkül, hogy töredezett lenne a rendszer.
| Tulajdonság | Azure OpenAI | Foundry |
|---|---|---|
| Közvetlenül az Azure által értékesített modellek | Csak Azure OpenAI | Azure OpenAI, Black Forest Labs, DeepSeek, Meta, xAI, Mistral, Microsoft |
| Partner és Közösség modellek a Marketplace-en keresztül – Stability, Cohere stb. | ✅ | |
| Azure OpenAI API (köteg, tárolt befejezések, finomhangolás, értékelés stb.) | ✅ | ✅ |
| Ügynökszolgáltatás | ✅ | |
| Azure Foundry API | ✅ | |
| AI-szolgáltatások (beszéd, látás, nyelv, tartalomértés) | ✅ |
Összegzés
Az Azure OpenAI Studio jó kiindulási pont volt az Azure AI-képességeinek megismerésére és modellek kipróbálására.
A Microsoft Foundry azonban túlnő ezen a szerepen:
egységes platformot biztosít a teljes AI-fejlesztési életciklushoz, több modellgyártóval és kiterjesztett vállalati funkciókkal.
A Microsoft nem leváltja az Azure OpenAI-t, hanem beépíti egy nagyobb, átfogóbb rendszerbe. Ez a lépés hosszú távon kiszámíthatóbb, hatékonyabb és sokkal rugalmasabb AI-fejlesztést tesz lehetővé.