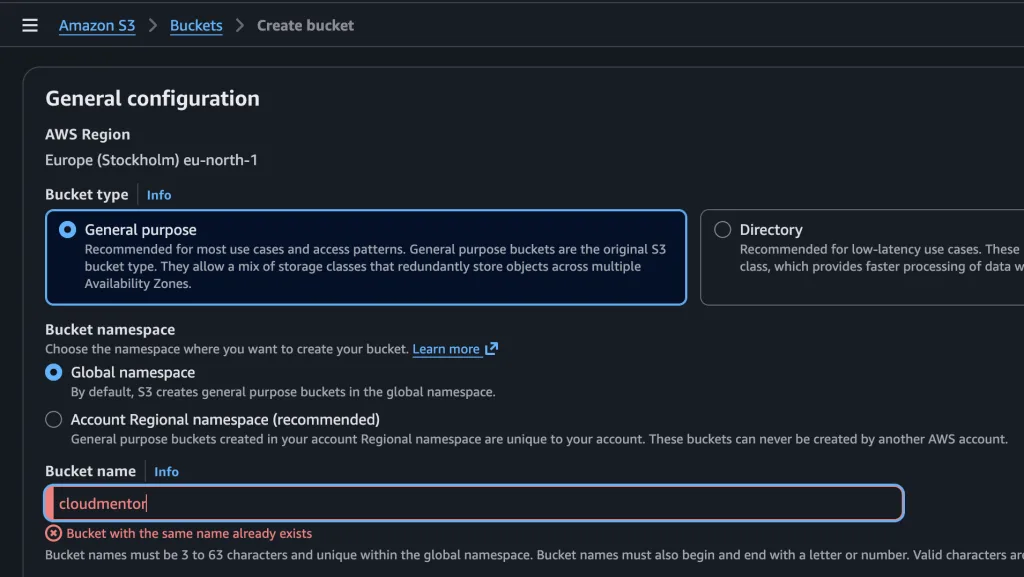
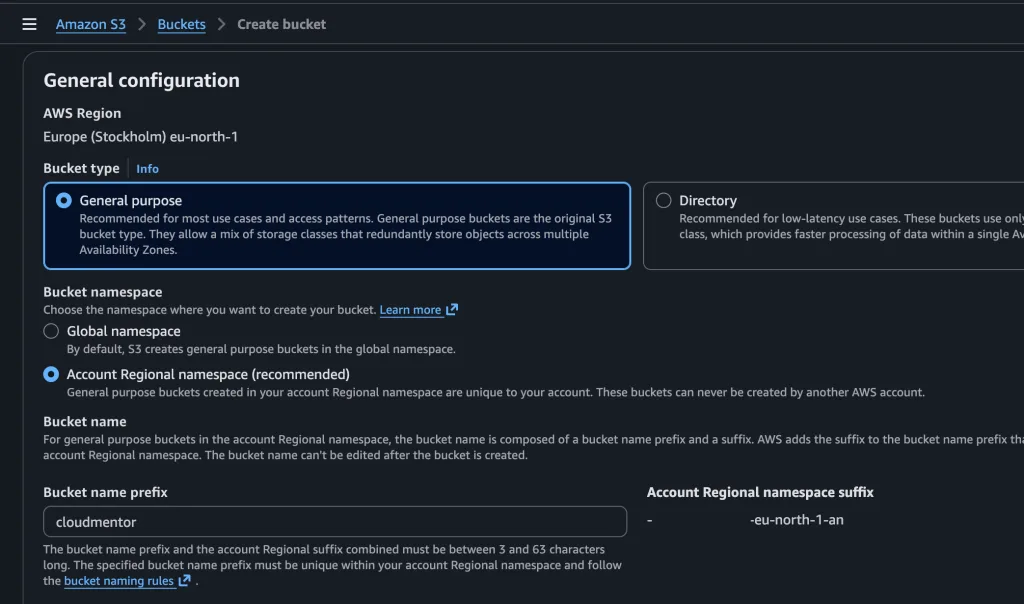
Az S3 20 éve szolgál már minket, mint az egyik legjobb felhő alapú tároló a piacon. Ez alatt a 20 év alatt talán a legidegesítőbb mindig a bucket-ek nevének kiválasztása volt. A kezdetektől – hiszen már az AWS is 20 éves – globálisan egyedi nevet kellett megadnunk, amikor egy S3 bucket-et létrehoztunk.
Aki dolgozott már AWS-sel, biztos belefutott ebba a klasszikus hibába: kiválasztasz egy tökéletes bucket nevet… majd jön a hiba, hogy már foglalt.
És ilyenkor jön a kreatív káosz: alkalmazas-adatok-prod-123
Nem túl elegáns. És ami fontosabb: enterprise környezetben ez nem csak esztétikai probléma, hanem governance és skálázási kérdés is.
Aki régóta dolgozik AWS-el, mint én is, annak az Amazon S3 szinte természetes része lett a mindennapoknak. Olyan, mint a levegő: nem gondolunk rá külön, de mindenhol ott van.
Amikor az Amazon S3 2006-ban megjelent (és vele az S3 is elsőként), még nem beszéltünk microservices-ről, Kubernetes-ről vagy AI modellekről napi szinten. Az adat viszont már a kezdetektől létezett. Csak nem volt ilyen egyszerű kezelni.
Ma pedig ott tartunk, hogy az S3 nem csak egy storage megoldás, hanem egy alapréteg. Egy csendes infrastruktúra elem, ami nélkül a modern cloud gyakorlatilag nem működik.
És most, hogy az AWS a 20. születésnapját ünnepli, érdemes egy pillanatra megállni, és megnézni: mit adott nekünk, és merre tartunk tovább.
Miért volt ennyire meghatározó az S3?
Erre könnyű a válasz: mert egyszerű volt.
Az S3 egy object storage szolgáltatás. Ez azt jelenti, hogy fájlokat (object-eket) tárolunk benne, kulcs-alapú eléréssel, nem klasszikus fájlrendszerként.
A valódi ereje nem ebben van, hanem abban, hogy:
gyakorlatilag korlátlanul skálázódik
nem kell szervereket kezelni
API-n keresztül bárhonnan elérhető
és nagyon magas tartósságot biztosít (durability)
Ez a kombináció 2006-ban forradalmi volt. És szerintem még ma is az.
Mire használják valójában az S3-at?
Sokan azt gondolják, hogy az S3 „csak egy fájltároló”.
A valóságban viszont rengeteg különböző use case épül rá. Nézzünk meg néhányat, amikkel én is rendszeresen találkozom.
1. Backup és archiválás
Ez a klasszikus.
adatbázis mentések
logok tárolása
hosszú távú archiválás (pl. törvényi megfelelőség miatt)
Az S3 lifecycle policy segítségével az adatokat automatikusan lehet költséghatékonyabb ú.n. storage class-ba mozgatni (pl. Glacier, Deep Archive).
Sok cég esetében azonban néha hiba csúszik a gépezetbe: feltöltik az adatokat az S3-ba, de lifecycle szabály nincs létrehozva, majd csodálkoznak, hogy a költségek elszállnak.
Nem kell VM, nem kell Kubernetes. Ez az a „simplicity”, amit sokan túl korán elfelejtenek. Pedig itt szinte ingyen van.
3. Data lake alap
Ez már egy komolyabb use case.
Az S3 gyakran a data lake alapja:
raw adatok tárolása
strukturált és strukturálatlan adatok együtt
későbbi feldolgozás (pl. Athena, Glue)
Itt már megjelenik az adatstratégia, amely egy új színtere egy cég életének. És itt szokott elcsúszni a legtöbb projekt: nincs naming convention, nincs partitioning, így később nehéz kezelni.
4. AI és machine learning
Az elmúlt évek egyik legnagyobb változása. Az S3 ma már az AI pipeline-ok egyik alapja:
training datasetek tárolása
model artifactek mentése
inference input/output tárolás
AWS oldalon például a SageMaker is erősen épít rá, de ugyanez igaz más platformokra is. Nehéz olyan megoldást találni, ahol az S3-at nem használjuk. Igazi alappillér.
5. CI/CD és DevOps
Ezt kevesebben említik, pedig napi szinten használjuk.
Egy egyszerű példa: Egy pipeline build-el egy alkalmazást, majd feltölti S3-ba, és onnan olvassa fel a kódot az AWS Lambda.
Egyszerű, stabil, jól működik.
6. Log és observability adatgyűjtés
Sok rendszer logjai végül S3-ban landolnak:
Terheléselosztó és alkalmazás naplófájlok
CloudTrail események
Hálózati információs naplófájlok
Innen tovább lehet őket feldolgozni (pl. Athena vagy más tool-ok).
Mi változott 20 év alatt?
Őszintén? Az alap koncepció szinte semmit és nekem pont ez tetszik.
Ami változott:
több storage class (költségoptimalizálás)
jobb biztonsági kontrollok (IAM, encryption, bucket policy)
esemény alapú működés (S3 event → Lambda)
integráció más szolgáltatásokkal
Az alap modell ugyanaz maradt. Ez ritka az IT-ban és a jelenlegi világunkban.
És mi jöhet ezután?
Itt érdemes kicsit megállni. Igyekszem biztos dolgokat írni és nem csupán találgatni.
1. S3 mint adatplatform alap
Egyre több rendszer épít közvetlenül S3-ra, nem csak tárolásként, hanem:
query layer-rel
metadata kezeléssel
verziózással
Ez már nem a klasszikus storage használat.
2. AI-first adatkezelés
Az AI miatt az adatok szerepe megváltozott:
nem csak tároljuk, hanem használjuk is folyamatosan
nem csak a struktúrált adat értékes, hanem minden adat számít
Az S3 ebben központi szereplő maradhat.
3. Egyszerűség visszatérése
Ebben a túlbonyolított világban, szükség van az egyszerű és megbízható dolgokra és ilyenkor sokan visszatérnek az alapokhoz:
S3
egyszerű pipeline
kevesebb komponens
Ez nem visszalépés, hanem érettség.
Buktatók S3 használat közben
Ez fontos, mert könnyű belefutni:
nincs lifecycle policy: drága lesz
nem megfelelő access control: biztonsági kockázat
hiányzó elnevezési stratégia: káosz
minden adat egy bucket-ben: kezelhetetlen
Ezek nem technikai problémák, hanem tervezési hibák, amelyek átgondoltsággal könnyen orvosolhatók.
A következő 20 év előtt
Az S3 nem látványos. Nincs UI varázslat, nincs „wow” élmény, de ott van minden mögött.
Az elmúlt 20 évben az egyik legstabilabb alapköve lett a cloud világnak és nem csak az AWS-ben lakó szolgáltatásoknak.
És ha valamit érdemes megérteni mélyen – akár kezdőként is –, akkor ez az. Mert nem csak egy szolgáltatást tanulsz meg. Hanem azt, hogyan gondolkodik a modern infrastruktúra az adatokról.
Lassan egy éve, hogy elkezdtem írni a Kubernetes-ről és annak architektúrájáról, a microservice-alapú rendszerek működéséről és arról, hogyan vált a Kubernetes a modern alkalmazásfejlesztés egyik alappillérévé. Beszéltünk a klaszterek működéséről, a podok életciklusáról, a vezérlőkomponensek szerepéről.
Ezeken felül van egy réteg, amely mindezt összefogja. Beszéltünk már erről is több szempontból, de úgy éreztem érdemes további figyelem ennek a központi elemnek. Mert enélkül sem a kubectl, sem a vezérlők, sem az automatizmusok nem működnének.
Ez a réteg a Kubernetes API.
Olyan ez, mint egy jól szervezett város központi ügyfélszolgálata. Bármit szeretnénk elintézni – új erőforrást létrehozni, meglévőt módosítani, állapotot lekérdezni –, mindent ezen keresztül teszünk. A Kubernetes valójában egy API-vezérelt rendszer. Minden művelet, amit végrehajtunk, végső soron egy API-hívás.
Nézzük meg, hogyan érhetők el az API-erőforrások, milyen speciális végpontok léteznek, hogyan kapcsolódik ehhez a Swagger és az OpenAPI, valamint mit jelent az API-k érettségi modellje.
API erőforrások és a kubectl szerepe
A Kubernetes által publikált összes API-erőforrás elérhető a kubectl eszközön keresztül. A parancs alapformátuma:
kubectl [command] [type] [name] [flag]
A kubectl help parancs részletes információt ad az elérhető műveletekről és erőforrástípusokról.
A rendszer által elérhető API-erőforrások listája folyamatosan változhat, de az alapvető típusok közé tartoznak például:
pods (po)
services (svc)
deployments (deploy)
replicasets (rs)
statefulsets
daemonsets (ds)
jobs
cronjobs
configmaps (cm)
secrets
namespaces (ns)
nodes (no)
persistentvolumes (pv)
persistentvolumeclaims (pvc)
resourcequotas (quota)
limitranges (limits)
networkpolicies (netpol)
clusterroles
clusterrolebindings
roles
rolebindings
customresourcedefinition (crd)
Ez a lista jól mutatja, hogy a Kubernetes nem csupán podokat kezel. A klaszter működéséhez szükséges biztonsági, hálózati, tárolási és jogosultsági objektumok mind API-erőforrásként jelennek meg.
Fontos megérteni, hogy a kubectl valójában csak egy kliens az API server felé. Amikor például kiadjuk a következő parancsot:
kubectl get pods
a háttérben egy HTTP GET kérés történik az API server irányába. A kubectl nem tart fenn külön adatbázist, nem cache-el erőforrásokat önállóan. Minden információ az API-n keresztül érkezik.
Ez a modell teszi lehetővé, hogy a Kubernetes teljesen deklaratív és automatizálható rendszer legyen. Ugyanazokat az API-hívásokat használhatja egy operátor, egy CI/CD pipeline vagy egy egybinárisos vezérlőalkalmazás is.
További API-műveletek erőforrásokon
Az alapvető REST műveleteken túl a Kubernetes API speciális végpontokat is biztosít bizonyos erőforrásokhoz.
Például elérhetjük egy konténer naplóit közvetlen API-hívással:
GET /api/v1/namespaces/{namespace}/pods/{name}/log
Ez funkcionálisan megegyezik a következő paranccsal:
kubectl logs firstpod
Ha a konténer nem ír standard output-ra, akkor természetesen nem lesznek elérhető logok.
Hasonló módon létezik exec végpont is:
GET /api/v1/namespaces/{namespace}/pods/{name}/exec
Ez teszi lehetővé, hogy parancsot hajtsunk végre egy futó podban, például diagnosztikai célból.
Emellett létezik watch mechanizmus is:
GET /api/v1/watch/namespaces/{namespace}/pods/{name}
A watch végpont folyamatosan streameli az erőforrás változásait. Ez kulcsfontosságú a vezérlők működésében. A Kubernetes kontrollerei nem ciklikusan lekérdezik az állapotot, hanem figyelik az eseményeket, és a változásokra reagálnak.
Ez az eseményvezérelt működés biztosítja a rendszer hatékonyságát és skálázhatóságát.
Swagger és OpenAPI a Kubernetesben
A Kubernetes teljes API-ja eredetileg Swagger specifikáció alapján készült, és az idő múlásával az OpenAPI irányába fejlődött.
Ez rendkívül fontos, mert az OpenAPI leírás lehetővé teszi klienskód automatikus generálását. Ha rendelkezésre áll a specifikáció, abból generálható Go, Python, Java vagy más nyelvű klienskönyvtár.
A stabil erőforrás-definíciók elérhetők a hivatalos dokumentációban. Emellett a Swagger UI segítségével böngészhetők az API-csoportok, megtekinthetők a végpontok, paraméterek és válaszstruktúrák.
Ez a fajta formális API-leírás teszi lehetővé, hogy a Kubernetes ökoszisztéma ennyire gazdag legyen. Az operátorok, kliensek, SDK-k és automatizációs eszközök mind ugyanarra a formálisan definiált API-ra épülnek.
API-csoportok és verziózás
A Kubernetes API nem egy monolitikus struktúra. API-csoportokra és verziókra bontva épül fel.
Az API-csoportok és verziók használata lehetővé teszi, hogy a fejlesztés előrehaladjon anélkül, hogy egy meglévő API-csoport módosulna. Ez segíti a skálázható fejlesztést és a csapatok közötti munkamegosztást.
Fontos, hogy az API és a Kubernetes szoftververziója csak közvetetten kapcsolódik egymáshoz. Nem minden szoftverfrissítés jelent API-törést.
A Kubernetes API JSON és Google Protobuf szerializációs formátumokat használ, amelyek a kiadási irányelvekhez igazodnak.
Az API-verziók három érettségi szintbe sorolhatók:
Alpha
Beta
Stable
Alpha
Az alpha jelölésű funkciók kísérleti állapotban vannak. Alapértelmezetten le vannak tiltva. Hibásak lehetnek, bármikor változhatnak vagy eltűnhetnek, és nem garantált a visszafelé kompatibilitás.
Csak teszt klaszterben javasolt a használatuk, amelyet gyakran újraépítenek.
Beta
A beta szintű funkciók már jobban teszteltek, és alapértelmezetten engedélyezettek. A változások során figyelnek a visszafelé kompatibilitásra, de még nem tekinthetők teljesen stabilnak.
Előfordulhatnak hibák vagy viselkedésbeli módosulások.
Stable
A stable verziókat csak egy szám jelöli, például v1. Ezek stabil API-k, amelyekre hosszú távon lehet építeni. Jelenleg a v1 az egyetlen stabil verzió.
A verziózási rendszer biztosítja, hogy a klaszterben futó alkalmazások ne törjenek el egy frissítés során, és a platform evolúciója kontrollált módon történjen.
Miért fontos ez a gyakorlatban?
Ha Kubernetes környezetben dolgozol, akkor valójában folyamatosan az API-val dolgozol, akár tudatosan, akár nem.
Amikor YAML fájlt alkalmazol, amikor egy CI/CD pipeline deployol, amikor egy operátor létrehoz egy egyedi erőforrást CRD-n keresztül, minden az API-n keresztül történik.
Az API-csoportok és verziók ismerete segít:
• megérteni, hogy egy erőforrás mennyire stabil • eldönteni, hogy production környezetben használható-e • tervezni a frissítési stratégiát • automatizálási eszközöket építeni
A Kubernetes nem egyszerűen konténer-orchestration eszköz. Egy deklaratív, API-vezérelt platform, amely formálisan definiált interfészeken keresztül működik.
Ha ezt a réteget érted, akkor nem csak használod a klasztert, hanem érted is, hogyan gondolkodik.
És ez az a pont, ahol a Kubernetes már nem csak technológia, hanem architektúra.
Senki sem szereti a rendetlenséget. Akkor sem, ha nem vagyunk rendmániások. Valahol mindannyiunknak szüksége van arra a fajta belső nyugalomra, amit az ad, hogy a dolgok a helyükön vannak. Egy rendezett tér nem csak esztétikai kérdés: segít tisztábban gondolkodni, könnyebben eligazodni, és biztonságérzetet ad a mindennapokban.
Nincs ez másképp a Kubernetes cluster esetében sem. Amikor egyre több alkalmazást, podot, service-t és konfigurációt indítunk el, hamar rájövünk, hogy a rendszer saját “lakói” is igénylik a strukturáltságot. A Kubernetes pedig erre egy elegáns, mégis egyszerű megoldást kínál: a namespace-eket, amelyek láthatatlanul, de nagyon is hatékonyan teremtik meg azt a rendezettséget, amelyre egy növekvő clusternek szüksége van.
Mi az a namespace?
A Kubernetesben a namespace egy logikai szeparációs mechanizmus, amely csoportokra bontja a cluster erőforrásait. A fogalom eredetileg a Linux kernel világából származik: ott is az izoláció a cél, vagyis hogy különböző folyamatok saját, elkülönített erőforrás-nézetet kapjanak.
A Kubernetes ezt továbbgondolja: a namespace nem csupán technikai elszeparálás, hanem egy szervezési, erőforrás-kontroll és biztonsági keret is.
Lényeg:
Minden API-hívás egy namespace-en belül történik, hacsak nem adunk meg külön mást. Például: https://<api-server>/api/v1/namespaces/default/pods
A namespace lehetővé teszi a kvóták és limitációk alkalmazását egy adott csoport erőforrásaira.
Később az access control – például RBAC – is működhet namespace-szinten.
Ha csak néhány erőforrás van a clusterben, akkor a szükségessége nem mindig látszik. De nagyobb vállalati környezetben a namespace az egyik legfontosabb szervezési eszköz.
A Kubernetes alapértelmezett namespace-ei
Amikor egy új clustert létrehozunk, Kubernetes négy namespace-t hoz létre automatikusan. Ezek előre definiált szerepet töltenek be, és fontos, hogy ismerjük őket.
default
Az alapértelmezett namespace. Ha nem adunk meg explicit namespace-t egy API-hívásban vagy egy YAML-ben, minden ide kerül.
kube-system
Itt futnak a rendszer- és infrastruktúra szintű komponensek. Maga a Kubernetes működéséhez szükséges podok találhatók itt, például a DNS, a kontrollerek, scheduler stb.
kube-public
Ez egy mindenki számára olvasható namespace (még hitelesítetlen felhasználók számára is). Tipikusan olyan információkat tartalmaz, amelyeknek publikusnak kell lenniük.
kube-node-lease
Ez tárolja a node-ok „lease” objektumait. A control plane ezzel követi a node egészségi állapotát, gyorsabban és hatékonyabban, mint korábban.
Hogyan dolgozunk namespace-ekkel?
A namespace-ek egy része kimondottan szervezési célokat szolgál: a fejlesztői, tesztelési és éles környezet könnyen elkülöníthető, de akár csapatonként, projektenként vagy üzleti funkcióként is létrehozhatunk új namespace-eket.
A legfontosabb alapműveletek:
Meglévő namespace-ek listázása
kubectl get ns
Új namespace létrehozása
kubectl create ns sajat-projekt
Namespace részletes leírása
Megmutatja többek között a címkéket, annotációkat, kvótákat, limiteket.
kubectl describe ns sajat-projekt
Namespace tartalmának YAML formátumú lekérése
kubectl get ns/sajat-projekt -o yaml
Namespace törlése
kubectl delete ns sajat-projekt
Namespace használata YAML fájlokban
Ha egy erőforrást szeretnénk egy konkrét namespace-ben létrehozni, azt a metadata blokkban kell megadni:
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: sajat-projekt
Ez a mindennapi Kubernetes fejlesztés egyik alapja: a pod encapsulation, a resource isolation és a cluster szervezése így lesz konzisztens, rendezett és biztonságos.
pod encapsulation: A „pod-beágyazás” azt jelenti, hogy a Kubernetes egyetlen kezelhető egységbe, az úgynevezett Podba foglal egy vagy több szorosan együttműködő konténert, a közösen használt tárolót és hálózati erőforrásokat. Ez lehetővé teszi, hogy konténerek egységes egészként működjenek: közösen használják az olyan erőforrásokat, mint a tároló vagy a hálózat, miközben a rendszer egy csomóponton (node) együtt ütemezi és kezeli őket. Ez a megközelítés jelentősen leegyszerűsíti az alkalmazások telepítését és skálázását.
Mikor érdemes namespace-t használni?
A namespace akkor segít igazán, ha:
több csapat dolgozik ugyanabban a clusterben,
több környezetet szeretnénk egymástól elszeparálni (dev, test, staging, prod),
erőforráskvótákat kell alkalmazni (CPU, memória, storage),
korlátozni akarjuk az erőforrások láthatóságát vagy módosíthatóságát,
Kisebb clusterben nem mindig tűnik létkérdésnek, de hosszú távon a namespace az egyik legfontosabb szervezési eszköz, ami segít megelőzni a káoszt.
Összegzés
A namespace látszólag egy apró részlet a Kubernetesben, mégis az egész ökoszisztéma egyik legfontosabb alapköve. Rendet teremt, felelősségi köröket választ szét, erőforrásokat szabályoz, és előkészíti a terepet a biztonságos, skálázható működéshez.
Ahogy tovább haladunk a Kubernetes mélyebb rétegei felé, újabb olyan elemeket fogunk megismerni, amelyek pontosan ilyen csendben, mégis hatalmas erővel segítik a fejlesztőket, üzemeltetőket és szervezeteket abban, hogy a microservice-ek világában stabil rendszereket építsenek.
Amikor legutóbb a Kubernetes API-ról mint „a kommunikáció idegrendszeréről” írtam, sok visszajelzést kaptam arról, mennyire segített érthetővé tenni a fürt működését. Most innen folytatjuk a történetet. Az előző cikkben is sok mindent megmutattam, hogy érthetőbbé tegyem a cluster belső működését, és most megvizsgáljuk, hogyan zajlik valójában az információáramlás a Kubernetes belső világában.
Ennek a cikknek a célja, hogy az API működésének gyakorlati oldalát mutassa be: hogyan jelenik meg mindez a legegyszerűbb kapszula létrehozásánál, mit csinál a kubectl valójában a háttérben, hogyan lehet a klaszteren kívülről hozzáférni az API-szerverhez, és mire szolgál a mindenki által használt ~/.kube/config fájl.
A Kubernetesben minden objektum, minden módosítás, minden lekérdezés API-hívások sorozata. Ha értjük ezt a réteget, a rendszer teljes működése világossá válik.
1. A kapszula mint API-objektum: a legkisebb egység
Az előző cikkben már beszéltünk arról, hogy a kapszula a Kubernetes legkisebb futtatási egysége. Az alábbi példa egy minimális, mégis rendkívül tanulságos kapszula-definíciót mutat be:
Ez a néhány sor már minden lényeges elemet tartalmaz:
apiVersion – melyik API-csoportot használja az objektum;
kind – az erőforrás típusa (Pod);
metadata – az objektum azonosító adatai;
spec – a kapszulában futó konténerek és paramétereik.
A létrehozás és lekérdezés mind API-hívások sorozatán keresztül történik:
kubectl create -f elsopod.yaml
kubectl get pods
kubectl get pod elsopod -o yaml
kubectl get pod elsopod -o json
A külvilág számára ezek egyszerű parancsoknak tűnnek, de valójában a kubectl az API-szerverhez küld lekérdezéseket és módosítási kéréseket.
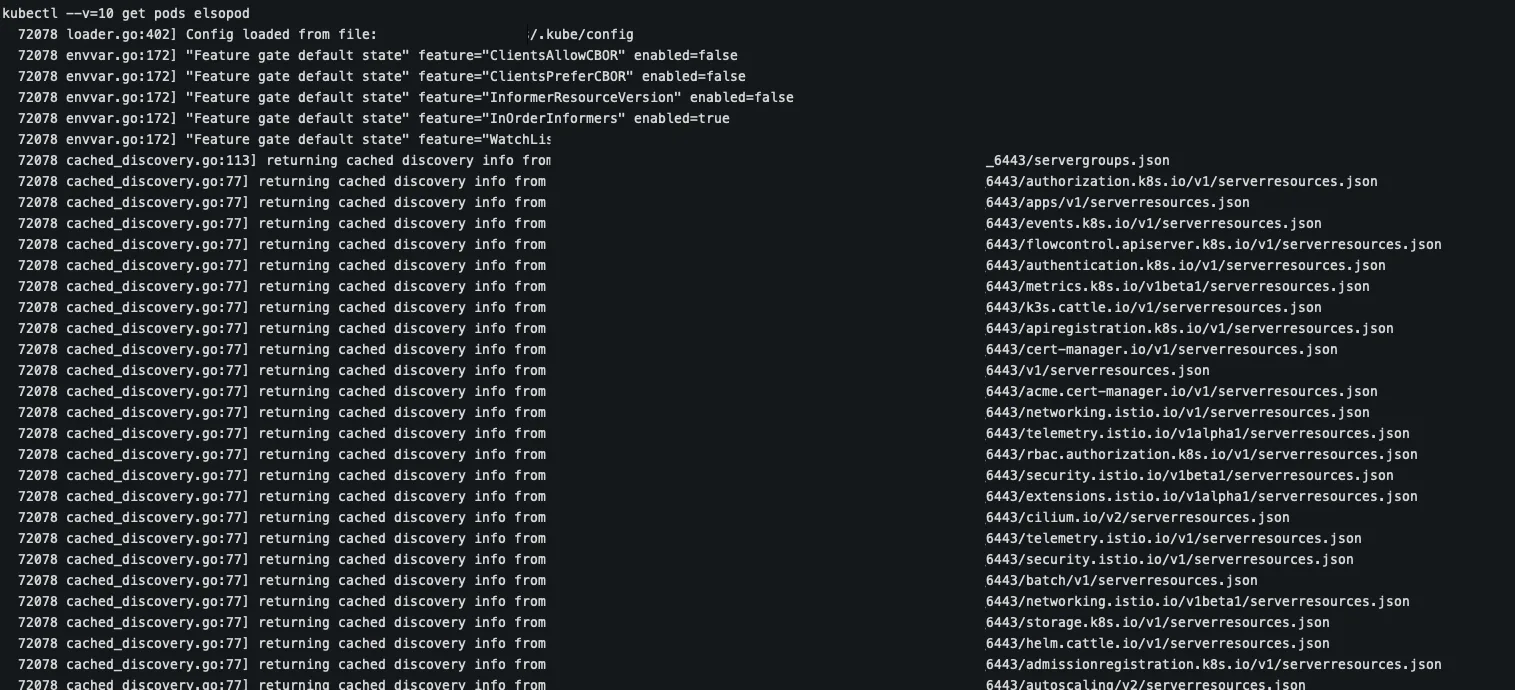
2. Hogyan kommunikál valójában a kubectl?
A Kubernetes minden erőforrást RESTful API-n keresztül kezel. Ez azt jelenti, hogy a kubectl működése valójában nem más, mint HTTP-hívások generálása az API-szerver felé – tipikusan JSON formátumú kommunikációval.
Ha szeretnénk még többet megtudni arról, mit csinál a kubectl a háttérben, akkor kapcsoljuk be a részletes – verbose – naplózást:
a két fél között TLS-sel védett HTTP-forgalom zajlik.
Ez a tudás fontos, mert így értjük meg igazán, mi történik akkor, amikor mi „csak” egy új kapszulát hozunk létre vagy lekérjük a futó erőforrásokat.
3. Hozzáférés a Kuberneteshez a klaszteren kívülről
A legtöbb adminisztrációs feladat a kubectl használatával történik, de akár közvetlenül curl-lel is kommunikálhatnánk a Kubernetes API-szerverével. A gond csak az, hogy ehhez hitelesített, TLS-sel védett kapcsolat kell. És mit kell tudni a klaszterhez tartozó API-król?
A klaszter API végpontjának adatai a kubectl config view kimenetében találhatók.
A kliens a hitelesítési adatokat a ~/.kube/config fájlból olvassa ki.
E nélkül a fájl nélkül a hozzáférés legfeljebb korlátozott, „insecure” módon lehetséges, amellyel a legtöbb művelet nem érhető el.
Ezért mondjuk, hogy a kubeconfig a hozzáférés kulcsa: nélküle a klaszter elérhetetlen lenne.
4. A kubeconfig felépítése és jelentése
A ~/.kube/config fájl a Kuberneteshez való hozzáférés központi eleme. A benne található adatok határozzák meg:
melyik klaszterhez csatlakozunk,
milyen felhasználó nevében tesszük ezt,
milyen hitelesítési adatokat használunk,
és milyen kontextusban fut a kubectl.
A kubeconfig több fő részből áll, amelyek együtt írják le a kapcsolat minden aspektusát. Egy alap struktúra így néz ki:
Ahogy minden Kubernetes-objektumnál, itt is meg kell határozni, hogy a fájl melyik API-verzió szerint értelmezendő. A kubeconfig esetében ez tipikusan v1.
clusters
A klaszter(ek) eléréséhez szükséges adatok:
server – az API-szerver címe, amelyhez a kubectl csatlakozik;
certificate-authority-data – a CA tanúsítvány, amely biztosítja, hogy a kliens a megfelelő API-szerverhez kapcsolódjon, és a kapcsolat hiteles legyen.
Ezek alapján a kubectl tudja, hová küldje a kéréseit.
users
Itt találhatók a kliens hitelesítési adatai. Tipikusan:
kliensoldali tanúsítvány,
privát kulcs,
vagy token.
A Kubernetes ebben a részben tárolja, hogy a felhasználó milyen módon igazolja magát a klaszter felé.
contexts
A context egy hármas kapcsolat:
melyik klasztert használjuk,
melyik felhasználó nevében,
és milyen alapbeállításokkal (pl. namespace).
Ez teszi lehetővé, hogy ugyanarról a gépről több klaszterrel is dolgozhassunk, akár eltérő jogosultságokkal.
current-context
Ez mondja meg, hogy a kubectl éppen melyik contextet használja alapértelmezésként. Ha nem adunk meg külön kapcsolót minden parancsnál, akkor ez a context érvényesül.
preferences
Ritkán használt beállítások, például megjelenítési opciók. A legtöbb esetben üres marad.
5. Miért fontos mindezt érteni?
A kubeconfig nem csupán technikai részlet: a Kubernetes működésének egyik kulcsdarabja. Ez határozza meg, hogy:
melyik klaszterrel kommunikálsz,
milyen jogosultsággal,
milyen biztonsági réteg alatt.
Ha a kubeconfigot érted, akkor magabiztosan tudsz klaszterek között váltani, hibákat diagnosztizálni, saját API-hívásokat küldeni, vagy akár több környezetet is kezelni ugyanazon a gépen.
A történet pedig itt még nem ér véget – a Kubernetes mélyebb rétegei csak most kezdenek igazán érdekessé válni.
A felhős monitoring az egyik legösszetettebb terület az Azure-ben. Rengeteg szolgáltatás, beállítás, rövidítés és „best practice” kering körülötte, miközben a legtöbb ember csak azt szeretné tudni: látom-e, mi történik a virtuális gépemen; és ha több virtuális gépem van, tudom-e azok naplóbejegyzéseit egy helyen kezelni.
Nemrég az egyik mentoráltammal belekóstoltunk ebbe a világba. Ő kifejezetten rákapott a monitoring ízére, ami jó jel, viszont közben számomra is világossá vált, hogy nem a tankönyv szerinti megoldás a legjobb megközelítés ahhoz, hogy valóban megértsük ennek a világnak a működését.
Miért mondom ezt? Mert sokan úgy gondolják – és én is így mutattam be korábban –, hogy akkor kell beállítani a naplófájlok gyűjtését, amikor a virtuális gépet létrehozzuk. Hiszen amikor összetett rendszerekkel dolgozunk, általában egy előre beállított, finomhangolt monitoring rendszerbe illesztjük be az új gépeket.
Ezzel azonban pont azt a logikus, jól követhető utat kerülöm el, amelyen keresztül az érdeklődők a legkönnyebben elérik a céljukat: hogy gyorsan átlássák ezt a komplex világot.
Mit javaslok tehát? Kövessük a józan észt, és gondoljuk végig, mi egy alkalmazás vagy rendszer természetes evolúciója. Hogyan történik ez a valóságban, amikor kicsiben kezdünk?
Először létrehozok egy vagy több virtuális gépet, alapbeállításokkal, majd telepítem rájuk az alkalmazásaimat. Jön még egy gép, aztán még egy. Egy idő után azt veszem észre, hogy egy nagy, összetett rendszerem van, viszont vak vagyok: nem látom, mi történik a virtuális gépeimen, és nem látom a gépek által létrehozott naplóbejegyzéseket sem.
Ekkor jön a következő lépés: beállítom az Azure Monitor megoldását, hogy legyen szemem és fülem. És innentől már értelmezhető adatokat kapok arról, mi történik a rendszeremben.
Ugye milyen egyszerű így?
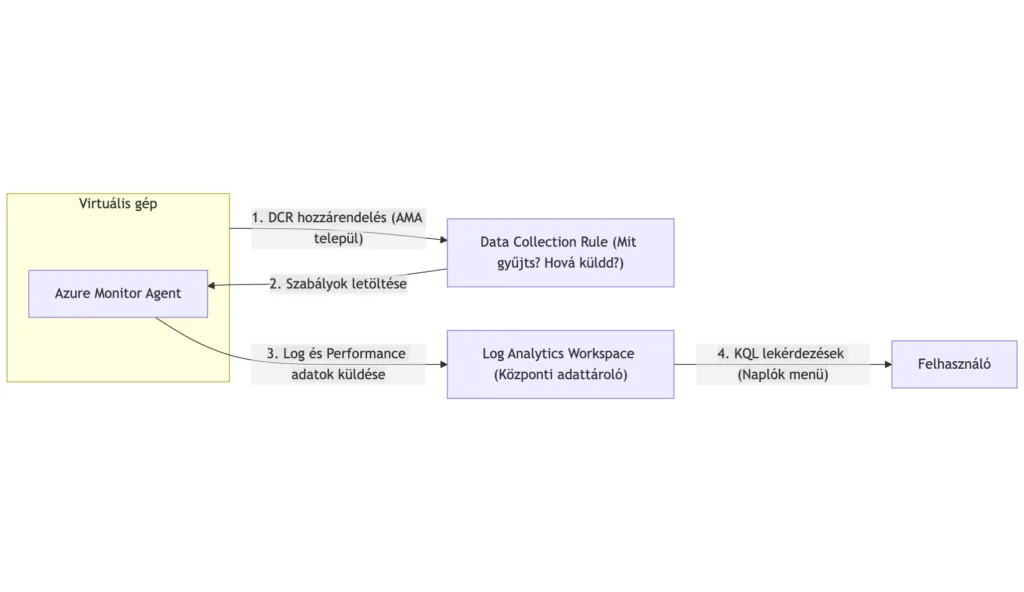
Ebben a cikkben erről – pontosabban ennek egy pici, de nagyon fontos szeletéről – fogok egy alap konfigurációt bemutatni. A fókusz a naplóbejegyzések központi kezelése lesz az Azure Monitoron belül.
Ennek két legfontosabb komponense:
a Log Analytics Workspace
és a Data Collection Rules (DCR)
Ezek adják az egész VM-alapú naplózás és megfigyelés gerincét.
Később górcső alá vesszük az Azure Monitor további elemeit is, hogy jobban belelássatok ebbe a nagyon komplex, mégis rendkívül izgalmas világba.
Nem elméleti áttekintést szeretnék adni, és nem is egy „mindent bele” vállalati monitoring architektúrát bemutatni. A célom sokkal egyszerűbb és gyakorlatiasabb:
megérteni, mi a szerepe a Log Analytics Workspace-nek,
tisztázni, mire valók a Data Collection Rules,
és végigmenni egy egyszerű beállításon Linux és Windows Server virtuális gépek esetén is.
Alapfogalmak és szerepek
Log Analytics Workspace (LAW) a központi adattároló, ahová minden log és metrika beérkezik. Gyakorlatilag egy speciális adatbázis, amely KQL (Kusto Query Language) lekérdezéseket támogat. Egy workspace több száz VM-et is kiszolgálhat, de szervezeti vagy biztonsági okokból létrehozhatsz többet is.
Data Collection Rule (DCR) határozza meg, hogy mit gyűjtsünk, honnan és hová küldjük. Ez a „szabálykönyv”, ami összeköti a forrásokat (VM-ek) a célponttal (LAW). A DCR-ek rugalmasak: különböző szabályokat alkalmazhatsz különböző VM-csoportokra.
Azure Monitor Agent (AMA) a VM-eken futó agent, ami a DCR alapján gyűjti és továbbítja az adatokat. Ez váltotta le a régi Log Analytics Agent-et (MMA) és a Diagnostics Extension-t.
A terv
Az alábbi lépéseket fogjuk követni tehát:
Virtuális gépek (Linux, Windows) létrehozása (nagyon felületesen, mert tényleg alapbeállításokkal hozzuk létre)
Log Analytics Workspace létrehozás
Data Collection Rule létrehozás és beállítás
Azure Monitor Agent ellenőrzése a Virtuális gépeken
Naplóbejegyzések lekérdezése központilag
Öt egyszerű lépés, ami segít megérteni hogyan működik ez a szörnyeteg.
1. lépés: Virtuális gépek létrehozása
Amikor elindul a vállalkozásunk, először egy vagy tövv gépet hozunk létre. Tegyük ezt most is.
Minden lépést a Portálon fogunk elvégezni, az egyszerűség kedvéért.
A Marketplace-n keresd meg: „Ubuntu 24.04 LTS – all plans including Ubuntu Pro”
Ebből hozz létre egy „Ubuntu Server 24.04 LTS”
Gép neve legyen „linux-monitor”
Méret legyen egy kicsi, pl.: Standard_B1s
Hitelesítés típusa legyen Nyilvános SSH-kulcs
Lemez esetén elegendő egy Standard SSD
Hálózatnál létrehozhatunk egy monitor-vnet nevű hálózatot
A többi beállítást nem is módosítjuk, hanem hagyjuk úgy, ahogy az látjuk, tehát menjünk a Felülvizsgálat + létrehozás lapra
És hozzuk létre az első virtuális gépünket
Windows vm
A Marketplace-n keresd meg: „Windows Server”
Ebből hozz létre egy „Windows Server 2022 Datacenter”
Gép neve legyen „windows-monitor”
Méret legyen egy kicsi, pl.: Standard_B2s
Rendszergazdai fióknál állítsunk be egy felhasználónevet és a hozzátartozó jelszót
Lemez esetén elegendő egy Standard SSD
Hálózatnál válasszuk a linux-nál létrehozott monitor-vnet nevű hálózatot
A többi beállítást nem is módosítjuk, hanem hagyjuk úgy, ahogy az látjuk, tehát menjünk a Felülvizsgálat + létrehozás lapra
És hozzuk létre a második virtuális gépünket
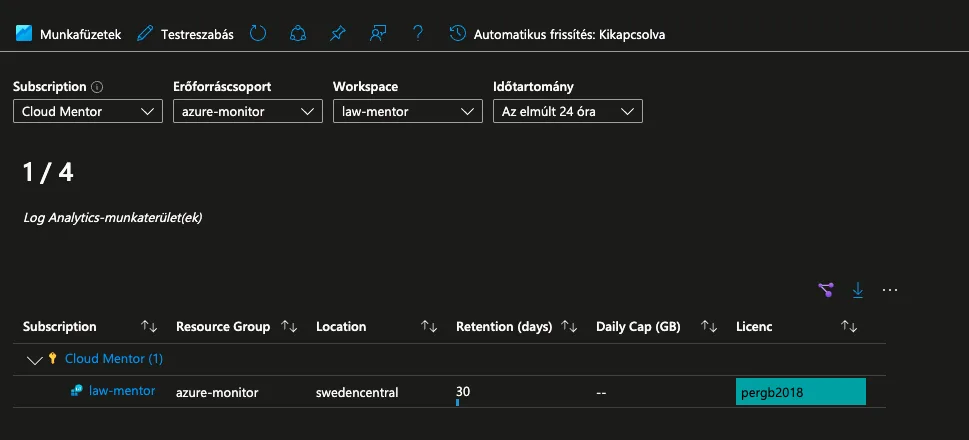
2. lépés: Log Analytics Workspace létrehozása
Eljutottunk tehát oda, hogy megvannak a gépeink, de nem tudjuk mi is van velük, vagy mi történik az alkalmazásokkal. Kell nekünk egy központi tároló, ahová a gépeken keletkező naplóbejegyzések és/vagy metrikák beérkeznek. Most ezt hozzuk létre.
Felül a keresőben keresd meg: „Log Analytics-munkaterületek„, majd kattintsunk rá.
Kattints: „+ Létrehozás” gombra
Töltsd ki:
Előfizetés: válaszd ki
Erőforráscsoport: válaszd a korábban létrehozttat
Név: egyedi név (pl.: law-mentor)
Régió: válaszd azt amit az erőforráscsoportnál és a VM-eknél is használtál
Kattints: „Áttekintés és létrehozás”, majd hozd létre. 1-2 perc és létrejön.
Most már van egy adatbázisunk, ahová gyűjthetjük az adatokat.
3. lépés: Data Collection Rule létrehozás és beállítás
Egyre közelebb vagyunk a célunkhoz. Most hozzuk létre azt a szabályt, hogy a létező VM-ekről milyen adatokat szeretnénk látni a központi adatbázisban (Log Analytics Workspace)
Alap adatok
Felül a keresőben keresd meg: „Monitorozás”, majd kattintsunk rá.
A bal oldali panelon keressük meg a Beállítások > Adatgyűjtési szabályok elemet és kattintsunk rá
Kattints: „+ Létrehozás” gombra
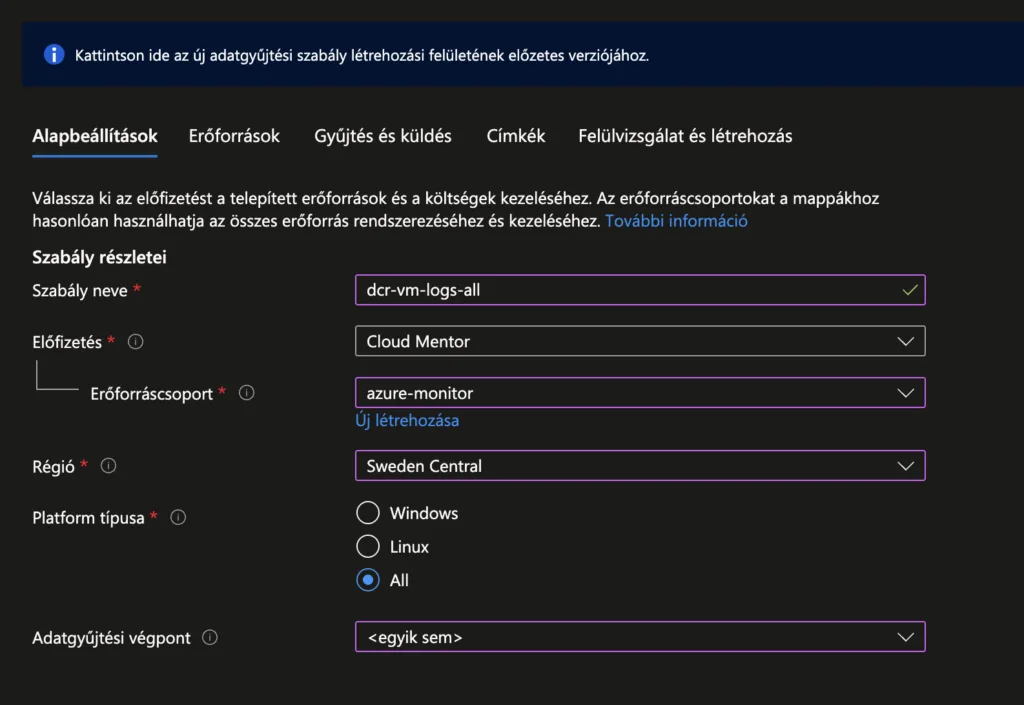
Add meg a szabály alap adatait:
Szabály neve: pl: dcr-vm-logs-all
Előfizetés és erőforráscsoport: ugyanaz, mint a LAW
Platform típusa: válaszd „All” (Ha Windows és Linux is kell. Mi most ezt szeretnénk)
Adatgyűjtési végpont: Nekünk ez most nem szükséges, mert Azure-on belüli gépekhez hozzuk létre
Kattints: „Következő: Erőforrások >” gombra
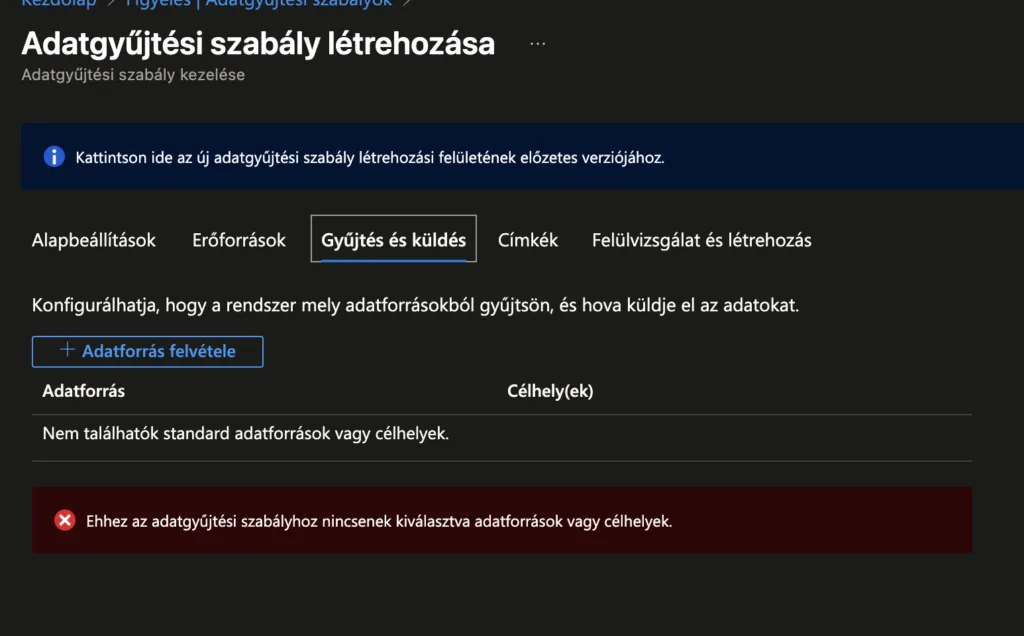
Erőforrások fül: Itt adod hozzá a VM-eket, amikről gyűjteni szeretnél. Kattints „+ Erőforrások hozzáadása” gombra és válaszd ki a VM-eket amelyeket korábban létrehoztál. (Az AMA agent automatikusan települ, ha még nincs fent.)
Kattints: „Következő: Gyűjtés és küldés >” gombra
Gyűjtés és küldés fül: Itt definiálod az adatforrásokat (mit olvasson be a VM-ekről)
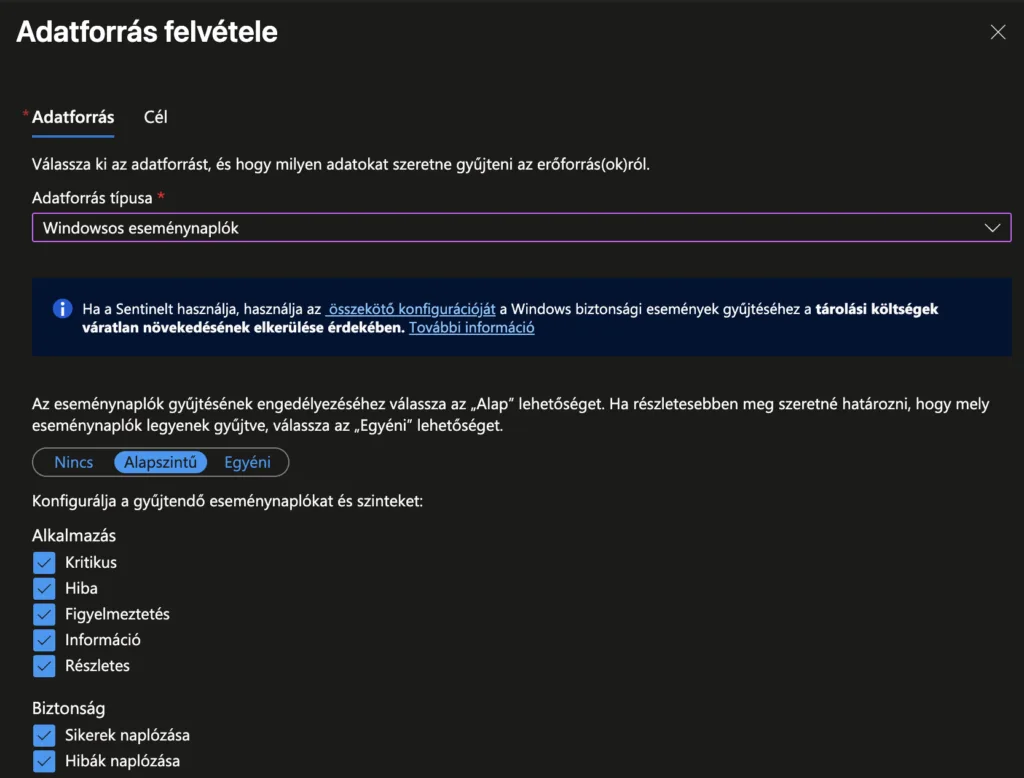
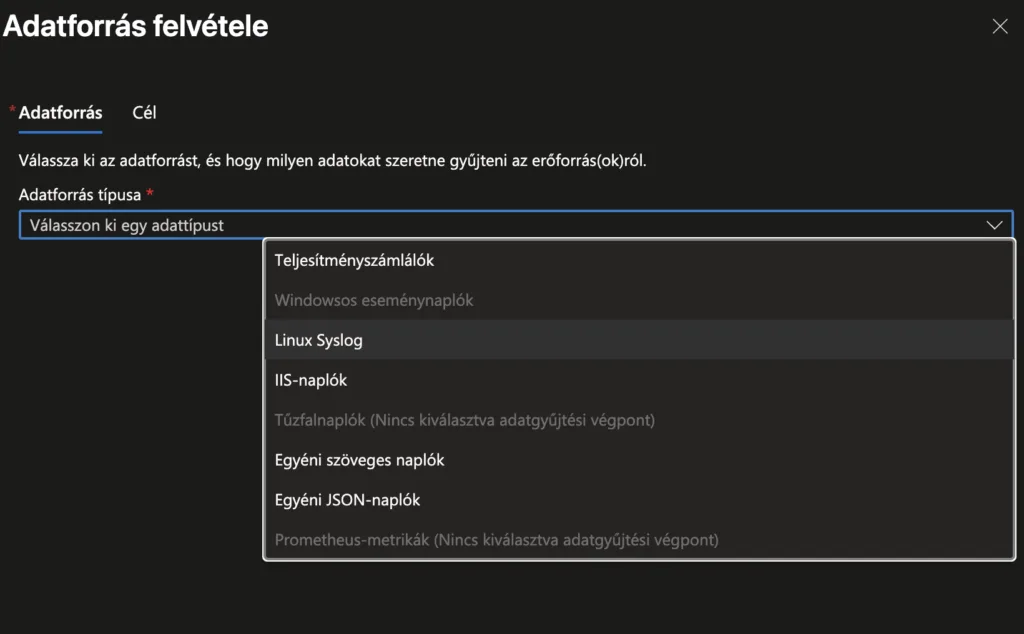
Windows adatforrás
Kattints „+ Adatforrás felvétele”
Adatforrás típusánál válaszd a „Windowsos eseménynaplók” elemet. Ezzel lehetőséged van beolvasni azokat az eseménynapló-bejegyzéseket, amelyekre szükséged van. Ezeket nagyon részletesen testre lehet szabni.
Mi most itt csak az Alapszintű elemeket fogjuk gyűjteni. Jelöld ki mindet.
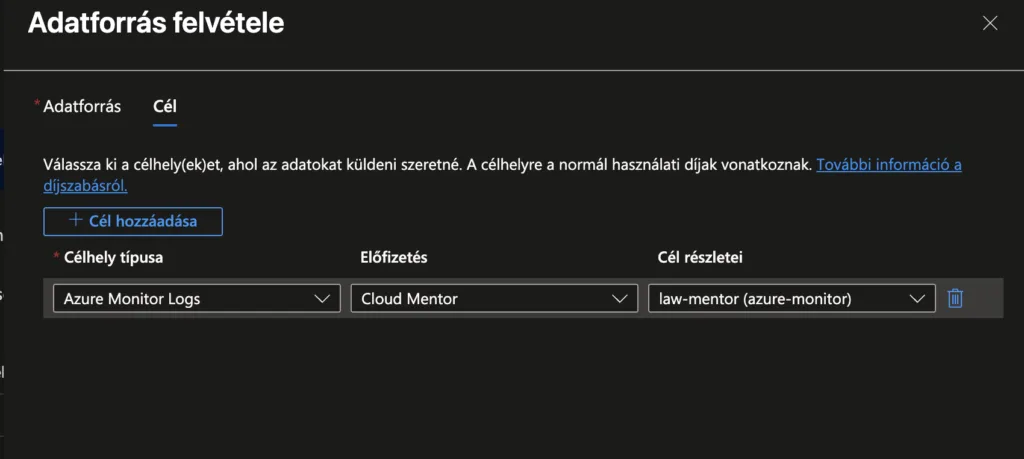
Ebben az ablakban kattints „Következő: Cél >” gombra.
Ellenőrizd, hogy a megfelelelő LAW-ba mennek-e az adatok majd. Ha igen, kattints az Adatforrás felvétele gombra.
Ezzel a Windows naplóbejegyzések betöltése készen áll
Linux adatforrás
Kattints „+ Adatforrás felvétele”
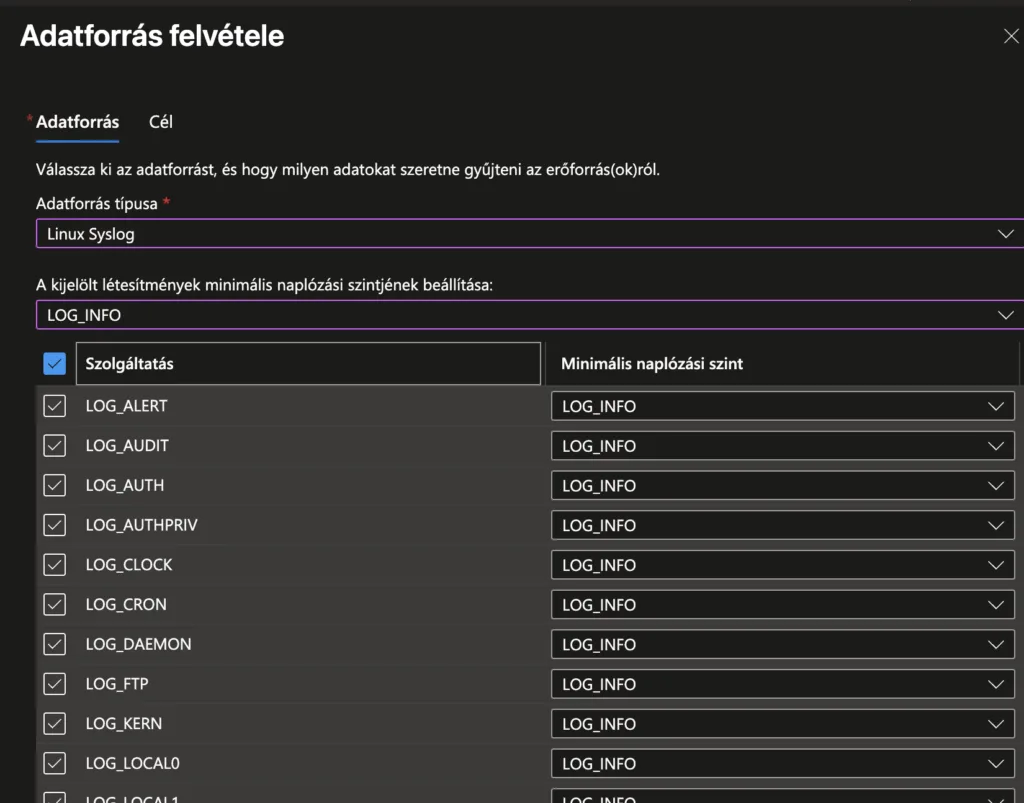
Adatforrás típusánál válaszd a „Linux Syslog” elemet. Ezzel lehetőséged van beolvasni azokat az eseménynapló-bejegyzéseket, amelyekre szükséged van. Ezeket nagyon részletesen testre lehet szabni.
Ezután be kel állítanunk, hogy mi a minimális naplózási szint, amit szeretnénk beállítani. Alapvetően senkinek nem javaslom, hogy beállítsa az LOG_INFO szintet, de a példánk miatt, most ezt tesszük.
Majd, szintén a példa kedvéért, kiválasztjuk az összes szolgáltatást.
Ebben az ablakban kattints „Következő: Cél >” gombra.
Ellenőrizd, hogy a megelelelő LAW-ba mennek-e az adatok majd. Ha igen, kattints az Adatforrás felvétele gombra.
Ezzel a Linux naplóbejegyzések betöltése is készen áll.
Szabály véglegesítése
Megvan a két adatforrásunk. A többi beállítást nem is módosítjuk, hanem hagyjuk úgy, ahogy az látjuk, tehát menjünk a Felülvizsgálat + létrehozás lapra
És hozzuk létre a szabályt.
Most várnunk kell 5-10 percet, amíg elindul az adatok betöltése. Amíg ez megtörténik, ellenőrizzük le mindegyik VM-ünk esetén, hogy a monitor ügynők települt-e.
Megjegyzés: A teljesítmény metrikák beállítása is hasonlóan történik, ott az adatforrás típusa lesz más.
4. lépés: Azure Monitor Agent ellenőrzése a Virtuális gépeken
Ezt mindkét típusú (Linux, Windows) virtuális gépnél ugyanott tudjuk megtenni.
Keressük meg az erőforráscsoportban a virtuális gép erőforrást (linux-monitor vagy windows-monitor) és kattintsunk rá
A bal oldali panelon keressük meg a Beállítások > Alkalmazások és bővítmények elemet és kattintsunk rá
Itt kell látnunk az AMA elemet
Windows esetén: AzureMonitorWindowsAgent
Linux esetén: AzureMonitorLinuxAgent
Ha ez hiányzik, akkor nem fogjuk tudni gyűjteni a naplóbejegyzéseket és metrikákat.
Most pedig elérkezett a pillanat amire vártunk: központilag le tudjuk kérdezni a begyűjtött adatokat. Azokat tudjuk elemezni, vagy további feldolgozást végezhetünk rajuk. Nincs határ.
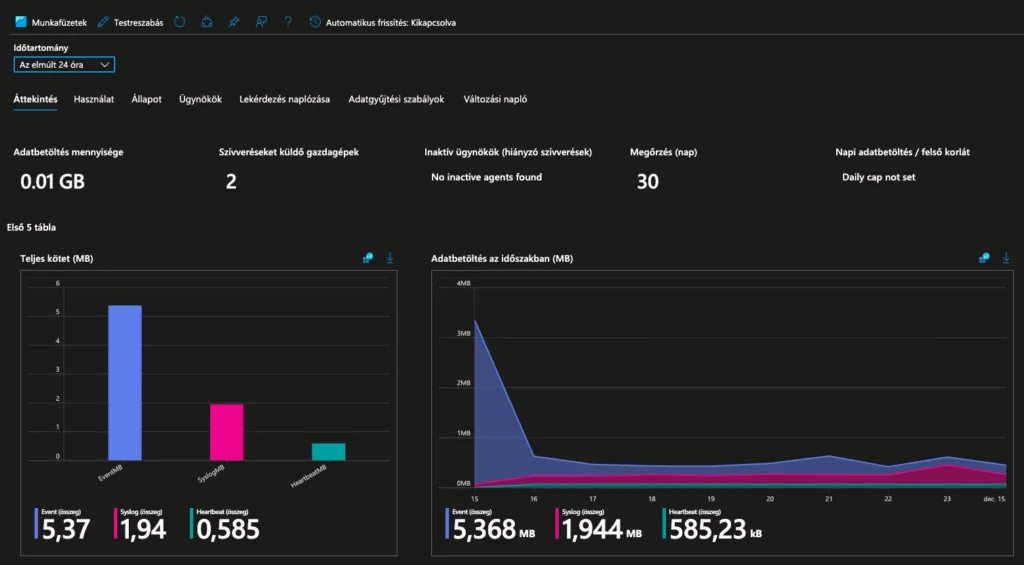
Elemzések áttekintése
Amint az adatok begyűjtése elindul, a LAW munkába lendül és rengeteg hasznos információt biztosít számunkra. Ebből jelenleg csak az alap elemzési diagrammot szeretném megmutatni.
Felül a keresőben keresd meg: „Monitorozás”, majd kattintsunk rá.
A bal oldali panelon keressük meg a Betekintések > Log Analytics-munkaterületek elemet és kattintsunk rá.
Felül válaszd ki a megfelelő Workspace-t
Majd kattints a nevére
Megnyílik az elemzési áttekintő ablak
Naplóbejegyzése a portálon
Most pedig megmutatom az ajtót a naplóbejegyzések keresésének végtelen univerzumába.
Felül a keresőben keresd meg: „Monitorozás”, majd kattintsunk rá.
A bal oldali panelon keressük meg a Betekintések > Log Analytics-munkaterületek elemet és kattintsunk rá.
Felül válaszd ki a megfelelő Workspace-t
Majd kattints a nevére
Megnyílik az elemzési áttekintő ablak
A bal oldali panelon keressük meg a Figyelés > Munküzetek elemet és kattintsunk rá.
Itt találsz előre elkészített elemet.
Mi most újat hozunk létre, mert az a legegyszerűbb. Kattints: „+ Új”
A megjelenő lapon a Log Analytics-munkaterület Naplók (Analytics) Lekérdezés rész a KQL query editor. Ide írhatod meg az egyedi lekérdezésedet, amit utána el is menthetsz.
Illeszd me az alábbit, majd kattints a Lekérdezés futtatása gombra
// Windows Információs bejegyzések az elmúlt 1 órából
Event
| where TimeGenerated > ago(1h)
| where EventLevelName in ("Information")
| project TimeGenerated, Computer, EventLog, EventLevelName, RenderedDescription
| order by TimeGenerated desc
Ezt is próbáld ki:
// Linux auth események (bejelentkezések)
Syslog
| where TimeGenerated > ago(3h)
| where Facility == "auth" or Facility == "authpriv"
| project TimeGenerated, Computer, SeverityLevel, SyslogMessage
| order by TimeGenerated desc
És egyéb példák:
// Összes Windows Event az elmúlt 24 órából
Event
| where TimeGenerated > ago(24h)
| summarize count() by EventLog, EventLevelName
| order by count_ desc
// Windows hibák és figyelmeztetések
Event
| where TimeGenerated > ago(1h)
| where EventLevelName in ("Error", "Warning")
| project TimeGenerated, Computer, EventLog, EventLevelName, RenderedDescription
| order by TimeGenerated desc
// Linux syslog események
Syslog
| where TimeGenerated > ago(24h)
| summarize count() by Facility, SeverityLevel
| order by count_ desc
// Linux auth események (bejelentkezések)
Syslog
| where TimeGenerated > ago(24h)
| where Facility == "auth" or Facility == "authpriv"
| project TimeGenerated, Computer, SeverityLevel, SyslogMessage
| order by TimeGenerated desc
// Adott VM összes logja
Event
| where Computer == "linux-monitor"
| where TimeGenerated > ago(1h)
| order by TimeGenerated desc
Tippek
Ezzel végeztünk is. Ugye, hogy milyen sima volt?
Fontos: A KQL lekérdezéseket érdemes tanulmányozni, hogy elérd a kívánt eredményt.
Problémák elkerülése:
Amikor eldöntjük, mit gyűjtünk, rengeteg lehetőség van. Én azt javaslom, hogy tudatosan tervezzük meg mire is van igazán szükségünk, mert könnyű elkövetni az alábbi hibákat:
túl sok adat gyűjtése feleslegesen,
nem egyértelmű, hogy egy VM miért nem küld naplót,
Linux és Windows eltérő logikájának keverése (ezért sem optimális a jelenlegi beállításunk),
vagy egyszerűen az, hogy nem világos, mi történik a háttérben.
Költségoptimalizálás tippek:
Ne gyűjts mindent „Information” szinten, csak Warning és felette
Állíts be data retention limitet (30 nap alap, növelhető)
Használj data collection rule transformations-t a felesleges adatok szűrésére
Összefoglalás
Együtt beállítottunk egy teljes körű log gyűjtési megoldást Azure Monitor segítségével. Létrehoztunk egy Log Analytics Workspace-t, ami központi tárolóként szolgál minden begyűjtött adatnak.
Konfiguráltunk egy Data Collection Rule-t, amely Windows Event Logs és Linux Syslog forrásokból gyűjti az eseményeket, és hozzárendeltük a monitorozni kívánt VM-ekhez.
Az Azure Monitor Agent automatikusan települt a gépekre, így azok azonnal elkezdték küldeni az adatokat. A begyűjtött logokat a Log Analytics Workspace Naplók menüpontjában KQL lekérdezésekkel tudjuk elemezni és keresni.
Ha most ismerkedsz az Azure Monitoring-al, vagy eddig csak „kattontgattad”, mert muszáj volt, akkor ez a cikk neked szólt.
Rövid gyakorlás után biztos vagyok benne, hogy hamar összeáll a kép.
Nem rég fejeztem be egy videós képzési anyagot a Mentor Klub részére, ahol a résztvevők megismerhették az Azure-on belül elérhető OpenAI megoldásokat. Ennek részeként bemutattam az Azure OpenAI Studio felületét is, ami valójában az Azure AI Foundry egyik funkcionális eleme. Mindkettőt elég gyakran használom, különböző projektekben és különböző célokra. Hogy éppen melyik a jobb egy adott feladathoz, azt többnyire az aktuális projekt igényei döntik el.
A Microsoft azonban az elmúlt hónapokban egy olyan változtatást indított el, amely alapjaiban alakítja át azt, ahogyan eddig AI-megoldásokat építettünk Azure-ban. A Foundry platform fokozatosan átveszi az Azure OpenAI Studio szerepét, kiszélesítve annak lehetőségeit és egységesítve az AI-fejlesztés teljes ökoszisztémáját.
Mi volt az Azure OpenAI Studio szerepe
A Microsoft az Azure OpenAI Studio felületet arra hozta létre, hogy egyszerű legyen kipróbálni és tesztelni az Azure által kínált OpenAI modelleket. A felület segítségével lehetett:
modelleket kipróbálni egy játszótérben
finomhangolt modelleket kezelni
API-végpontokat és kulcsokat elérni
kötegelt feldolgozást és tárolt befejezéseket használni
értékeléseket futtatni
és még sok hasznos AI programozást segítő funkciót.
Az Azure OpenAI Studio azonban alapvetően egy modelltípusra, az Azure által értékesített OpenAI modellekre épült. Ez a projektjeim során is érezhető volt: ha más modellgyártó megoldását szerettem volna használni, akkor azt külön kellett integrálni vagy külső szolgáltatásból kellett elérni.
Ez az a pont, ahol a Foundry teljesen más szemléletet hoz.
Mit kínál a Microsoft Foundry?
A Microsoft Foundry egy egységes AI-platform, amely több modellszolgáltatót, több szolgáltatást és teljes életciklus-kezelést egy felületre hoz. A Microsoft Learn dokumentum így fogalmaz: a Foundry egy nagyvállalati szintű platform, amely ügynököket, modelleket és fejlesztői eszközöket egy helyen kezel, kiegészítve beépített felügyeleti, monitorozási és értékelési képességekkel .
A legfontosabb különbségek a következők.
Széles modellkínálat
Az Azure OpenAI-val szemben a Foundry nem korlátozódik egyetlen gyártóra. Elérhetők többek között:
Azure OpenAI modellek
DeepSeek
Meta
Mistral
xAI
Black Forest Labs
Stability, Cohere és más közösségi modellek
És ez még csak a jéghegy csúcsa.
Ügynökszolgáltatás és többügynökös alkalmazások (AgenticAI)
A Foundry API kifejezetten ügynökalapú fejlesztéshez készült, ahol több modell és komponens együttműködésére van szükség.
Egységes API különböző modellekhez
A Foundry egységes API-t biztosít, így a fejlesztőnek nem kell minden gyártó logikáját külön megtanulnia.
Vállalati funkciók beépítve
A Foundry felületén eleve jelen vannak:
nyomkövetés
monitorozás
értékelések
integrált RBAC és szabályzatok
hálózati és biztonsági beállítások
Gyakorlatilag, minden ami a nagyvállalati és biztonságos működéshez elengedhetetlen.
Projektalapú működés
A Foundry projektek olyan elkülönített munkaterületek, amelyekhez külön hozzáférés, külön adatkészletek és külön tároló tartozik. Így egy projektben lehet modelleket, ügynököket, fájlokat és indexeket is kezelni anélkül, hogy más projektekhez keverednének.
Amikor még csak Azure OpenAI-val dolgoztam, előfordult, hogy egy ügyfél Meta vagy Mistral modellt szeretett volna kipróbálni összehasonlításként. Ezt külön rendszerben kellett megoldani. A Foundry megjelenésével ugyanabban a projektben elérhetővé vált:
GPT-típusú modell
Mistral
Meta
DeepSeek
és még sok más
Egy projekten belül egyszerre lehet kísérletezni, mérni és értékelni különböző modellek viselkedését.
Mit jelent ez a felhőben dolgozó szakembereknek
A Foundry nem egyszerűen egy új kezelőfelület. A gyakorlati előnyei:
Egységes platform, kevesebb különálló eszköz
Könnyebb modellválasztás és modellváltás
Átláthatóbb üzemeltetés, biztonság és hálózatkezelés
Bővíthető modellkínálat
Konszolidált fejlesztői élmény és API
A dokumentáció többször hangsúlyozza, hogy a Foundry nemcsak kísérletezésre, hanem üzleti szintű, gyártásra kész alkalmazásokra is alkalmas. Ez a mindennapi munkában is érezhető.
Miért előnyös ez a vállalatoknak
A vállalatok számára a Foundry több szempontból stratégiai előrelépés:
Egységes biztonsági és megfelelőségi keretrendszer
Több modellgyártó támogatása egy platformon
Könnyebb üzemeltetési kontroll
Gyorsabb AI-bevezetési ciklus
Rugalmasabb fejlesztési irányok
A Foundry megjelenésével a cégek már nem csak egyetlen modellre vagy ökoszisztémára építenek, hanem több szolgáltató képességét is bevonhatják anélkül, hogy töredezett lenne a rendszer.
Tulajdonság
Azure OpenAI
Foundry
Közvetlenül az Azure által értékesített modellek
Csak Azure OpenAI
Azure OpenAI, Black Forest Labs, DeepSeek, Meta, xAI, Mistral, Microsoft
Partner és Közösség modellek a Marketplace-en keresztül – Stability, Cohere stb.
✅
Azure OpenAI API (köteg, tárolt befejezések, finomhangolás, értékelés stb.)
Az Azure OpenAI Studio jó kiindulási pont volt az Azure AI-képességeinek megismerésére és modellek kipróbálására.
A Microsoft Foundry azonban túlnő ezen a szerepen: egységes platformot biztosít a teljes AI-fejlesztési életciklushoz, több modellgyártóval és kiterjesztett vállalati funkciókkal.
A Microsoft nem leváltja az Azure OpenAI-t, hanem beépíti egy nagyobb, átfogóbb rendszerbe. Ez a lépés hosszú távon kiszámíthatóbb, hatékonyabb és sokkal rugalmasabb AI-fejlesztést tesz lehetővé.
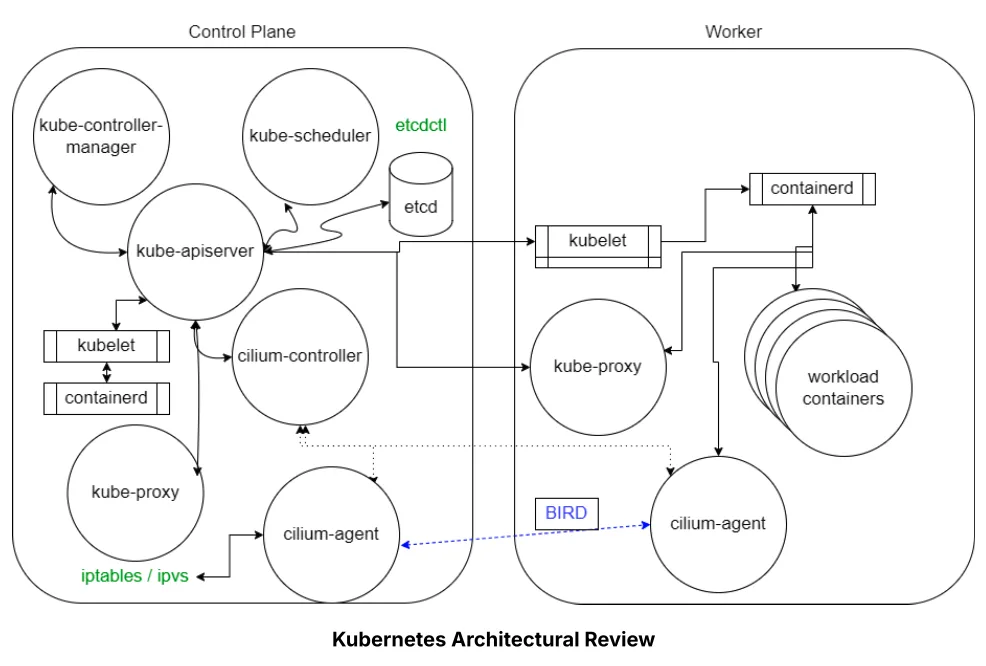
Ha elég időt töltünk Kubernetes környezetben, egy ponton elkerülhetetlenül rájövünk, hogy a sok látható elem – kapszulák, szolgáltatások, vezérlők, automatizmusok – mögött van valami közös, csendben működő hatalom. Valami, ami minden változtatást, minden lekérdezést, minden döntést összeköt. Ez az API.
Egy láthatatlan infrastruktúra-háló, amely összefogja a fürt egészét, irányítja az adatáramlást, és biztosítja, hogy a rendszer minden része ugyanazt a nyelvet beszélje. Amikor ezt megértjük, nem csak használjuk a Kubernetest – elkezdjük igazán érteni.
Az API a Kubernetes motorja
A Kubernetes teljes architektúrája API-alapú. A központi komponens, a kube-apiserver, felel azért, hogy a fürtben futó összes komponens — a vezérlősík elemei és a külső kliensek — megbízhatóan kommunikáljanak egymással. Minden, amit a kubectl paranccsal végzünk, valójában egy REST-alapú API hívás, amely HTTP metódusokat (GET, POST, DELETE stb.) használ.
Aki szeretne mélyebben belelátni a működésbe, kipróbálhatja a curl-alapú lekérdezéseket is. A megfelelő tanúsítványok birtokában például így kérhetjük le az aktuális kapszulák (Pods) listáját:
Ezek a hívások teszik lehetővé, hogy akár automatizált rendszerek, akár fejlesztői eszközök biztonságosan kapcsolódjanak a Kubernetes API-hoz.
A RESTful szemlélet ereje
A Kubernetes API RESTful, vagyis állapotmentes és erőforrás-orientált. Minden objektum – például egy kapszula vagy egy szolgáltatás – egy konkrét API-végpont (endpoint) mögött található. A /api/v1/pods például a kapszulákhoz tartozó végpont, ahol a GET lekérdezés listát ad, a POST pedig új kapszulát hoz létre. Ez a megközelítés lehetővé teszi, hogy a Kubernetes könnyen integrálható legyen bármely modern fejlesztési vagy üzemeltetési eszközzel.
Jogosultságok és hozzáférés-ellenőrzés
A Kubernetes egyik legfontosabb biztonsági alapelve, hogy minden felhasználó csak azt tehessen meg, amire jogosultsága van. Ezt az RBAC (Role-Based Access Control) rendszer szabályozza, de már a gyakorlati munkához is jól jön, ha gyorsan ellenőrizni tudjuk, mire van engedélyünk.
A kubectl auth can-i parancs pontosan erre való:
kubectl auth can-i create deployments
yes
kubectl auth can-i create deployments --as robert
no
kubectl auth can-i create deployments --as robert --namespace developer
yes
A fenti példában látható, hogy a „robert” nevű felhasználó csak a developer névtérben (namespace) hozhat létre új Deployment objektumokat.
A Kubernetes három fő API-t biztosít az engedélyek ellenőrzésére:
API típus
Funkció
SelfSubjectAccessReview
Ellenőrzi, hogy az aktuális felhasználó végrehajthat-e egy adott műveletet.
LocalSubjectAccessReview
Ugyanez, de egy konkrét névtérre korlátozva.
SelfSubjectRulesReview
Megmutatja, milyen műveleteket hajthat végre a felhasználó egy névtérben.
Ez a felépítés biztosítja, hogy a jogosultságok átláthatóak és ellenőrizhetőek legyenek, ami különösen fontos nagyvállalati környezetben.
Optimista konkurencia – amikor több kéz nyúl ugyanahhoz az objektumhoz
A Kubernetes nem zárja le az erőforrásokat szerkesztés közben. Ehelyett az úgynevezett optimista konkurenciakezelést (Optimistic Concurrency) használja, amely a resourceVersion értékre támaszkodik.
Amikor valaki módosít egy objektumot, a rendszer ellenőrzi, hogy a resourceVersion azóta megváltozott-e. Ha igen, 409 CONFLICT hibát kapunk, ami jelzi, hogy az objektumot időközben más is frissítette. Ez a módszer különösen fontos nagy fürtök esetén, ahol több automatizált folyamat és emberi adminisztrátor is dolgozik egyszerre ugyanazokon az erőforrásokon.
A resourceVersion értéket az etcd adatbázis kezeli, és egyedileg azonosítja az adott objektumot a névtér és a típus alapján. A lekérdezések (GET, WATCH) nem változtatják ezt az értéket, csak a módosítások (UPDATE, PATCH, DELETE).
Annotációk – amikor a metaadat többet mond, mint ezer címke
A Kubernetes-ben a címkék (labels) segítségével szűrhetünk és csoportosíthatunk objektumokat. Az annotációk (annotations) viszont nem keresésre, hanem metaadatok tárolására szolgálnak. Ezek lehetnek időbélyegek, kapcsolódó objektumokra mutató hivatkozások, vagy akár az adott erőforrásért felelős fejlesztő e-mail-címe.
Az annotációk kulcs–érték párok formájában tárolódnak, és ember számára is olvashatóak. Ez különösen hasznos lehet integrációs vagy üzemeltetési eszközök számára, mivel így minden releváns információ közvetlenül az objektumhoz kapcsolható.
Példa annotációk létrehozására és módosítására:
kubectl annotate pods --all description='Production Pods' -n prod
kubectl annotate --overwrite pod webpod description='Old Production Pod' -n prod
kubectl annotate -n prod pod webpod description-
Az annotációk segítségével tehát kontextust adhatunk az erőforrásainkhoz – anélkül, hogy az API működését befolyásolnánk.
Összegzés
A Kubernetes API nem csupán egy technikai interfész, hanem a platform idegrendszere. A RESTful megközelítés, a precíz hozzáférés-kezelés, az optimista konkurencia és a rugalmas annotációk mind azt a célt szolgálják, hogy a rendszergazdák és fejlesztők hatékonyan, biztonságosan és átláthatóan kezeljék a komplex felhős környezeteket.
Aki megérti az API működését, valójában a Kubernetes egészét érti meg. És bár a kapszulák futtatása látványosabbnak tűnhet, az igazi varázslat mégis itt, az API hívások szintjén történik.
Több tucat cikket olvashattatok tőlem a felhőszolgáltatások alapfogalmairól, és arról is, hogyan kommunikálnak egymással a különböző rendszerek. Ebben a cikkben egy olyan területet hozok közelebb, amely látszólag egyszerűnek tűnik, mégis meglepően sok félreértés forrása.
Egy saját történettel kezdem: amikor először készítettem több rétegű felhős alkalmazást, órákon át kerestem, miért nem érhető el a szolgáltatásom. A hiba mindössze annyi volt, hogy egy helytelenül megadott URL miatt teljesen más címre irányítottam a kéréseket. Ez volt az első alkalom, amikor igazán megértettem, mennyire fontos a pontos URL-használat.
A felhőben dolgozó szakemberek nap mint nap találkoznak API-végpontokkal, szolgáltatási URL-ekkel, konténerek belső hivatkozásaival és különböző load balancer címsémákkal. Ezek mind egy közös alapelvre épülnek: az URL szerkezetére. Ahhoz, hogy valaki magabiztosan mozogjon bármelyik felhős platformon, elengedhetetlen, hogy pontosan értse, mit is jelent egy URL, és hogyan működik.
Mi az az URL és miért létezik?
Az URL (Uniform Resource Locator) egy szabványos formátum, amely meghatározza, hogy az interneten vagy egy privát hálózaton belül hol található egy erőforrás, és milyen protokollon keresztül lehet elérni. A weboldalak címe, egy API végpontja, egy belső szolgáltatás címe: mind URL.
Példa: https://api.evolvia.hu/gyakorlat/42
Ez nem egy véletlenszerű karakterhalmaz, hanem precízen meghatározott elemekből áll.
Egy URL szerkezete
Egy tipikus URL több kötelező és opcionális részből épül fel:
https://cloudmentor.hu:443/eleresi/ut/?lekerdezes=ertek#szekcio
└───┬──┘└─────┬──────┘└─┬─┘└────┬────┘└───────┬───────┘└──┬───┘
Protokoll Domain Port Útvonal Query Fragment
Az egyes részek szerepe:
Protokoll Meghatározza, milyen szabályrendszerrel történik a kommunikáció. Leggyakoribb: http, https
Domain vagy IP-cím A cím, amelyhez a kérés érkezik. Példák: example.com 192.168.1.10 localhost – saját gépre mutat
Port A szerveren futó adott szolgáltatás eléréséhez szükséges. HTTP: 80 HTTPS: 443 API-k esetén gyakran egyedi, például: http://localhost:8080
Útvonal (Path) Az erőforrás helye a szerveren belül. Példa: /api/v1/orders
Query paraméterek Opcionális adatok a kéréshez kapcsolódóan. Példa: ?sort=asc&page=2
Fragment Oldalon belüli hivatkozás, például egy szakaszra ugráshoz.
Gyakori URL-típusok és példák
1. Helyi fejlesztés: localhost http://localhost:3000/api/test Ez a saját gépre mutat, amit fejlesztők naponta használnak alkalmazások és API-k tesztelésére.
2. IP-cím alapú elérés http://10.0.0.5:8080/health Jellemző konténerek, virtuális gépek vagy belső hálózati szolgáltatások esetén.
3. Felhős API-végpontok https://myapp.azurewebsites.net/api/login https://abc123.execute-api.eu-west-1.amazonaws.com/prod/items Ezek minden felhőszolgáltató esetén hasonló logikát követnek.
4. Belső szolgáltatás hivatkozása Kubernetesben http://redis-master.default.svc.cluster.local:6379 Ez jól mutatja, hogy az URL nem csak internetes cím lehet, hanem klaszteren belüli erőforrás is.
Miért fontos ez a felhőben dolgozó szakemberek számára?
Egy felhőmérnök, DevOps vagy SRE munkája szinte minden nap érinti az URL-eket. API-k hívása, szolgáltatások összekapcsolása, webhookok beállítása, konténerek közötti kommunikáció, gateway routerek konfigurálása: mind olyan feladat, ahol egy hibás karakter is működésképtelenné tehet rendszereket.
Pontosan értve az URL szerkezetét:
gyorsabban lehet hibát keresni
megbízhatóbban lehet szolgáltatásokat összekötni
tisztábban értelmezhetők logok és monitoring adatok
könnyebbé válik a skálázható rendszertervezés
A felhőben minden kommunikáció URL-ekre épül. Aki érti az alapokat, stabil alapot kap a magasabb szintű architektúrákhoz.
Leggyakoribb hibák kezdők körében
Rosszul megadott protokoll: http helyett https
Port kihagyása olyan szolgáltatásnál, ahol nem alapértelmezett (alapértelmezett portok például: 80 – HTTP, 443 – HTTPS)
Query paraméterek helytelen formázása
Localhost és külső elérési címek összekeverése
Privát IP és publikus IP nem megfelelő használata
Ezek mind egyszerű hibák, mégis órákat vehetnek el a hibakeresésből.
HTTP és HTTPS közötti különbség
A webes kommunikáció két leggyakrabban használt protokollja a HTTP és a HTTPS. Bár a két rövidítés csak egyetlen betűben tér el, a mögöttük lévő technológiai különbség alapvetően meghatározza a biztonságot, a hitelesítést és az adatok védelmét. Felhőben dolgozó szakembereknek ez kiemelten fontos, hiszen az alkalmazások, API-k és háttérszolgáltatások nagy része érzékeny adatokat kezel.
HTTP – titkosítás nélküli kommunikáció
A HTTP (Hypertext Transfer Protocol) az alapvető webes protokoll, amely szabályozza, hogyan kommunikál a kliens és a szerver. A HTTP-ben az adatok titkosítatlan formában utaznak, vagyis bárki, aki valamilyen módon hozzáfér a hálózati forgalomhoz, elméletben képes lehet kiolvasni a küldött vagy fogadott tartalmakat. Ez ma már csak fejlesztési, belső hálózati vagy nagyon specifikus esetekben elfogadható.
HTTPS – titkosított és hitelesített kapcsolat
A HTTPS (HTTP Secure) ugyanezt a kommunikációs modellt használja, de kiegészül TLS-alapú titkosítással. A TLS (Transport Layer Security) gondoskodik arról, hogy a kliens és a szerver között áthaladó adatok ne legyenek olvashatók harmadik fél számára. Emellett a szerver hitelesítése is megtörténik tanúsítványok segítségével.
Ez azt jelenti, hogy:
a forgalom titkosított
a kliens meggyőződik arról, hogy valóban a megfelelő szerverhez csatlakozik
az adatok nem módosíthatók észrevétlenül útközben
Miért számít ez a felhőben?
A modern felhőalapú rendszerekben elképzelhetetlen HTTPS nélkül dolgozni. API-k, belső menedzsment felületek, mikroszolgáltatások közötti kommunikáció: mind olyan elemek, ahol a biztonság és az integritás prioritás.
A HTTPS használata azért kritikus:
védi a hitelesítési adatokat
megakadályozza az adatok lehallgatását
biztosítja, hogy a kliens valós szolgáltatással kommunikál
megfelel biztonsági előírásoknak és iparági szabványoknak
Gyakorlati különbségek a fejlesztő szemszögéből
A HTTPS URL-ek https:// előtaggal kezdődnek, a HTTP pedig http:// formát használ
A HTTPS alapértelmezett portja 443, míg a HTTP-é 80
HTTPS esetén szükség van tanúsítványra, amely lehet publikusan hitelesített vagy saját aláírású
Összefoglalás
Az URL nem pusztán egy webcím. Ez a modern internet egyik legfontosabb építőköve. A felhőben dolgozó szakemberek számára pedig különösen lényeges alapelem, hiszen minden szolgáltatás, API, konténer és infrastruktúra modul ezen keresztül kommunikál. Aki tisztában van az URL felépítésével és működésével, sokkal tudatosabban és gyorsabban fogja megérteni a felhős rendszerek belső működését.
Amikor először léptél be a felhő világába – akár csak kísérletezőként –, elképzelted talán, hogy a virtuális gépeken minden „mindent a semmiből” kezdünk, és amikor ez a gép eltűnik, minden adat is vele. Nos, az Amazon Elastic Compute Cloud (EC2) kezdeti időszakában ez így is volt sokszor: az „instance store” típusú tárolók a virtuális gép életciklusához kötődtek.
Ha korábban már foglalkoztál azzal, hogy naplókat, metrikákat vagy adatokat felhőben kell megőrizni, akkor az EBS adja ehhez az alapot: megbízható, gyors és rugalmas tároló-eszköz. Most nézzük meg részletesen – kezdők számára is – mit jelent az EBS volume, mik az előnyei, mire használható és milyen korlátai vannak.
Mi az EBS Volume?
Az EBS volume egy virtuális blokkszintű tárolóegység, amelyet az Amazon EBS-en belül hozol létre, és amelyet egy EC2 példányhoz csatolhatsz, mintha egy fizikai merevlemezt adnál hozzá. Fő jellemzői:
Az EBS volume az EC2 példánytól függetlenül is megőrzi az adatokat – tehát a tárolt információ nem vész el, ha a gépet leállítod vagy újraindítod.
Minden volume egy adott Availability Zone-hoz tartozik, és csak ott használható.
A felhasználó formázhatja, mountolhatja, olvashat és írhat rá, ugyanúgy, mint egy helyi meghajtóra.
Virtuális blokkszintű tárolóegység
Olyan felhőben létrehozott háttértár, amely az operációs rendszer számára úgy viselkedik, mint egy hagyományos merevlemez. Az adatokat blokkokra osztva tárolja és kezeli, így az alkalmazások közvetlenül olvashatják vagy írhatják ezeket a blokkokat. A „virtuális” jelző azt jelenti, hogy nem egy konkrét fizikai lemezen, hanem a szolgáltató (például az AWS) elosztott tárolórendszerében található az adat — a felhasználó számára mégis egyetlen logikai meghajtónak látszik.
Hogyan működik a háttérben?
Bár az EBS-t úgy látjuk, mintha egy „saját” merevlemezünk lenne a felhőben, valójában nem egyetlen fizikai lemezről van szó. Az EBS mögött az Amazon belső, elosztott tárolórendszere dolgozik, amely több fizikai háttértáron, különböző szervereken tárolja és replikálja az adatokat. Ez a felhasználó számára átlátszó: a blokkeszköz úgy viselkedik, mint egy hagyományos disk, de a valóságban több háttértár és redundáns adatmásolat biztosítja az állandóságot és a teljesítményt. Ez a megoldás teszi lehetővé, hogy:
az adatok automatikusan védve legyenek hardverhiba esetén,
egyetlen lemezhiba ne okozzon adatvesztést,
az EBS skálázni tudja a háttérkapacitást emberi beavatkozás nélkül.
Tehát az EBS nem egy konkrét „disk”, hanem egy blokkszintű, hálózaton keresztül elérhető tárolószolgáltatás, amelyet az AWS menedzsel helyetted.
Erősségek és lehetőségek
Megbízhatóság és tartósság
Az EBS automatikusan több alrendszer között replikálja az adatokat, így egy hardverhiba sem okoz adatvesztést. Ha az EC2 példány leáll, az EBS adatai akkor is megmaradnak (amennyiben a beállítás ezt engedi).
Skálázhatóság és rugalmasság
Ennek egyik legnagyobb előnye, hogy a méretét, típusát vagy IOPS-értékét akár működés közben is módosíthatod. Az AWS több típusú EBS volument kínál: SSD-alapú (pl. gp2, gp3, io1, io2) és HDD-alapú (pl. st1, sc1) változatokat. Az előbbiek gyors, tranzakciós feladatokra, az utóbbiak nagy adatátviteli igényű munkákra ideálisak.
Biztonság és mentés
Az EBS snapshot segítségével pillanatképet készíthetsz a volume-ról, amelyet később visszaállíthatsz, vagy akár más régióba is átmásolhatsz. Támogatja a titkosítást is: a KMS-kulcsokkal titkosíthatók a volume-ok és snapshotok, így az adatok védettek mind tárolás, mind átvitel közben.
Típusok
Az Amazon EBS (Elastic Block Store) többféle volume típust kínál, amelyek különböző teljesítmény- és költségigényekhez igazodnak. Ezeket alapvetően két fő kategóriába soroljuk: SSD-alapú (alacsony késleltetésű, tranzakciós műveletekre) és HDD-alapú (nagy áteresztésű, szekvenciális feldolgozásra) kötetekre.
SSD-alapú volume-ok (alacsony késleltetésű, gyors műveletekhez)
Ezek ideálisak operációs rendszerekhez, adatbázisokhoz, webalkalmazásokhoz és más tranzakciós jellegű munkákhoz.
Típus
Jellemző
Ideális felhasználás
Teljesítmény / IOPS
Árszint
gp3(General Purpose SSD, új generáció)
Alapértelmezett típus. Fix áron magasabb teljesítményt ad, mint a gp2.
Általános célú alkalmazások, web- és adatbázisszerverek.
Olyan rendszerek, ahol nem kritikus a skálázhatóság.
3 IOPS / GB (max 16 000 IOPS)
Közepes
io1(Provisioned IOPS SSD)
Nagy teljesítmény, garantált IOPS.
Kritikus adatbázisok, pl. Oracle, SAP HANA.
100 – 64 000 IOPS
Magas
io2(Provisioned IOPS SSD, új generáció)
Jobb tartósság (99,999%) és magasabb IOPS-arány.
Nagyvállalati adatbázisok, alacsony késleltetést igénylő alkalmazások.
100 – 256 000 IOPS
Magas
HDD-alapú volume-ok (nagy adatátvitel, olcsóbb)
Ezeket főként nagy mennyiségű, szekvenciális adat feldolgozására használják, például logok, biztonsági mentések, adatarchívumok esetén.
Típus
Jellemző
Ideális felhasználás
Átviteli sebesség
Árszint
st1(Throughput Optimized HDD)
Nagy áteresztés, költséghatékony tárolás.
Nagy adatfolyamot kezelő rendszerek (pl. log-elemzés, Big Data).
Max 500 MB/s
Alacsony
sc1(Cold HDD)
Archív, ritkán elérhető adatokhoz.
Biztonsági mentések, ritka hozzáférésű adatok.
Max 250 MB/s
Legolcsóbb
Összehasonlítás röviden
Kategória
Típusok
Teljesítmény
Költség
Tartósság
Fő cél
SSD
gp3, gp2, io1, io2
Nagyon gyors
Közepes–magas
99,8–99,999%
Adatbázis, OS, tranzakciók
HDD
st1, sc1
Mérsékelt
Alacsony
99,8%
Archívum, log, backup
Egyszerű példák
Webalkalmazás: van egy EC2-n futó weboldalad, amely adatbázist használ. Külön EBS volument csatolsz az adatbázishoz, így az adatok nem vesznek el akkor sem, ha a példányt újratelepíted.
Adatfeldolgozás: egy log-gyűjtő rendszer nagy mennyiségű adatot olvas és ír. Ilyenkor érdemes nagy áteresztésű, HDD-alapú (pl. st1) EBS-t választani.
Szolgáltatási szint (SLA)
Az AWS az EBS-re 99,999%-os tartóssági és 99,99%-os rendelkezésre állási szintet vállal. Ez a gyakorlatban azt jelenti, hogy évente mindössze néhány percnyi szolgáltatáskiesés valószínű. A tartóssági garancia kifejezetten magas: az AWS belső infrastruktúrája több adatmásolatot tart, így az adatok elvesztésének esélye rendkívül alacsony.
Ugyanakkor ez nem jelenti azt, hogy nincs szükség mentésre – az AWS maga is javasolja a rendszeres snapshot-készítést, hiszen az SLA csak a szolgáltatás elérhetőségére és megbízhatóságára, nem pedig az emberi hibákból eredő adatvesztésre vonatkozik.
Hogyan segíti a cégeket és felhasználókat
Gyorsan növekvő szoftvercég az EBS-t használhatja skálázható háttértárként: ha nő az ügyfélbázis, a volume-ot egyszerűen bővíthetik vagy nagyobb teljesítményűre cserélhetik, leállás nélkül.
Egy startup az alacsonyabb árú, gp3 típusú volume-val indíthatja el alkalmazását, így kezdetben nem kell túlfizetnie a tárolásért.
Kisvállalkozás, amely webáruházat működtet az AWS-en, EBS-t használhat a vásárlói adatok és képek biztonságos, tartós tárolására.
Korlátok és megfontolások
Egy EBS volume csak abban az Availability Zone-ban használható, ahol létrejött.
A díjazás méret- és típusfüggő, és a lefoglalt kapacitás után fizetsz, nem a tényleges használat után.
A teljesítményt a választott volume-típus és az EC2 példány típusa együtt határozza meg.
Az EBS általában csak egy példányhoz csatolható; több géphez csak speciális beállításokkal.
Az adott régió kiesése esetén a volume is elérhetetlenné válhat, ezért érdemes snapshotokkal biztonsági mentést készíteni.
Összegzés
Az AWS EBS volume egy megbízható, tartós és skálázható blokktárolási megoldás, amely ideális választás virtuális gépekhez. Segítségével az adatok függetlenek maradnak az EC2 példány életciklusától, könnyen bővíthetők, és egyszerűen menthetők snapshotokkal.
Erősségei közé tartozik a stabilitás, a gyors adatkezelés, a rugalmas méretezhetőség és a titkosítási lehetőség. Ugyanakkor érdemes figyelni az elérhetőségi zónák korlátaira és a költségek optimalizálására. Ha a felhőben adatbázist, webalkalmazást vagy akár nagy adatfeldolgozó rendszert építesz, az EBS az egyik legfontosabb építőkockád lesz – megbízható, mint egy jó merevlemez, csak épp a felhőben.