AWS Interconnect: valódi kapcsolat a felhők között
Amikor valaki felhő alapú projektet tervez, általában csak egy szolgáltatóban gondolkozik. Ez a természetes irány, és nem is meglepő – egy rendszer, egy számla, minden egy helyen. Ez az általános trend.
Pedig aki alaposan ismeri az AWS-t, az Azure-t és a Google Cloud-ot, hamar rájön: mindegyiknek vannak erősségei, és mindegyiknek vannak gyengeségei. Ha valaki engem kérdezne, hogy mi lenne egy nagy, vállalati szintű megoldás tökéletes kivitelezése, azt mondanám: mindegyikből a legjobbat használjuk. Azonban ez sajnos a legtöbb esetben nem lehetséges.
Miért ragad be mindenki egyetlen szolgáltatónál?
A válasz általában nem technikai – hanem emberi. Aki egyszer megismerte az AWS konzolt, az ott érzi magát otthon. A csapat ott szerzett tapasztalatot, azzal kapcsolatban vannak a tanúsítványok, és az architektúra is arra épül. Váltani vagy párhuzamosan üzemeltetni látszólag bonyolultabb, drágább, és több kockázattal jár.
Ehhez jön hozzá a vendor lock-in jelensége. Az iparági ajánlás egyértelmű: kerüld el, maradj hordozható, ne függj egyetlen szolgáltatótól. A valóságban azonban ez szinte lehetetlen.
Minél mélyebbre ásol egy platform saját szolgáltatásaiban – saját adatbázisok, saját AI eszközök, saját hálózati megoldások – annál inkább benne vagy. És ha egyszer erre építed az architektúrát, a váltás költsége a legtöbb esetben meghaladja a maradás kényelmetlenségét. A nagy szolgáltatók pontosan tudják ezt, és az árazásuk is ezt tükrözi. Aki már látott hosszú távú enterprise szerződést egy nagy felhőszolgáltatóval, az tudja, miről beszélek.
A multicloud és a hybrid cloud megközelítés részben erre a problémára ad választ.
- A multicloud lényege egyszerű: nem egy szolgáltatóban gondolkozol, hanem oda teszed a munkaterhelést, ahol az adott feladatra a legjobb eszközök vannak. Az analitika mehet Google Cloud-ra, a gépi tanulási infrastruktúra AWS-re, a Microsoft-integrációk Azure-ra.
- A hybrid cloud pedig azt jelenti, hogy a saját adatközpontod és a felhő együtt dolgozik – nem vagy kénytelen mindent kiszervezni.
A valóságban persze ez sem ilyen egyszerű. Mert ha két felhő között adatot kell mozgatni, azonnal felmerül a kérdés: hogyan? A nyilvános interneten keresztül? Az lassabb, kiszámíthatatlanabb, és biztonsági szempontból sem ideális. Dedikált fizikai kapcsolattal? Az drága, lassan kivitelezhető, és komoly hálózati szaktudást igényel. Pontosan itt jön képbe az AWS Interconnect.
Mi az AWS Interconnect?
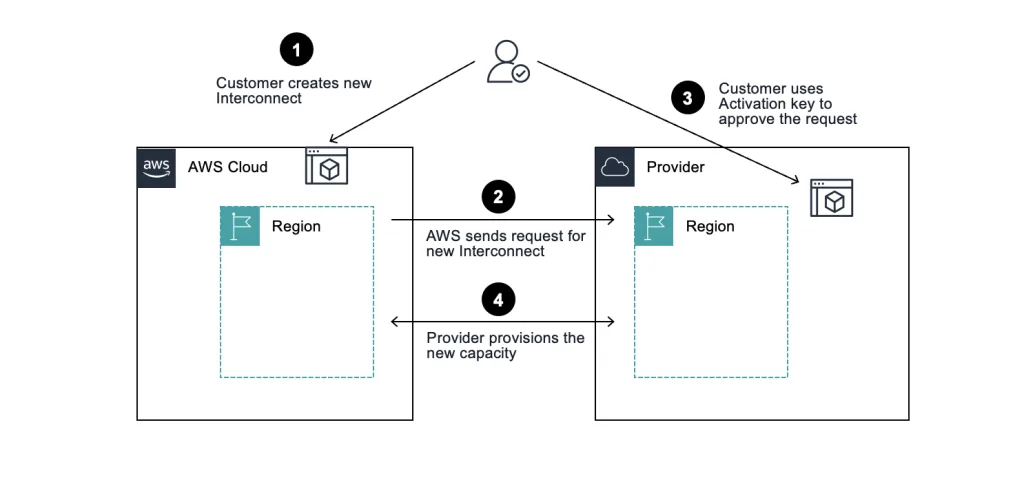
Az AWS Interconnect egy viszonylag friss szolgáltatás, amelyet pontosan erre a problémára terveztek. A hagyományos megközelítésben privát kapcsolatot létrehozni két felhő között fizikai routerek konfigurálását, BGP peering beállítást és cross-connect megrendeléseket jelentett – ez hónapokat és komoly szakértelmet igényelt. Az Interconnect ezt váltja ki.
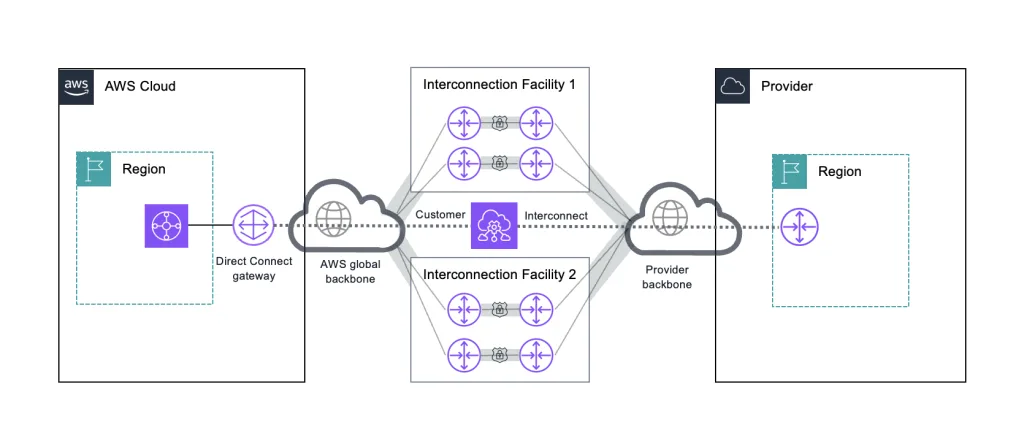
A folyamat leegyszerűsödik: kiválasztod a régiót, a szükséges sávszélességet és a szolgáltatót, az AWS és a partner pedig percek alatt előkészíti a kapcsolatot. A felhasználó mindebből egyetlen logikai objektumot lát a konzolban – a háttérben zajló redundáns infrastruktúra, a fizikai helyszínek és az MACsec titkosítás mind el van rejtve.
A szolgáltatásnak két arca van:
- A multicloud változat, amely AWS VPC-ket köt össze más felhőszolgáltatók hálózataival – jelenleg Google Cloud és Oracle Cloud Infrastructure oldalán érhető el, az Azure integráció még 2026 folyamán érkezik.
- Az úgynevezett last mile kapcsolat, amely irodákat, adatközpontokat és távoli helyszíneket köt az AWS-hez partnerek meglévő hálózatain keresztül.
Minden Interconnect legalább két fizikailag elkülönült helyszínen fut, független áramellátással és hálózattal, négy kapcsolatból álló redundáns modellben ECMP terheléselosztással. Ez enterprise szinten azt jelenti, hogy egyetlen eszköz vagy épület meghibásodása nem ejti ki a kapcsolatot.
Az ingyenes 500 Mbps – miért érdemes figyelni erre?
Az AWS most bevezette az ingyenes 500 Mbps-os multicloud Interconnect csomagot, amellyel a cégek tesztelhetik és élesben is futtathatják munkaterheléseiket anélkül, hogy az AWS oldalán bármilyen díjat fizetnének.
500 Mbps sávszélességgel havonta nagyjából 160 TB adat mozgatható – ez elegendő komoly multicloud munkaterhelések, adatreplikáció vagy hibrid alkalmazásarchitektúrák üzemeltetéséhez.
Fontos megérteni: az ingyenesség az AWS oldalára vonatkozik. A másik felhőszolgáltató saját maga határozza meg a díjszabást a saját infrastruktúrájára, ezért érdemes az ő árazásukat is megnézni az Interconnect létrehozása előtt. A szint régiónként és szolgáltatónként egy helyi Interconnect-re korlátozódik, és minden kapcsolat mellé egy Amazon CloudWatch Network Synthetic Monitor is jár külön díj nélkül – ez azt jelenti, hogy a latenciát és a csomagveszteséget folyamatosan monitorozhatod, riasztásokkal együtt.
Két valós eset, hogy érezzük a lényegét
- Adatreplikáció: Egy közepes méretű pénzügyi cégnél az analitikai platform Google BigQuery-n fut, a tranzakciós rendszer viszont AWS-en. A napi szinkron eddig vagy nyilvános interneten ment – lassabban, kevésbé stabilan – vagy drága dedikált kapcsolaton. Egy 500 Mbps-os ingyenes Interconnect-tel ez privát, alacsony késleltetésű csatornán zajlik, a monitoring pedig alapból adott.
- Szolgáltatás migráció: Egy vállalat Google Cloud-ról akar részben AWS-re költözni, de nem egyszerre. A két környezetnek hónapokig párhuzamosan kell futnia. Korábban ezt a hibrid fázist hálózatilag kompromisszumokkal kellett áthidalni. Most a 500 Mbps elegendő arra, hogy a migráció alatt a két oldal privát csatornán kommunikáljon, és csak akkor kell fizetős szintre lépni, ha a forgalom ezt megköveteli.
Mit érdemes tudni, mielőtt kipróbálod?
A régiós elérhetősége egyelőre korlátozott. Európában Frankfurt és London érhető el AWS–Google Cloud párban, ami a legtöbb európai vállalat számára releváns kiindulópont, de érdemes ellenőrizni, hogy a saját régiód szerepel-e a listán.
Ha az Azure az elsődleges másik felhőd, még türelem kell – az integráció az AWS közlése szerint 2026 folyamán érkezik, konkrét dátum nélkül.
Amit viszont biztosan mondani lehet: az ingyenes 500 Mbps-os szint vonzó belépési pont. Nem kell azonnal fizetős infrastruktúrában gondolkodni. Ki lehet próbálni, le lehet mérni, és csak akkor kell skálázni, ha a forgalom ezt megköveteli. Ha multicloud környezetben dolgozol, vagy csak tervezed, ez az a fajta ajánlat, amit nem érdemes figyelmen kívül hagyni.