Kubernetes API és hozzáférés: standard, mégis kiemelkedő
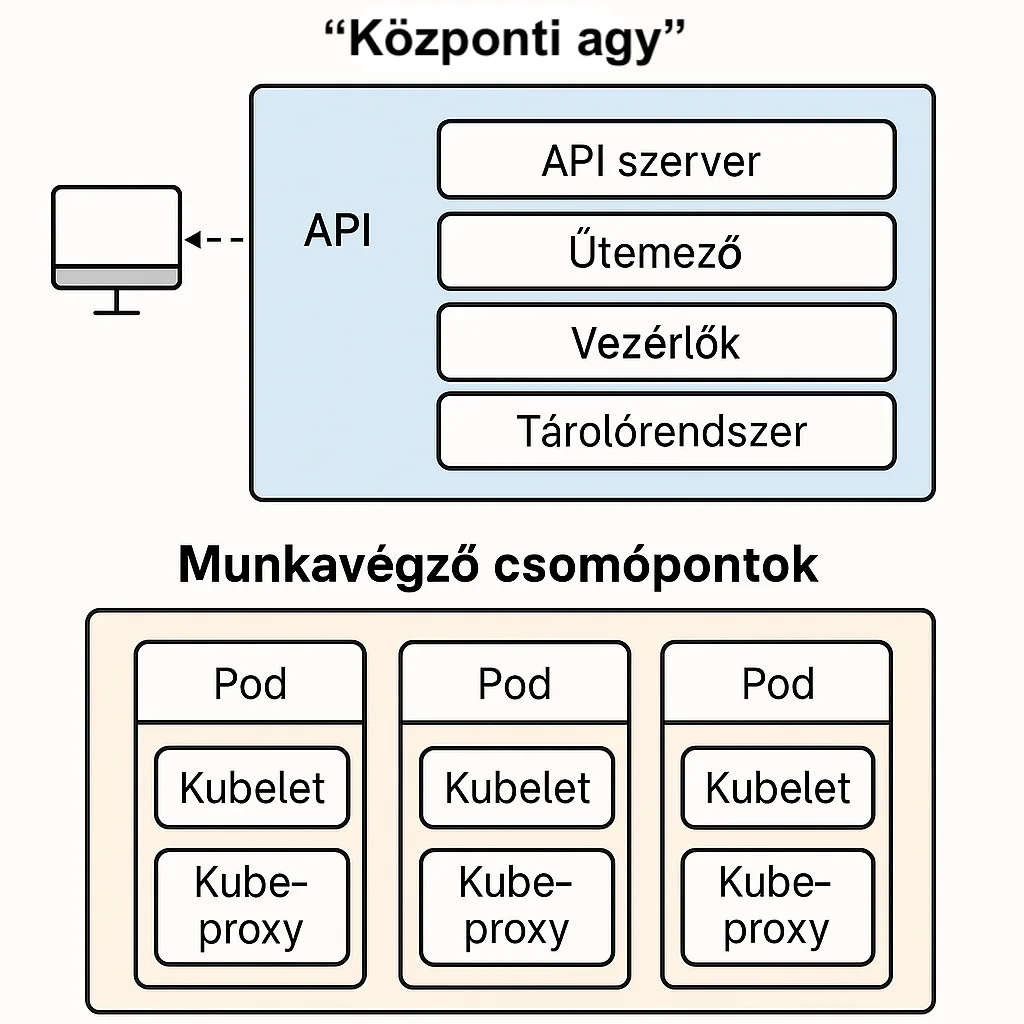
Lassan egy éve, hogy elkezdtem írni a Kubernetes-ről és annak architektúrájáról, a microservice-alapú rendszerek működéséről és arról, hogyan vált a Kubernetes a modern alkalmazásfejlesztés egyik alappillérévé. Beszéltünk a klaszterek működéséről, a podok életciklusáról, a vezérlőkomponensek szerepéről.
Ezeken felül van egy réteg, amely mindezt összefogja. Beszéltünk már erről is több szempontból, de úgy éreztem érdemes további figyelem ennek a központi elemnek. Mert enélkül sem a kubectl, sem a vezérlők, sem az automatizmusok nem működnének.
Ez a réteg a Kubernetes API.
Olyan ez, mint egy jól szervezett város központi ügyfélszolgálata. Bármit szeretnénk elintézni – új erőforrást létrehozni, meglévőt módosítani, állapotot lekérdezni –, mindent ezen keresztül teszünk. A Kubernetes valójában egy API-vezérelt rendszer. Minden művelet, amit végrehajtunk, végső soron egy API-hívás.
Nézzük meg, hogyan érhetők el az API-erőforrások, milyen speciális végpontok léteznek, hogyan kapcsolódik ehhez a Swagger és az OpenAPI, valamint mit jelent az API-k érettségi modellje.
API erőforrások és a kubectl szerepe
A Kubernetes által publikált összes API-erőforrás elérhető a kubectl eszközön keresztül. A parancs alapformátuma:
kubectl [command] [type] [name] [flag]A kubectl help parancs részletes információt ad az elérhető műveletekről és erőforrástípusokról.
A rendszer által elérhető API-erőforrások listája folyamatosan változhat, de az alapvető típusok közé tartoznak például:
- pods (po)
- services (svc)
- deployments (deploy)
- replicasets (rs)
- statefulsets
- daemonsets (ds)
- jobs
- cronjobs
- configmaps (cm)
- secrets
- namespaces (ns)
- nodes (no)
- persistentvolumes (pv)
- persistentvolumeclaims (pvc)
- resourcequotas (quota)
- limitranges (limits)
- networkpolicies (netpol)
- clusterroles
- clusterrolebindings
- roles
- rolebindings
- customresourcedefinition (crd)
Ez a lista jól mutatja, hogy a Kubernetes nem csupán podokat kezel. A klaszter működéséhez szükséges biztonsági, hálózati, tárolási és jogosultsági objektumok mind API-erőforrásként jelennek meg.
Fontos megérteni, hogy a kubectl valójában csak egy kliens az API server felé. Amikor például kiadjuk a következő parancsot:
kubectl get podsa háttérben egy HTTP GET kérés történik az API server irányába. A kubectl nem tart fenn külön adatbázist, nem cache-el erőforrásokat önállóan. Minden információ az API-n keresztül érkezik.
Ez a modell teszi lehetővé, hogy a Kubernetes teljesen deklaratív és automatizálható rendszer legyen. Ugyanazokat az API-hívásokat használhatja egy operátor, egy CI/CD pipeline vagy egy egybinárisos vezérlőalkalmazás is.
További API-műveletek erőforrásokon
Az alapvető REST műveleteken túl a Kubernetes API speciális végpontokat is biztosít bizonyos erőforrásokhoz.
Például elérhetjük egy konténer naplóit közvetlen API-hívással:
GET /api/v1/namespaces/{namespace}/pods/{name}/logEz funkcionálisan megegyezik a következő paranccsal:
kubectl logs firstpodHa a konténer nem ír standard output-ra, akkor természetesen nem lesznek elérhető logok.
Hasonló módon létezik exec végpont is:
GET /api/v1/namespaces/{namespace}/pods/{name}/execEz teszi lehetővé, hogy parancsot hajtsunk végre egy futó podban, például diagnosztikai célból.
Emellett létezik watch mechanizmus is:
GET /api/v1/watch/namespaces/{namespace}/pods/{name}A watch végpont folyamatosan streameli az erőforrás változásait. Ez kulcsfontosságú a vezérlők működésében. A Kubernetes kontrollerei nem ciklikusan lekérdezik az állapotot, hanem figyelik az eseményeket, és a változásokra reagálnak.
Ez az eseményvezérelt működés biztosítja a rendszer hatékonyságát és skálázhatóságát.
Swagger és OpenAPI a Kubernetesben
A Kubernetes teljes API-ja eredetileg Swagger specifikáció alapján készült, és az idő múlásával az OpenAPI irányába fejlődött.
Ez rendkívül fontos, mert az OpenAPI leírás lehetővé teszi klienskód automatikus generálását. Ha rendelkezésre áll a specifikáció, abból generálható Go, Python, Java vagy más nyelvű klienskönyvtár.
A stabil erőforrás-definíciók elérhetők a hivatalos dokumentációban. Emellett a Swagger UI segítségével böngészhetők az API-csoportok, megtekinthetők a végpontok, paraméterek és válaszstruktúrák.
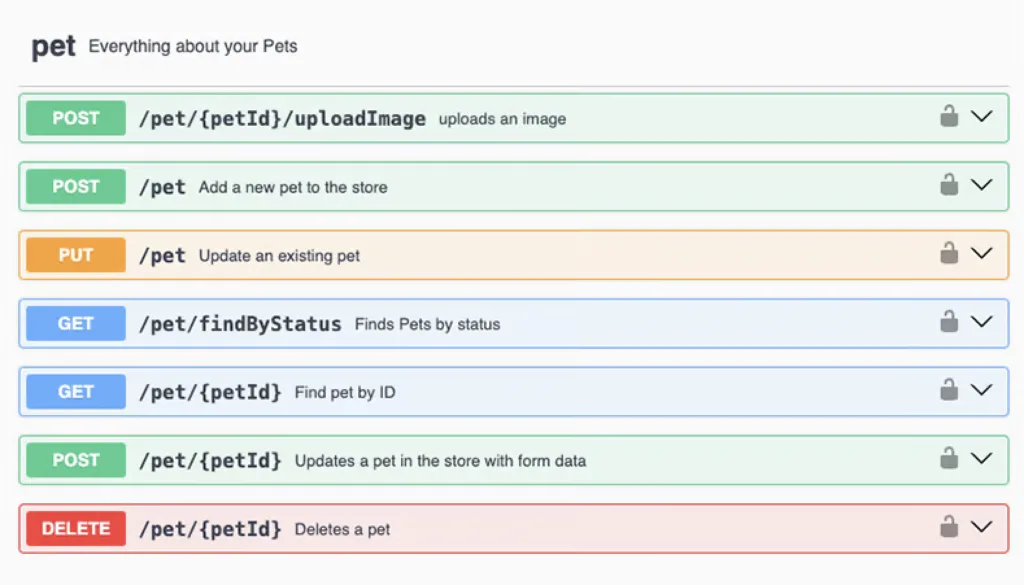
Ez a fajta formális API-leírás teszi lehetővé, hogy a Kubernetes ökoszisztéma ennyire gazdag legyen. Az operátorok, kliensek, SDK-k és automatizációs eszközök mind ugyanarra a formálisan definiált API-ra épülnek.
API-csoportok és verziózás
A Kubernetes API nem egy monolitikus struktúra. API-csoportokra és verziókra bontva épül fel.
Az API-csoportok és verziók használata lehetővé teszi, hogy a fejlesztés előrehaladjon anélkül, hogy egy meglévő API-csoport módosulna. Ez segíti a skálázható fejlesztést és a csapatok közötti munkamegosztást.
Fontos, hogy az API és a Kubernetes szoftververziója csak közvetetten kapcsolódik egymáshoz. Nem minden szoftverfrissítés jelent API-törést.
A Kubernetes API JSON és Google Protobuf szerializációs formátumokat használ, amelyek a kiadási irányelvekhez igazodnak.
Az API-verziók három érettségi szintbe sorolhatók:
- Alpha
- Beta
- Stable
Alpha
Az alpha jelölésű funkciók kísérleti állapotban vannak. Alapértelmezetten le vannak tiltva. Hibásak lehetnek, bármikor változhatnak vagy eltűnhetnek, és nem garantált a visszafelé kompatibilitás.
Csak teszt klaszterben javasolt a használatuk, amelyet gyakran újraépítenek.
Beta
A beta szintű funkciók már jobban teszteltek, és alapértelmezetten engedélyezettek. A változások során figyelnek a visszafelé kompatibilitásra, de még nem tekinthetők teljesen stabilnak.
Előfordulhatnak hibák vagy viselkedésbeli módosulások.
Stable
A stable verziókat csak egy szám jelöli, például v1. Ezek stabil API-k, amelyekre hosszú távon lehet építeni. Jelenleg a v1 az egyetlen stabil verzió.
A verziózási rendszer biztosítja, hogy a klaszterben futó alkalmazások ne törjenek el egy frissítés során, és a platform evolúciója kontrollált módon történjen.
Miért fontos ez a gyakorlatban?
Ha Kubernetes környezetben dolgozol, akkor valójában folyamatosan az API-val dolgozol, akár tudatosan, akár nem.
Amikor YAML fájlt alkalmazol, amikor egy CI/CD pipeline deployol, amikor egy operátor létrehoz egy egyedi erőforrást CRD-n keresztül, minden az API-n keresztül történik.

Az API-csoportok és verziók ismerete segít:
• megérteni, hogy egy erőforrás mennyire stabil
• eldönteni, hogy production környezetben használható-e
• tervezni a frissítési stratégiát
• automatizálási eszközöket építeni
A Kubernetes nem egyszerűen konténer-orchestration eszköz. Egy deklaratív, API-vezérelt platform, amely formálisan definiált interfészeken keresztül működik.
Ha ezt a réteget érted, akkor nem csak használod a klasztert, hanem érted is, hogyan gondolkodik.
És ez az a pont, ahol a Kubernetes már nem csak technológia, hanem architektúra.
Ha érdekelnek a hasonló Cloud és AI tartalmak:
- Iratkozz fel az InfoPack hírlevélre.
- Kövess LinkedIn-en.
- Iratkozz fel a YouTube csatornámra, ahol rendszeresen jelentkezem új szakmai videókkal.
- És ne feledkezz el megkeresni TikTok-on sem.