Az AI írta a kódot, de a felelősség akkor is a tiéd
Az elmúlt két-három évben látványosan megváltozott az, ahogyan szoftvert fejlesztünk. A GitHub Copilot, a különböző AI-alapú kódgenerátorok és a nagyobb language modelek mára ott vannak szinte minden fejlesztőcsapat eszközkészletében. Gyorsabb a munka, több kód születik rövidebb idő alatt – és ezzel együtt egy olyan kérdés is egyre élesebb: ki felel azért, ami ebből a kódból „kijön”?
Az Európai Unió válasza erre egyértelmű. És hamarosan kötelező érvényű lesz.
Mi az EU Cyber Resilience Act, és kit érint?
Az EU Cyber Resilience Act, röviden CRA, az Európai Unió első olyan horizontális kiberbiztonsági rendelete, amely gyakorlatilag minden szoftver- és hardvertermékre vonatkozik, amelyet az EU-ban értékesítenek. Nem ágazatspecifikus, nem csupán a kritikus infrastruktúrára szól – a hatálya széles. Ha szoftvert fejlesztesz és az EU-ban értékesítesz, a CRA téged is érint.
Két dátumot érdemes most megjegyezni. 2026. szeptember 11-től életbe lépnek az aktívan kihasznált sebezhetőségek kötelező bejelentési előírásai. 2027. december 11-től pedig minden egyéb kötelezettség teljes egészében érvénybe lép – beleértve a biztonságos tervezési elvárásokat, a sebezhetőség-kezelési folyamatokat és a dokumentációs kötelezettségeket.
Mi változik a fejlesztési gyakorlatban?
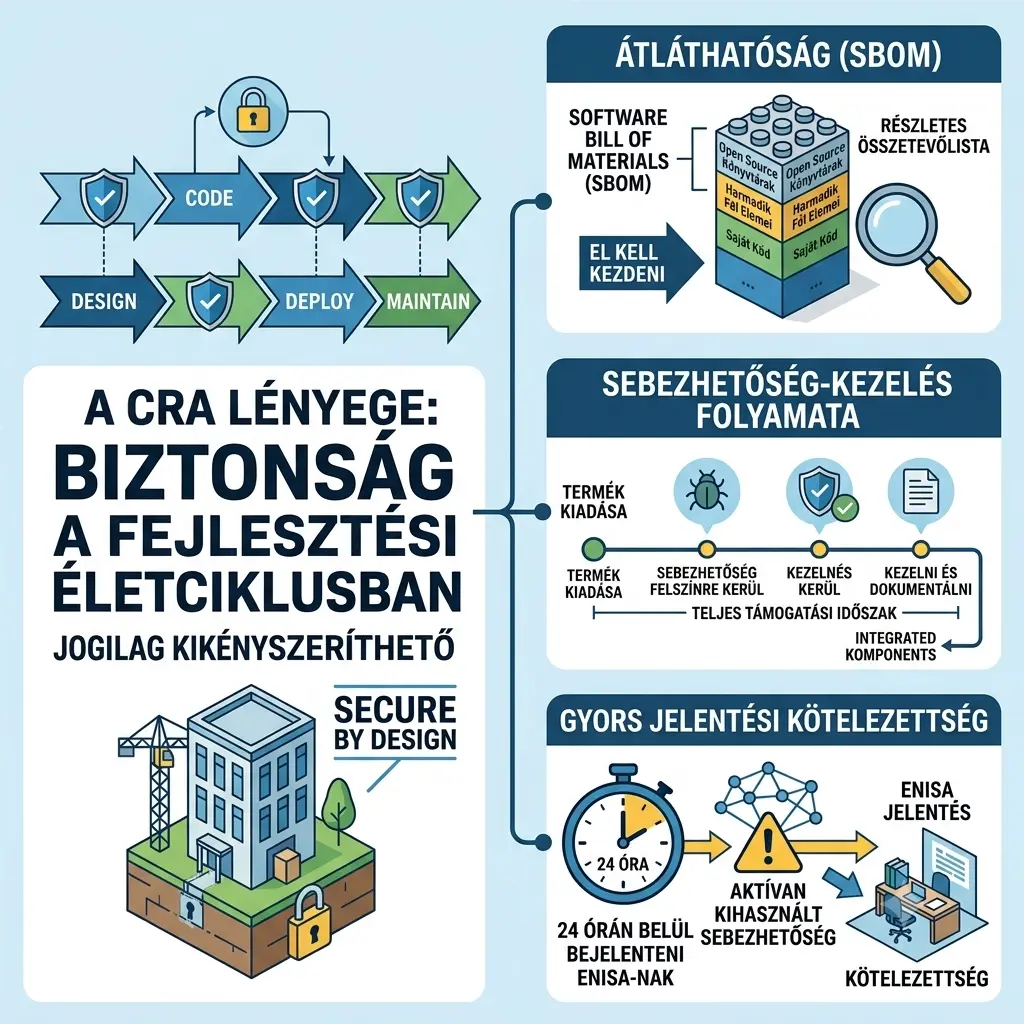
A CRA lényege, hogy a biztonságot nem lehet utólag ráhúzni egy termékre. A rendelet előírja, hogy a biztonságnak a fejlesztési életciklus minden szakaszába be kell épülnie – a tervezéstől a kódoláson át az üzembe helyezésig és az azt követő karbantartásig. Ezt angolul „secure by design” elvnek nevezik, és a CRA ezt jogilag kikényszeríthetővé teszi.
Három területen érdemes különösen figyelni.
- Az átláthatóság: A rendelet előírja az ún. Software Bill of Materials, röviden SBOM elkészítését. Ez lényegében egy részletes összetevőlista arról, hogy egy szoftvertermék milyen komponensekből áll – beleértve a felhasznált nyílt forráskódú könyvtárakat és harmadik féltől származó elemeket. Aki eddig ezt nem csinálta rendszeresen, annak el kell kezdenie.
- A sebezhetőség-kezelés folyamata: A CRA nem csupán a termék kiadásakor elvárható biztonságot szabályozza, hanem az azt követő teljes támogatási időszakra kiterjeszti a kötelezettségeket. Ha egy sebezhetőség kerül felszínre – akár egy beépített open source komponensben –, azt kezelni és dokumentálni kell.
- A gyors jelentési kötelezettség: Ha egy aktívan kihasznált sebezhetőség válik ismertté, azt 24 órán belül be kell jelenteni az EU kiberbiztonsági ügynökségének, az ENISA-nak. Ez nem ajánlás, hanem kötelezettség.
Miért különösen fontos ez az AI-generált kód esetén?
Ez az a pont, ahol a fejlesztők egy része meglepődik. Az EU CRA nem tesz különbséget aközött, hogy a kód emberi kézből vagy egy AI-eszközből származik. A felelősség a szoftver kiadójánál marad.
Az a gyakorlat, amelyet egyre több csapatnál látok – amikor az AI által generált kódot minimális ellenőrzés után élesbe küldik –, ebben a jogi környezetben komoly kockázatot jelent. A „nem tudtuk, az AI generálta” érv a szabályozói vizsgálaton nem fog megállni. A dokumentációs kötelezettség, az SBOM-követelmény és a sebezhetőség-kezelési elvárás mind vonatkozik az AI-generált kódra is, ha az részét képezi a terméknek.
Ez nem az AI-eszközök ellen szól. Hanem amellett, hogy a csapatoknak ki kell alakítaniuk azokat a folyamatokat, amelyekkel az AI kimenetét valóban ellenőrzik és dokumentálják – mielőtt az kijut a termékbe.
Mit érdemes most elkezdeni?
Három konkrét lépés van, amelyeket érdemes azonnal megtenni, függetlenül attól, hogy a csapat mekkora vagy milyen piacon dolgozik.
- A teljes szoftverkészlet leltározása: Minden terméknek, minden függőségnek, minden felhasznált komponensnek láthatónak kell lennie. Az AI-generált kódrészletek is ide tartoznak.
- A fejlesztési folyamatok dokumentálása: Ha egy folyamat nincs leírva és bizonyítható módon követve, a szabályozó azt feltételezi, hogy nem létezik. Ez nem bürokratikus igény, hanem a megfelelőség alapja.
- Az SBOM-eszközök bevezetése: Ezek nem luxusmegoldások – mára elérhetők és beilleszthetők a meglévő fejlesztési pipeline-ba. Aki ezt most kezdi el, annak jó esélye van arra, hogy 2027-re valóban felkészülten érkezzen a teljes kötelezettség bevezetéséhez.
Összefoglalás
Az EU Cyber Resilience Act nem egy távoli, jövőbeli probléma. Az első kötelezettségek már 2026 szeptemberétől érvényesek. Aki szoftvert fejleszt és az EU-s piacon értékesít, annak most kell elkezdenie felkészülni – különösen akkor, ha a fejlesztési folyamatban AI-eszközök is szerepet kapnak.
A szabályozó nem az eszközre kíváncsi. Arra kíváncsi, hogy a szoftver biztonságos-e, és hogy ezt be tudod-e bizonyítani.