Aki régen dolgozik Azure-ban, mint én is, rendszeresen kap értesítő e-maileket, amelyekben biztonsági okokból kérik a felhasználót az infrastruktúra módosítására. Most is jött egy ilyen, október elején: a Microsoft arra figyelmeztet, hogy az Azure Tárfiókoknál 2026. február 3. után már csak a TLS 1.2 vagy újabb verzió lesz támogatott.
Ez az értesítés elsősorban azokat érinti, akiknek a Tárfiókjai még TLS 1.0 vagy 1.1 protokollt is elfogadnak. Ezek a régebbi titkosítási eljárások ma már elavultnak számítanak, és nem támogatják a modern kriptográfiai algoritmusokat, ezért a Microsoft fokozatosan megszünteti a használatukat.
Mi az a TLS és miért fontos?
A TLS (Transport Layer Security) egy biztonsági protokoll, amely az internetes adatátvitel védelmét szolgálja. A korábbi verziók (1.0 és 1.1) több mint 20 évesek, és ma már nem felelnek meg a biztonsági követelményeknek. A TLS 1.2 gyorsabb és biztonságosabb kommunikációt biztosít, amely jobban védi az adatokat a lehallgatás és a manipuláció ellen.
Mi a teendő?
Ha az Azure Tárfiókod TLS 1.0 vagy 1.1 protokollt is enged, akkor 2026. február 3-ig frissítened kell a beállításokat, különben az alkalmazásaid nem fognak tudni biztonságosan csatlakozni a szolgáltatáshoz.
A Microsoft ajánlása egyértelmű:
Állítsd be a Minimális TLS-verziót 1.2-re (vagy újabbra).
Ellenőrizd, hogy az alkalmazásaid és SDK-jaid is támogatják a TLS 1.2-t.
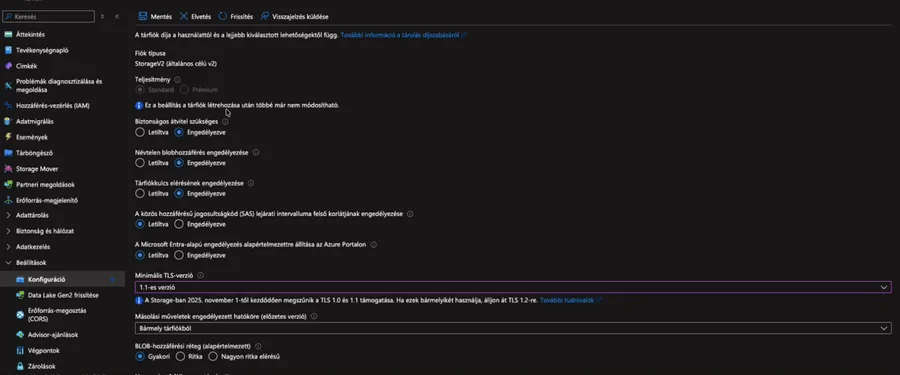
Hogyan lehet beállítani a TLS 1.2-t az Azure portálon?
A beállítás módosítása néhány kattintás az Azure portálon:
Lépj be az Azure Portalba.
Keresd meg a módosítani kívánt Tárfiókot.
A bal oldali menüben válaszd a Beállítások > Konfiguráció (Settings > Configuration) menüpontot.
A Minimális TLS-verzió (Minimum TLS version) beállításnál válaszd ki a TLS 1.2 opciót.
Mentsd el a módosítást (Mentés / Save).
Ha több Tárfiókod van, érdemes Azure Policy-t is használni, hogy központilag kikényszerítsd a TLS 1.2 beállítást minden fiókra.
Meddig van időm ezt elvégezni?
A határidő 2026. február 3., eddig kell minden Tárfiókon elvégezni a frissítést. Ezt követően a TLS 1.0 és 1.1 kapcsolatokat az Azure Tárfiók már nem fogadja el.
Aki addig nem módosítja a beállításokat, annak az alkalmazásai hibát fognak adni, amikor megpróbálnak kapcsolódni a Tárfiókhoz.
Összefoglalás
A változás célja, hogy az Azure-felhasználók biztonságosabb és korszerűbb titkosítási eljárásokat használjanak. A frissítés mindössze néhány percet vesz igénybe, de elengedhetetlen a jövőbeni hibamentes működéshez.
A felhőalapú technológiák rohamos terjedésével egyre nagyobb hangsúlyt kap az erőforrásokhoz való hozzáférés kezelése. Az elmúlt hónapokban már több cikkben is körbejártuk, hogyan épülnek fel a modern felhőarchitektúrák, és milyen eszközökkel tarthatók átláthatóan karban. Most azonban elérkeztünk egy olyan témához, ami nélkül minden korábbi tudás bizonytalan lábakon állna: a hozzáférés-kezeléshez. Ennek egyik legfontosabb pillére az RBAC, vagyis a Role-Based Access Control – magyarul szerepkör-alapú hozzáférés-vezérlés.
Képzeljünk el egy nagyvállalatot, ahol több száz vagy több ezer ember dolgozik különböző projekteken. Nem mindenki férhet hozzá mindenhez – a fejlesztők nem módosíthatják a pénzügyi adatokat, az adminisztrátor viszont nem feltétlenül lát bele az alkalmazás kódjába. Az RBAC éppen ezt a problémát oldja meg: egyértelműen meghatározza, ki mit tehet és mit nem.
Mi az RBAC lényege?
Az RBAC alapelve, hogy a hozzáférési jogokat nem közvetlenül a felhasználókhoz, hanem szerepkörökhöz rendeljük. Ezek a szerepkörök előre definiált engedélyeket tartalmaznak, amelyek meghatározzák, milyen műveletek hajthatók végre adott erőforrásokon. A felhasználók ezután egy vagy több szerepkört kaphatnak – így az engedélyezés egyszerre lesz átlátható, rugalmas és könnyen kezelhető.
A koncepció három alapeleme:
Felhasználók (Users) – azok a személyek vagy szolgáltatások, akik hozzáférnek az erőforrásokhoz.
Szerepkörök (Roles) – engedélyek gyűjteménye, például „Reader”, „Contributor” vagy „Owner”.
Hozzárendelések (Role Assignments) – ezek kapcsolják össze a felhasználót, a szerepkört és az adott erőforrást.
Hogyan működik az RBAC az Azure-ban?
Az Azure RBAC az Azure Resource Manager (ARM) modellre épül, és segítségével szabályozható, hogy ki milyen műveleteket végezhet el Azure-erőforrásokon – például virtuális gépeken, tárfiókokon, adatbázisokon vagy hálózati elemekben.
Az Azure-ban minden erőforrás hierarchikus struktúrában helyezkedik el:
Management Group (Felügyeleti csoport) – a legfelső szint, amely több előfizetést is összefoghat.
Subscription (Előfizetés) – az erőforrások logikai egysége, ahol a számlázás és az erőforrás-kvóták kezelése történik.
Resource Group (Erőforráscsoport) – az erőforrások rendezésére szolgáló konténer, például egy adott projekt vagy alkalmazás elemei számára.
Resource (Erőforrás) – az egyes Azure-szolgáltatások, például virtuális gépek, tárfiókok, adatbázisok vagy hálózati elemek.
Egy szerepkör-hozzárendelés bármelyik szinten megadható, és öröklődik a hierarchia alatti szintekre. Ha például valaki Reader jogot kap egy teljes előfizetés szinten, akkor automatikusan olvashatja az összes erőforráscsoport és erőforrás tartalmát abban az előfizetésben.
RBAC a gyakorlatban (példa)
Képzeljük el, hogy egy fejlesztőcsapat három szereplőből áll:
Attila, a vezető fejlesztő
Péter, az infrastruktúra adminisztrátor
Zoli, a tesztelő
Az IT biztonsági elv szerint mindenkinek csak a munkájához szükséges jogokat adjuk meg.
Attila (Contributor) – létrehozhat, módosíthat és törölhet erőforrásokat a fejlesztői Resource Group-ban, de nem kezelheti a hozzáféréseket.
Péter (Owner) – teljes körű hozzáféréssel rendelkezik, így módosíthatja a szerepköröket és erőforrásokat is.
Zoli (Reader) – csak megtekintheti a fejlesztési környezetben található erőforrásokat, de nem módosíthat semmit.
Ez a megközelítés egyszerre biztonságos és hatékony, hiszen mindenki csak azt látja és azt kezeli, ami a feladata ellátásához szükséges.
RBAC szerepkörök az Azure-ban
Az Azure több mint 120 beépített szerepkört kínál, de a leggyakoribbak közé tartozik:
Owner – teljes hozzáférés mindenhez, beleértve a hozzáférés-kezelést is.
Contributor – minden erőforrást módosíthat, de nem kezelheti a jogosultságokat.
Reader – csak olvasási hozzáféréssel rendelkezik.
User Access Administrator – mások jogosultságait kezelheti, de magukat az erőforrásokat nem módosíthatja.
Ezen felül lehetőség van egyedi szerepkörök létrehozására is, ha a beépített szerepkörök nem fedik le pontosan a szervezet igényeit. Egyedi szerepkörök JSON formátumban definiálhatók, és pontosan meghatározható bennük, milyen műveletek engedélyezettek vagy tiltottak.
Az RBAC előnyei
Biztonság – Csökkenti a túlzott jogosultságok kockázatát, így kevesebb az emberi hiba vagy jogosulatlan hozzáférés.
Átláthatóság – Könnyen ellenőrizhető, ki milyen jogokkal rendelkezik.
Skálázhatóság – Nagyvállalati környezetben is egyszerűen kezelhető a jogosultságok bővülése.
Automatizálhatóság – A szerepkörök hozzárendelhetők automatizált szkriptekkel vagy Terraform kódokkal is.
Az RBAC korlátai
Bár az RBAC rendkívül hasznos, nem minden esetben elégséges.
Nem tudja kezelni az adatszintű hozzáféréseket (például egy SQL tábla soraira vonatkozó jogosultságokat).
A komplex szervezeti hierarchiákban a szerepkörök öröklődése nehezen átláthatóvá válhat.
Túl sok egyedi szerepkör esetén nő az adminisztrációs teher és a hibalehetőség.
A cégek számára az RBAC legnagyobb előnye a kontroll és a biztonság egyensúlya. Ahelyett, hogy mindenki korlátlanul hozzáférne mindenhez, az RBAC lehetővé teszi, hogy a hozzáférés csak a szükséges mértékben legyen biztosítva.
A felhasználók számára ez azt jelenti, hogy egyértelműen látják, mire jogosultak, és nem kell aggódniuk a véletlen hibák miatt. Egy fejlesztő például nyugodtan dolgozhat a saját projektjén anélkül, hogy kockáztatná más rendszerek működését. A rendszergazdák pedig gyorsabban és pontosabban tudják kiosztani az engedélyeket, akár automatizált folyamatokon keresztül is.
Összegzés
A Role-Based Access Control az egyik legfontosabb biztonsági és hatékonysági alapelv a felhőben. Az Azure RBAC egy kifinomult, de logikusan felépített rendszer, amely segít abban, hogy a szervezetek biztonságosan, mégis rugalmasan kezeljék a hozzáféréseket.
Az alapelve egyszerű: mindenkinek csak annyi jogot adjunk, amennyire valóban szüksége van.
Ez a szemlélet nemcsak az Azure-ban, hanem bármely modern informatikai környezetben elengedhetetlen, ahol a bizalom és az ellenőrzés kéz a kézben jár.
Az elmúlt időszak eseményei olyanok, mint egy mese, ami váratlanul rémálommá vált. Képzeld el, hogy van egy kis kikötő, ahol a hajók évek óta ugyanazt a megbízható szállítótól kapják az alkatrészeket, ráadásul ingyen. A kapitányok megszokták, hogy mindig időben érkezik az utánpótlás, és minden zökkenőmentesen működik. Egy nap azonban a kikötőt átveszi egy új tulajdonos, aki közli: a régi, készleten lévő alkatrészek ugyan még elérhetők, de újak már nem lesznek, legalábbis nem ingyen.
A kapitányok előtt három út marad: átállnak az új, drágább rendszerre, saját megoldást keresnek, vagy alternatív kikötőt választanak.
Technológiailag ez a helyzet tükrözi, amit néhány napja a Bitnami Docker image-k kapcsán bejelentettek. Sok fejlesztői közösség számára hirtelen egy új realitással kell szembenézni – és most megnézzük együtt, mit is jelent ez a változás, és milyen lehetőségeink vannak.
Mi az a Bitnami?
A Bitnami egy régóta ismert projekt, amely célul tűzte ki, hogy nyílt forrású szoftvereket (pl. adatbázisokat, webkiszolgálókat, cache-rendszereket) „do‐it‐yourself” egyszerűségű csomagként kínáljon: konténerképek, Helm chartok, könnyű telepíthetőség. Évtizedeken át sok Kubernetes-projekt, fejlesztő és üzemeltető használta ki előre konfigurált Bitnami image-eket és chartokat, mivel ezek stabilan, dokumentáltan és viszonylag kevés törés mellett működtek.
A Bitnami projekt most a Broadcom portfóliójába tartozik (Broadcom a VMware-t vásárolta fel), és ennek kapcsán stratégiai átalakítást hajt végre a konténerkép-disztribúciójában.
Miért fontos ez a változás?
A Bitnami eddig szerepelt sok Kubernetes infrastruktúra alapvető építőköveként: telepíthető komponensek, megbízható konténerképek, és helm chartok, amelyek akadálymentesítették az alkalmazások bevezetését. Amikor ez a támogatás visszavonul, többféle technikai és gyakorlati kockázat jelenik meg:
A docker.io/bitnami publikus regisztrációs hely (ahonnan sok image eddig szabadon letölthető volt) a változások hatására mérséklődik, és sok verziós címke eltűnik.
Az eddigi képek átkerültek egy Bitnami Legacy (bitnamilegacy) regiszterbe, ahol nem kapnak több kiadást, frissítést, biztonsági javítást.
Egy új, Bitnami Secure Images (bitnamisecure) hivatalosan nem „közösségi” szolgáltatás, hanem vállalati előfizetéshez kötött, fizetős kínálat.
A publikus Helm chartok (az OCI manifestjeik) frissítése is szünetel: a forráskód továbbra is elérhető marad GitHub-on, de az automatikus képek, verziófrissítések nem mindig jönnek majd.
A végleges “központi” publikus Bitnami regiszter törlése 2025. szeptember 29-én volt.
A Bitnami Secure Images vállalati előfizetésként érhető el, ára a források szerint több ezer dollár havonta, jellemzően 6 000 USD/hó körüli szinten indul.
Mindez azt jelenti, hogy ha nem léptünk időben, a Kubernetes klaszterekben, CI/CD folyamatokban, frissítési és automatikus skálázási műveletek során hirtelen hibaüzenetekkel (például ImagePullBackOff, ErrImagePull) találkozhatunk, amikor a rendszer nem tudja letölteni a szükséges képeket.
Mit okozhat a Kubernetes alapú rendszerekben?
Ha nem készültünk fel:
Új podok nem indulnak el – amikor a fürt új csomópontot indít vagy új replika szükséges, a rendszer letöltené a Bitnami image-t, de ha az már nem elérhető, hibát kapunk: ErrImagePull vagy ImagePullBackOff.
Frissítés vagy skálázás meghiúsul – ha egy alkalmazást új verzióra frissítenénk, de a chartban vagy a konfigurációban Bitnami image hivatkozás van, akkor az update művelet elbukhat.
Biztonsági elmaradások halmozódnak – a bitnamilegacy képek fagyottak: nem kapnak további biztonsági frissítést, így elavult, sérülékeny komponensek maradhatnak használatban.
Rejtett függőségek okozta meglepetések – nemcsak közvetlen alkalmazásaink használhatják Bitnami képeket, hanem alcsomagok, segédkonténerek, init container-ek is, amelyek rejtetten hivatkozhatnak a bitnami regiszterre.
CI/CD pipeline-ok hibái – ha build vagy teszt folyamat során Bitnami képet húzunk be (pl. adatbázis konténer, migrációs konténer), akkor az egész pipeline leállhat.
Összességében tehát egy jól működő rendszerben sok esetben „hallgatólagos” függőségek fognak megbukni, és váratlan leállások vagy hibák léphetnek fel.
Milyen lehetőségeink vannak a problémák megoldására?
Ahogy a halász a történetben új kikötőt vagy hajót választhat, nekünk is több stratégiánk van:
1. Átirányítás a Bitnami Legacy Registry (bitnamilegacy)
Ez a legegyszerűbb ideiglenes megoldás: módosítjuk a konfigurációkat (helm values, deployment spec) úgy, hogy a repository: bitnamilegacy/… formát használjuk, és tartsuk meg a jelenlegi címkéket, amíg át tudunk térni.
Előny: viszonylag kevés munkával elérhető átmeneti működés. Hátrány: ezek az image-ek nem kapnak új frissítéseket vagy biztonsági javításokat — idővel elavultak lesznek.
Ha ezt választjuk, erősen ajánlott saját privát regiszterbe tükrözni (mirror), hogy legalább ne függjünk harmadik féltől.
2. Használjuk a Bitnami Secure Images (BSI) szolgáltatást
A Bitnami bejelentette, hogy új, „secure”, hardened képek és Helm chartok szolgáltatása indul, amely verziókezelést, SBOM-ot, CVE-transzparenciát, és egyéb vállalati tulajdonságokat ad. Ez a megoldás azonban jellemzően fizetős, és inkább vállalati környezetekben lesz értelmes választás. Ha előfizetünk, akkor a képek és chartok publikusan már nem a bitnami regiszteren lesznek, hanem automatikus privát vagy dedikált OCI regisztereken. A Bitnami beígérte, hogy a Secure Images kínálat kisebb, de biztonságosabb verziókat fog tartalmazni (distroless képek, kisebb támadási felület).
3. Teljes elszakadás a Bitnami képektől – alternatívák és saját build
Ez a leginkább javasolt hosszú távon: magunknak választunk más képeket (például hivatalos Docker képeket, más közösségi projektek képeit), vagy akár a Bitnami számára elérhető open source konténerforrásokból saját képeket építünk és menedzselünk.
A Bitnami-forráskódok (Dockerfile-ok, Helm chartok) továbbra is elérhetők GitHubon Apache 2 licenccel — tehát jogilag megengedett saját építésre.
Kiválaszthatunk megbízható, aktív közösségű alternatívákat (pl. hivatalos image-ek, distro-specifikus build-ek).
Szükség lehet az értékek és beállítások átalakítására, mert nem minden image viselkedik ugyanúgy, mint a korábbi Bitnami verziók.
Célszerű bevezetni folyamatos integrációs (CI) pipeline-ban a képek tesztelését, vulnerability scan-t, hogy újabb függőségi hibák ne csússzanak be.
Lépésként részleges migráció is szóba jöhet: először a kritikus komponenseket „lecsupaszított”, alternatív képekkel cserélni, majd haladni tovább.
4. Audit és függőségek feltérképezése
Mielőtt döntenénk, célszerű átfogó auditot végezni:
Kikeresni az összes konténerkép-hivatkozást (pl. grep bitnami a manifestekben).
Megszámolni azokat a fürtön belüli podokat, amelyek Bitnami képet használnak (pl. kubectl get pods -A -o json | jq … | grep bitnami)
Felmérni, mely komponensek kritikusak, melyek kevésbé veszélyeztetettek, hogy prioritásokat állíthassunk.
Tesztelni a migrált konfigurációkat staging környezetben, hogy ne érjen minket meglepetés élesben.
5. Fokozatos átállás, párhuzamos környezetek
Nem feltétlenül kell mindent egyszerre lecserélni. Lehet fokozatosan:
Kritikus komponensek migrálása
Tesztkörnyezetek kipróbálása
Monitorozás, visszajelzések gyűjtése
Végleges átállás
Ez csökkentheti a kockázatot, és lehetőséget ad arra, hogy közbe avatkozzunk, ha valami nem működik.
Összegzés
Ez jelentős változás a konténeres és Kubernetes-alapú rendszerek világában. Ha nem készültünk fel, akkor ImagePull hibák, skálázási problémák és biztonsági elmaradások várnak ránk.
A legbiztosabb megoldás hosszú távon az, ha függetlenedünk a Bitnami-tól: alternatív képeket használunk, saját építésű konténereket alkalmazunk, és megfelelő folyamatokat építünk be (audit, tesztelés, scanning). Addig is átmeneti megoldásként a Bitnami Legacy regiszter használata segíthet.
Korábban részletesen bemutattam a CDN alapfogalmait, ahol szó volt arról, hogy miként lehet a tartalmakat közelebb vinni a felhasználókhoz, csökkentve a késleltetést és tehermentesítve az eredeti szervereket. Utána írtam az AWS CDN megoldásáról is az AWS CloudFront szolgáltatásról.
Most egy lépéssel tovább megyünk, és megmutatom az Azure CDN-t, amely a Microsoft felhőszolgáltatásának egyik legfontosabb eleme. Gondoljunk bele: mi történik, ha egy nagy nemzetközi esemény közvetítése, egy webáruház kampányidőszaka vagy egy globális alkalmazás frissítése egyszerre több millió felhasználóhoz jut el? Ilyenkor mutatkozik meg igazán, mennyit ér egy jól felépített CDN.
Mi az Azure CDN?
Az Azure Content Delivery Network (CDN) lényege, hogy a tartalmakat – legyen szó weboldalról, képekről, videókról vagy alkalmazásfájlokról – világszerte elérhető peremhálózati (edge) szervereken tárolja. Ezek a szerverek közelebb vannak a végfelhasználókhoz, így az adatok gyorsabban töltődnek be, csökken a hálózati késleltetés, és a felhasználói élmény jelentősen javul. Jelenleg kétféle háttérhálózaton érhető el:
Azure CDN from Microsoft, amely a Microsoft saját globális hálózatát használja.
Azure CDN from Edgio, amely korábban Verizon/Edgecast néven működött, de átnevezés után is elérhető opció maradt.
A korábbi Azure CDN from Akamai szolgáltatás 2023. októberében kivezetésre került, így ma már nem érhető el új előfizetők számára.
Erősségek
Globális jelenlét: a Microsoft saját hálózata és az Edgio közösen biztosítanak világszintű edge pontokat.
Biztonság:HTTPS támogatás, token alapú hitelesítés és modern titkosítási szabványok.
Rugalmasság: fejlett szabálykezelés a gyorsítótárazás finomhangolásához.
Analitika: részletes statisztikák a forgalomról és a teljesítményről.
Lehetőségek és korlátok
Az Azure CDN nem old meg minden teljesítményproblémát. Ha a tartalomforrás lassú vagy hibásan konfigurált, a CDN nem tudja ellensúlyozni. Emellett költséggel is jár: a globális adatforgalom és a speciális funkciók használata külön díjazás alá eshet. Fontos a gondos tervezés, hogy a szolgáltatás valóban értéket adjon.
Felhasználási esetek
Weboldalak:WordPress alapú oldalak esetén a képek és videók gyorsan betöltődnek bárhonnan a világon.
E-kereskedelem: nemzetközi webshopok stabil vásárlói élményt tudnak biztosítani csúcsidőben, például Black Friday alatt.
Streaming: videószolgáltatók számára akadozásmentes lejátszást biztosít még extrém terhelés mellett is.
Azure CDN és AWS CloudFront. Mikor?
Mindkét szolgáltatás globális lefedettséget, integrációt és biztonságot kínál.
Azure CDN: előnyös azoknak, akik elsősorban Microsoft-ökoszisztémát használnak.
AWS CloudFront: jobban illeszkedik az Amazon szolgáltatásaihoz, például az S3-hoz és a Lambda@Edge-hez.
A választás gyakran attól függ, melyik felhőszolgáltatót használja az adott szervezet elsődlegesen.
Összegzés
Az Azure CDN ideális választás minden olyan vállalat számára, amely globális jelenlétet, gyorsabb betöltődést és jobb felhasználói élményt szeretne biztosítani. Ez közvetlen üzleti előnyt is jelent: nagyobb konverziós arányt, elégedettebb ügyfeleket és jobb piaci megítélést.
Korábban már írtam olyan felhőszolgáltatásokról, amelyek nem csupán hasznosak, hanem kifejezetten izgalmasak is. Például az AI-t használó SageMaker Canvas, amely segít egyszerűen elindulni a gépi tanulás világában. A felhő világában azonban nemcsak az intelligencia, hanem a sebesség és a megbízhatóság is kulcsfontosságú. Gondoljunk csak bele: ha egy weboldal lassan töltődik be, a felhasználók nagy része azonnal bezárja.
Képzelj el egy mesebeli könyvtárat, ahol a világ összes könyve elérhető. Amikor keresel valamit, nem kell a fővárosba utaznod, mert minden nagyobb városban van egy helyi fiók, amelyben a legnépszerűbb könyvek ott várnak rád. Így bárhol jársz a világban, mindig gyorsan megkapod, amit keresel. A digitális világban pontosan ezt a szerepet tölti be a CDN (Content Delivery Network).
Mi az a CDN?
A CDN egy globális szerverhálózat, amely a weboldalak és alkalmazások statikus tartalmát (képeket, videókat, JavaScript és CSS fájlokat) a felhasználóhoz földrajzilag közel tárolja.
Amikor egy látogató megnyit egy weboldalt, a tartalom nem feltétlenül az eredeti központi szerverről érkezik, hanem a hozzá legközelebb lévő „edge” szerverről. Ez a közeli kiszolgálás drámaian lecsökkenti a betöltési időt, és így javítja a felhasználói élményt.
Hogyan működik?
Cache-elés (gyorsítótár): A statikus tartalmak (pl. képek, videók) előre másolatként elérhetőek a CDN pontokon.
Edge szerverek: Ezek a földrajzilag szétszórt szerverek a világ számos pontján elhelyezkednek.
Intelligens forgalomirányítás: A felhasználó mindig a legközelebbi edge szervertől kapja meg a tartalmat.
Frissítés kezelése: Amikor a központi szerveren változik egy fájl, a CDN gondoskodik róla, hogy az új verzió a cache-elt példányokat is felülírja.
Milyen előnyöket nyújt a CDN?
Gyorsabb betöltési idő: A tartalom a felhasználóhoz közeli szerverről érkezik. Egy tokiói látogató nem Budapestről tölti le a képet, hanem Japánból.
Megbízhatóság és redundancia: Ha egy szerver kiesik, a hálózat más pontjai átveszik a terhelést.
Skálázhatóság: Nagy forgalomnövekedés esetén (pl. Black Friday, kampányidőszak) a CDN elosztja a terhelést.
Biztonság: Sok CDN véd DDoS támadások ellen és automatikus HTTPS támogatást kínál.
Példák a CDN használatára
WordPress weboldal Képzelj el egy WordPress blogot, amely tele van képekkel és videókkal. A szerver Budapesten van, de az olvasóid Németországból, az USA-ból és Ázsiából is érkeznek. Ha minden tartalom csak Budapestről érkezne, a távoli látogatóknak lassan töltődne be. Ha viszont a képeket és videókat a CDN tárolja, akkor a felhasználók mindenhol ugyanolyan gyorsan kapják meg az oldal tartalmát – a legközelebbi edge szerverből. Ez jobb élményt ad, és az oldal Google-keresési rangsorolása is javulhat.
Globális SaaS szolgáltatás Egy CRM rendszert több ezer cég használ világszerte. Az alkalmazás szerverei Frankfurtban vannak, de az ügyfelek Dél-Amerikában és Ázsiában is dolgoznak vele. CDN nélkül mindenki ugyanarra a központi szerverre kapcsolódna, ami lassulást és instabilitást okozhatna. A CDN azonban gondoskodik róla, hogy az alkalmazás statikus részei (UI, JavaScript, képek) a felhasználókhoz közeli edge szerverekről töltődjenek le. Az élmény olyan, mintha az alkalmazás helyben futna.
Médiaoldal vagy streaming szolgáltatás Egy nagy hírportálnál vagy streaming cégnél kritikus, hogy a videók megszakítás nélkül fussanak, még akkor is, ha milliók nézik egyszerre. A CDN segít elkerülni a túlterhelést, és biztosítja, hogy a tartalom folyamatosan, késleltetés nélkül érkezzen a felhasználókhoz.
Hogyan kapcsolódik a felhőhöz?
A nagy felhőszolgáltatók kínálnak saját CDN megoldást:
Amazon CloudFront (AWS)
Azure Front Door
Google Cloud CDN
Ezek közvetlenül integrálhatók más szolgáltatásokkal (például tárhellyel, webalkalmazás-szerverekkel), így szinte automatikusan skálázható és globálisan gyors rendszer hozható létre.
Vannak korlátai is
Költség: Nagy adatforgalom esetén a CDN komoly költséget jelenthet.
Beállítási komplexitás: A kezdőknek a konfiguráció elsőre bonyolult lehet (cache szabályok, TTL értékek).
Nem minden tartalomhoz ideális: A CDN főként statikus fájloknál hatékony. Dinamikus tartalom, például adatbázis-lekérdezések nem gyorsíthatók vele közvetlenül.
Mikor érdemes CDN-t használni?
A weboldalad vagy alkalmazásod nemzetközi közönséget céloz.
Kritikus számodra a sebesség és felhasználói élmény.
Gyakoriak a nagy forgalmi hullámok.
Ha a biztonságot szeretnéd növelni.
Összefoglalás
A CDN a modern web egyik alapköve. Olyan, mintha a digitális világ könyvtárát földrajzi fiókokra osztanánk, így mindig gyorsan és biztonságosan elérhető lenne a tartalom. Nem minden projektnél szükséges, de ahol a sebesség, a stabilitás és a globális jelenlét fontos, ott a CDN szinte kötelező.
A Te weboldalad vagy alkalmazásod is profitálna a gyorsabb betöltésből és a stabilabb működésből – lehet, hogy épp most jött el az idő a CDN kipróbálására.
Internetezési szokásaink sokat változtak az elmúlt években. Emellett az AI megjelenésével, egy új trend is megjelent: mindenki AI-t akar használni mindenhol. Mondhatjuk, hogy fejetetejére állt a világ, hiszen 2022 óta egy technológiai forradalom zajlik.
Ebben a hatalmas változásban, azt gondolnánk, hogy minden technológia új, úttörő és innovatív. Ez azonban nem nem teljesen igaz. Az internet és az ehhez kapcsolódó technológiák alapja még mindig ugyanaz, mint amikor megjelentek. Annak ellenére is, hogy körülöttük, szinte minden megváltozott. Ma egy ilyen megoldás kapcsén szeretnék nektek bemutatni egy Azure szolgáltatást.
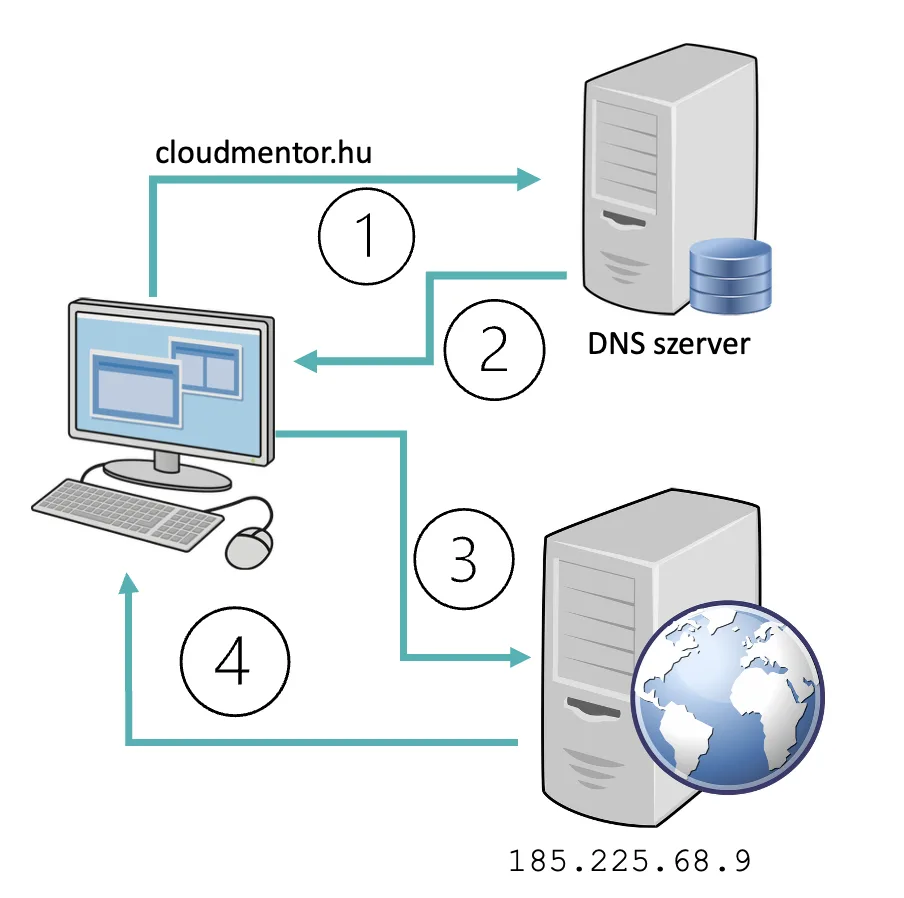
Az interneten minden weboldal és alkalmazás mögött IP-címek állnak. Ezek a számok nehezen megjegyezhetők, ezért használjuk a domain neveket. A DNS (Domain Name System) olyan, mint egy univerzális telefonkönyv: amikor beírsz egy webcímet, a DNS kikeresi a megfelelő IP-címet. Erről, már az AWS Route 53 DNS megoldásáról szóló cikkben írtam, most pedig azt nézzük meg, hogyan működik mindez az Azure DNS szolgáltatásban.
Mi az Azure DNS?
Az Azure DNS egy felhőalapú névkiszolgáló, amely lehetővé teszi az általad birtokolt domain zónáinak és rekordjainak kezelését. Az Azure globális infrastruktúráját használja (ez azt jelenti, hogy a Microsoft világszerte elhelyezett adatközpontjaiban és peremhálózati (edge) helyein futnak a DNS-szerverek), így biztosítja a gyors, megbízható és magas rendelkezésre állású névfeloldást. A kezelése egyszerű, mert ugyanazokon az eszközökön keresztül történik, mint más Azure-erőforrásoké: Azure Portal, CLI, PowerShell, REST API vagy akár infrastruktúra mint kód megoldásokkal (pl. Terraform).
Miért érdemes használni?
Hagyományosan a DNS-t külön szolgáltatóknál vagy domain-regisztrátoroknál kezelték. Ha azonban már eleve Azure-t használsz, logikus lépés lehet a DNS-t is ide integrálni, hogy minden egy helyen kezelhető legyen. Ez egységesebb, biztonságosabb és könnyebben automatizálható üzemeltetést jelent. Emellett igen kényelmes is ez a helyzet.
Erősségek
Mik is az Azure DNS erősségei?
Megbízhatóság: A Microsoft globális névszerver-hálózata biztosítja, hogy a DNS-lekérdezések mindig gyorsak és elérhetők legyenek.
Biztonság: Az Azure Active Directory (EntraID) integráció lehetővé teszi a kifinomult jogosultságkezelést.
Egységes kezelés: Az összes erőforrásodhoz hasonlóan a DNS is ugyanazon az Azure-felületen kezelhető, így nem kell új rendszert megtanulni.
Automatizálhatóság: Könnyen integrálható CI/CD folyamatokba és infrastruktúra mint kód megoldásokba.
Privát DNS-zónák: Nemcsak publikus, hanem belső (pl. több virtuális hálózat között megosztott) DNS-szolgáltatást is nyújt.
Lehetőségek és korlátok
Domain-regisztráció az Azure-ban:
Az Azure DNS önmagában nem regisztrátor, de az App Service-tartomány szolgáltatáson keresztül közvetlenül is vásárolhatsz domaint az Azure Portalról.
Ezt a Microsoft a GoDaddy partneren keresztül biztosítja, így egyszerű a kezelés, de technikailag nem az Azure DNS maga regisztrálja a domaint.
Fontos korlát, hogy .hu végződésű domaint nem lehet így regisztrálni, azt csak más szolgáltatón keresztül lehet megvenni, majd delegálni az Azure DNS-re.
Költségek: Árazása rendkívül kedvező (alapesetben nagyjából 200 Ft/zóna/hónap). A zónák fenntartása olcsó, és a lekérdezések díja is minimális, így a legtöbb szervezet számára elhanyagolható költséget jelent. Csak extrém nagy forgalom mellett érdemes előre kalkulálni.
Csak névfeloldás: Az Azure DNS nem kínál webtárhelyet vagy e-mail szolgáltatást, kizárólag a névkiszolgálást biztosítja.
Felhasználási esetek
Céges weboldal kezelése: Ha az alkalmazásaid Azure App Service-ben futnak, kényelmes a DNS-t is az Azure-ban kezelni.
Belső hálózatok: Privát DNS-zónák segítségével egyszerűbb a több Azure VNet összekapcsolása.
Globális alkalmazások: Az Azure DNS kombinálható az Azure Traffic Managerrel, így a felhasználók mindig a legközelebbi szerverhez jutnak.
DevOps folyamatok: Ha Terraformot vagy más IaC megoldást használsz, a DNS is ugyanabban a kódbázisban kezelhető, verziókövetve.
Mikor érdemes választani?
Már Azure-t használsz, és szeretnéd egy helyen kezelni az erőforrásaidat.
Fontos a magas rendelkezésre állás és a globális teljesítmény.
Nagyvállalati szintű biztonságra és jogosultságkezelésre van szükséged.
Összefoglalás
Az Azure DNS tehát modern, megbízható és biztonságos megoldás, amely lehetővé teszi, hogy a DNS-t is ugyanabban a felhőalapú környezetben kezeld, mint az alkalmazásaidat. Bár önmagában nem domain-regisztrátor, az App Service-tartományon keresztül domain is vásárolható, a .hu végződés kivételével. Ez a rugalmasság és integráció teszi különösen vonzóvá azoknak, akik már Azure környezetben dolgoznak.
Próbáld ki az Azure DNS-t saját projektedben, és tapasztald meg, milyen egyszerű a domain-kezelés a felhőben.
A modern világunkban az adat az egyik legértékesebb erőforrás. Az üzleti döntések, a marketingkampányok és a működés hatékonysága mind azon múlnak, hogy a szervezetek mennyire tudják kiaknázni a rendelkezésre álló információkat, mind időben, mind minőségben. Gondoljunk bele, a mesterséges intelligencia is a tengernyi adaton tud csupán jól és hatékonyan működni.
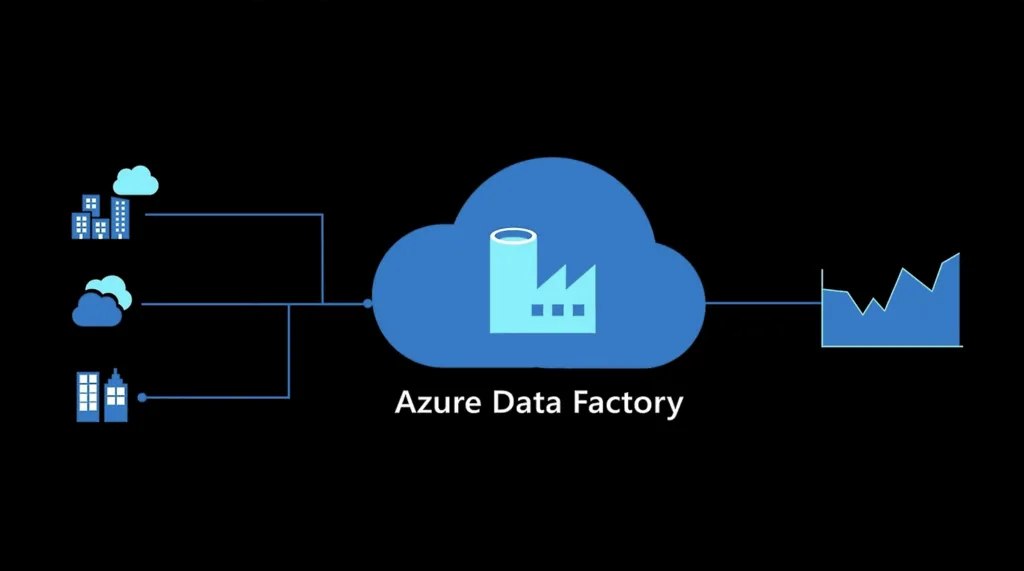
Az adatok azonban gyakran széttagoltak: különböző adatbázisokban, fájlokban, rendszerekben léteznek és legtöbbször eltérő formátumban. Emiatt szükségük van egy olyan eszközre, amely segít ezeket egységesíteni, megtisztítani, átalakítani és feldolgozni. Erre nyújt megoldást az Azure Data Factory (ADF), amely a Microsoft Azure-on érhető el.
Mi az Azure Data Factory?
Az Azure Data Factory egy felhőalapú ETL (Extract, Transform, Load) és ELT (Extract, Load, Transform) szolgáltatás. Lényege, hogy adatokat tud kinyerni (Extract) különböző forrásokból, azokat átalakítani (Transform), majd a célrendszerbe betölteni (Load). Ezzel hidat képez az eltérő rendszerek és az üzleti intelligencia eszközök között.
Mivel teljesen felügyelt szolgáltatás, a felhasználónak nem kell szerverek karbantartásával, skálázásával vagy szoftverfrissítésekkel foglalkoznia. Az ADF vizuális, drag-and-drop alapú felületet kínál, de támogatja az adatfolyamok kód alapú megírását is. Így mind az üzleti felhasználók, mind a fejlesztők megtalálhatják benne a számításaikat.
Egy nagytudású NoCode megoldás, amely segít az üzleti integrációban is, de kiszolgálja a fejlesztői igényeket is.
Főbb építőelemei
Pipeline (csővezeték): Egy adott adatfeldolgozási folyamat leírása, amely több lépésből is állhat.
Activity (tevékenység): Egy pipeline egy-egy művelete, például adatmozgatás vagy átalakítás.
Data Flow (adatfolyam): Kifejezetten adattisztításra és transzformációra szolgáló vizuális eszköz.
Linked Service (kapcsolódó szolgáltatás): Az adatforrás vagy a célrendszer konfigurációja, pl. SQL adatbázis vagy blob tárhely.
Dataset (adathalmaz): A feldolgozott adatok logikai egysége, amelyet egy pipeline vagy activity használ.
Ezek az építőelemek együtt adják az ADF rugalmasságát és sokoldalúságát.
Erősségei
Az Azure Data Factory legnagyobb előnye a széles körű integráció. Több mint 90 különböző adatforráshoz kínál beépített csatlakozót, amelyek között megtaláljuk az SQL adatbázisokat, CSV fájlokat, NoSQL rendszereket, API-kat vagy akár SAP rendszereket is.
Másik erőssége a skálázhatóság: akár kis mennyiségű adatot, akár petabájt méretű adathalmazokat is képes kezelni, anélkül, hogy a háttérben nekünk kellene erőforrást biztosítani.
Kiemelendő az adattisztítási képessége, amely lehetővé teszi a duplikált elemek kiszűrését, a hiányzó vagy hibás értékek javítását, és a különböző formátumok egységesítését. Ez rendkívül fontos, mert a tisztítatlan adatok gyakran félrevezető jelentésekhez és rossz üzleti döntésekhez vezethetnek.
Lehetőségei
Az ADF nemcsak egyszerű adatmozgatást, hanem komolyabb adatintegrációs feladatokat is támogat:
Automatizálás és ütemezés: Beállítható, hogy a pipeline-ok meghatározott időpontokban, például óránként vagy naponta fussanak.
Big Data feldolgozás: Az Azure Synapse Analytics-szel vagy a Databricks-szel kombinálva nagy mennyiségű adatot is képes feldolgozni.
Hybrid környezet támogatása: Nemcsak a felhőből, hanem hagyományos (on-premise) rendszerekből is be tud gyűjteni adatokat.
DevOps integráció: Támogatja a Git verziókezelést, így a folyamatok fejlesztése és karbantartása könnyebben követhető.
Monitorozás: Az ADF képes részletes log-okat és figyelmeztetéseket küldeni, hogy lássuk, mikor és hol futott hiba a folyamatban.
Korlátok
Bár sokoldalú, nem minden helyzetben a legjobb választás. Például:
A valós idejű feldolgozás csak korlátozottan érhető el, főként kötegelt feldolgozásra optimalizált.
A komplex logikai átalakítások esetében gyakran érdemes külső szolgáltatásokkal (pl. Databricks) kombinálni.
A költségek nagy mennyiségű adat esetén gyorsan növekedhetnek, így fontos a folyamatok optimalizálása.
Felhasználási esetek
Kereskedelmi vállalat: Egy online áruház a webes rendelések adatait, a raktárkészlet-információkat és a fizikai üzletek eladásait szeretné egy helyen elemezni. Az ADF összegyűjti az adatokat, megtisztítja azokat, majd az Azure Synapse Analytics-be tölti, ahol a menedzsment valós idejű riportokat készíthet.
Banki szektor: Egy bank különböző rendszerekből (tranzakciók, ügyféladatok, CRM) gyűjt adatokat, majd azokat normalizálja és tisztítja. Az így előkészített adatokból megbízható fraud detection modellek építhetők.
Gyártóipar: Egy gyártó cég különböző szenzorokból származó adatokat integrál az ADF segítségével, majd előkészíti azokat gépi tanulási modellekhez, amelyek előrejelzik a gépek meghibásodását.
Tanulság kezdőknek
Ha most ismerkedsz az adatintegráció világával, az Azure Data Factory kiváló belépési pont. Egyszerre biztosít vizuális, kódmentes megoldást és fejlesztőbarát rugalmasságot. A kulcs az, hogy először kisebb, egyszerűbb pipeline-okat hozz létre, majd fokozatosan bővítsd a tudásod összetettebb adatfolyamokkal és tisztítási feladatokkal.
A Mentor Klubban, 2025. szeptemberétől elérhető NoCode és LowCode megoldások Azure-ban és AWS-ben képzési anyagban is testközelből láthatod ennek működését.
Összegzés
Az Azure Data Factory ideális választás mindenkinek, aki adatvezérelt működésre szeretne átállni. Megbízhatóan kapcsolja össze a különböző rendszereket, tisztítja és feldolgozza az adatokat, majd elérhetővé teszi azokat riportokhoz, elemzésekhez vagy mesterséges intelligencia modellekhez. Bár vannak korlátai, a rugalmassága és az egyszerű kezelhetősége miatt az egyik legfontosabb adatfeldolgozó eszköz az Azure ökoszisztémában.
Én például a DJ fellépéseimhez szükséges zenei tárház elemeit szoktam ezzel tisztítani, mielőtt elküldöm a MAHASZ felé.
Az elmúlt hetekben rengeteg Kubernetes-el foglalkozó cikket zúdítottam már rátok. Ez nem fog változni a közeljövőben sem, azonban ma egy olyan Kubernetes szolgáltatást nézünk meg közelebbről, amely közben felhőszolgáltató specifikus is.
Azt már többször többféle módon is elmondtam, hogy a konténertechnológia forradalmasította a modern alkalmazásfejlesztést (a legismertebb konténertechnológiai megoldás a Docker): egyszerűbbé vált az alkalmazások csomagolása, szállítása és futtatása különböző környezetekben. Az Azure Kubernetes Service (AKS) ebbe a világba nyújt belépőt, méghozzá teljes mértékben menedzselt formában. A kezdők számára különösen előnyös, mert elrejti a komplexitás nagy részét, miközben erős kontrollt és rugalmasságot biztosít.
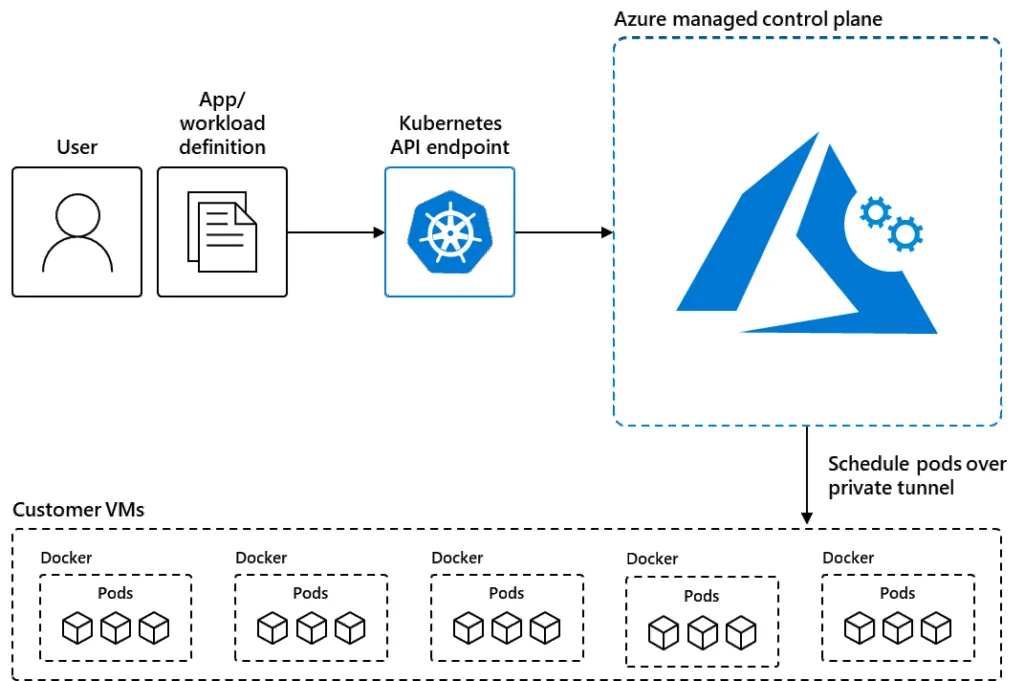
Mi az az Azure AKS? Az Azure Kubernetes Service (AKS) a MicrosoftAzure felhőplatformjának menedzselt Kubernetes-szolgáltatása. Lehetővé teszi konténerizált alkalmazások automatikus üzembe helyezését, kezelését, skálázását és monitorozását anélkül, hogy külön kellene gondoskodni a Kubernetes-fürt (cluster) telepítéséről és karbantartásáról.
Miért előnyös az AKS használata?
Menedzselt vezérlőréteg A Kubernetes vezérlőelemeit (control plane) teljesen menedzseli az Azure – így ezek frissítése, méretezése és biztonsági javítása nem a fejlesztőcsapat feladata.
Automatikus skálázás Támogatja a vízszintes pod-autoskalázást (HPA), node pool szintű autoskalázást, valamint a manualis skálázást is.
Integráció az Azure ökoszisztémával Könnyen integrálható más Azure szolgáltatásokkal, például Azure Monitor, Log Analytics, Key Vault, EntraID (Azure AD), vagy az Application Gateway-vel.
Támogatás Windows és Linux node poolokra Lehetőség van hibrid környezetek létrehozására is, ahol egyes szolgáltatások Windows, mások Linux konténerként futnak.
RBAC és identitáskezelés Az Azure AD integráció segítségével szabályozhatjuk, ki mit tehet a fürtben (Role-Based Access Control).
Frissítési stratégia testreszabása A cluster frissítések tervezetten, lépésenként is végrehajthatók, hogy minimalizáljuk a leállást.
Korlátok, amikkel érdemes számolni
Control Plane testreszabhatósága korlátozott Mivel menedzselt szolgáltatás, bizonyos alacsony szintű beállításokhoz nincs hozzáférés.
Sokféle beállítási lehetőség, ami összezavarhatja a kezdőket Bár a vezérlőréteg menedzselt, a node poolok, hálózatkezelés, tárolók és jogosultságok konfigurálása összetett lehet.
Hosszabb indulási idő A node poolok indulása néhány perctől akár 10-15 percig is eltarthat, főleg ha új skálázást kérünk.
Mikor érdemes az AKS-t választani? Az AKS ideális választás, ha:
Több mikroalkalmazást futtatnál egységes környezetben
DevOps pipeline-t szeretnél kiépíteni CI/CD-vel
Folyamatosan skálázódó alkalmazásokat futtatsz
Hosszú távon Kubernetes-es megközelítést szeretnél alkalmazni
Felhasználási példa: Webalkalmazás CI/CD pipeline-nal Egy több részből álló webalkalmazás (pl. frontend, backend, adatbázis) konténerizált formában van tárolva. Az alkalmazás képfájlai pedig az Azure Container Registry-ben (ACR).
Az AKS lehetővé teszi ezen konténerek fürtbe szervezését. GitHub Actions vagy Azure DevOps használatával CI/CD pipeline-t építhetünk, amely automatikusan telepíti és frissíti az alkalmazás egyes komponenseit a Kubernetes-fürtbe.
A forgalmat Azure Application Gateway vagy Ingress Controller segítségével lehet terelni, míg a logokat Azure Monitorban gyűjthetjük.
Milyen más Azure szolgáltatások támogatják még a Docker-konténereket? Bár az AKS a legteljesebb konténerkezelési megoldás, az Azure több más konténeres megoldást is kínál, amelyekről külön cikkekben olvashatsz:
Azure Arc-enabled Kubernetes: Saját Kubernetes-fürtök Azure-ból való menedzsmentje
Összefoglalás Az Azure Kubernetes Service (AKS) ideális választás azok számára, akik szeretnének skálázható, rugalmas, mikroszolgáltatás-alapú architektúrát kialakítani konténerek használatával, anélkül hogy a Kubernetes teljes komplexitásával kellene nap mint nap megküzdeniük. Az AKS lehetőséget ad a fejlődésre: kezdőként is elkezdhetjük, de haladó szintig is skálázhatjuk tudásunkat benne.
Azt azért megjegyezném, hogy egy AKS cluster fenntartása és üzemeltetése nem olcsó mulattság. Mielőtt kipróbálod, – márpedig ki kell próbálnod – ellenőrizd a díjkalkulátor segítségével, hogy mennyibe kerülne.
Itt a blogon sok konténer megoldásról és Docker megoldásról olvashattál már. Ez nem véletlen, hiszen ez a technológia rengeteg lehetőséget rejt, amelyek mind személyes, mind üzleti oldalon. A mikroszolgáltatásokat talán nem kell bemutatni, amely szintén a mai modern informatika egyik alap pillére. Gondolhatunk azonnal a Kubernetes-re, mert az a legnagyobb és legismertebb ezen a területen, de nem mindig van szükség ekkora komplexitásra, ha csupán egy-egy gyors alkalmazást szeretnénk futtatni. És itt jön képbe a mai cikkünk témája.
Az Azure Container Instance (ACI) egy felhőalapú szolgáltatás, amely lehetővé teszi, hogy konténereket futtassunk anélkül, hogy teljes környezetet – például virtuális gépet vagy Kubernetes-fürtöt – kellene telepítenünk és kezelnünk. Ideális választás lehet azok számára, akik egyszerűen, gyorsan és átmenetileg szeretnének konténeres alkalmazásokat futtatni.
Mi is az Azure Container Instance?
Az ACI a Microsoft Azure egyik platformszolgáltatása (PaaS), amely konténerizált alkalmazások futtatására alkalmas. Használata során nem kell foglalkoznunk az infrastruktúra kezelésével, csak megadjuk a konténerkép nevét (pl. egy Docker image), a kívánt erőforrásokat (CPU, memória), és az Azure elindítja számunkra a konténert.
Az Azure Container Instance támogatja a publikus Docker képeket a Docker Hub-ról és a Microsoft saját registry-jéből (pl. mcr.microsoft.com). Emellett használhatunk privát registry-ből (például Azure Container Registry vagy más hitelesített tároló) származó image-eket is, ha megadjuk a hozzáférési adatokat. Az kép forrását egyszerűen megadhatjuk az ACI létrehozásakor.
Előnyök és lehetőségek
Egyszerűség és gyorsaság Az ACI lehetővé teszi konténerek futtatását perceken belül. Nincs szükség cluster-re, orchestrator-ra vagy hosszadalmas konfigurálásra.
Rugalmasság Csak az erőforrások után fizetünk, amit ténylegesen használunk. Az ACI támogatja a Linux és Windows konténereket is.
Integráció Könnyedén kombinálható más Azure szolgáltatásokkal, például Azure Logic Apps, Functions, vagy akár Azure Virtual Network (VNET) integrációval is elérhetővé tehetjük belső rendszerekből.
Automatikus skálázás helyett egyszerű példányindítás Az ACI nem kínál automatikus horizontális skálázást, de nagyon jól használható, ha fix (előre megadott) példányszámmal vagy rövid élettartamú konténerekkel dolgozunk.
Korlátai
Nem alkalmas komplex, skálázható mikroszolgáltatás-architektúrák futtatására
Nincs beépített támogatás replikák, autoscaling vagy rollout stratégiák kezelésére
A konténerek állapota nem menedzselhető úgy, mint Kubernetes esetén (nincs önjavítás, nincs deployment stratégia)
Egyszerű összehasonlítás a Kubernetes-szel
Tulajdonság
Azure Container Instance
Azure Kubernetes Service (AKS)
Telepítési idő
percek
órák, akár komplex beállítások
Skálázás
manuális
automatikus, fejlett vezérlés
Infrastrukturális háttér
rejtett, Azure kezeli
felhasználó menedzseli részben
Tanulási görbe
alacsony
meredekebb
Üzemeltetés
minimális
összetett
Mikor érdemes használni az Azure Container Instance-ot
Az ACI kiváló választás, ha:
Egy egyszerű REST API-t vagy mikroalkalmazást szeretnénk gyorsan kipróbálni
Egyszeri vagy időszakos batch-feladatokat szeretnénk futtatni (pl. képfeldolgozás, adatkonvertálás)
CI/CD pipeline során szeretnénk ideiglenes build vagy teszt környezetet indítani
Kevés erőforrásigényű feladatokat szeretnénk futtatni felügyelet nélkül
Konkrét példa felhasználásra
Tegyük fel, hogy egy webalkalmazásban a felhasználók képeket töltenek fel, amelyeket különféle szűrőkkel kell feldolgozni. A képfeldolgozást egy konténerbe csomagolt Python script végzi, amelyet minden alkalommal újraindítunk, amikor egy új képet kapunk. Ilyen esetben ACI tökéletes, hiszen nem kell állandóan futtatnunk a feldolgozót, csak akkor, amikor valóban szükség van rá. Ráadásul mivel az erőforrásigény kicsi és futási idő rövid, költséghatékony is.
Próbáld ki Te is: saját konténer futtatása 5 perc alatt
Kattints a Felülvizsgálat + létrehozás, majd Létrehozás gombra
Pár perc múlva az ACI példány elkészül. Az elérési URL-t megkapod, például így nézhet ki: http://szia-laci.e5gsghbgaygzabaw.swedencentral.azurecontainer.io
Nyisd meg ezt az URL-t a böngésződben, és máris látni fogod a konténer által szolgáltatott weboldalt.
Összegzés
Az Azure Container Instance egy könnyen használható, gyors megoldás konténerek futtatására. Ideális kisebb feladatokhoz, teszteléshez, fejlesztéshez vagy időszakos folyamatokhoz. Ha azonban komplexebb architektúrában gondolkodunk, ahol skálázás, önjavítás, rollout kezelés is fontos, akkor érdemes a Kubernetes irányába tovább lépni.
Ez a technológia tökéletes belépő lehet azoknak, akik most ismerkednek a konténerekkel vagy éppen az Azure környezetet szeretnék kihasználni egyszerűbb alkalmazásokhoz. A portálos példa segít abban, hogy akár technikai háttértudás nélkül is sikerélményt szerezzünk az első konténerindítással.
A digitális szuverenitás fogalma az utóbbi években egyre hangsúlyosabban van jelen az európai technológiai diskurzusban. A Microsoft új bejelentése, a Sovereign Cloud kezdeményezés kibővítése, pontosan erre a növekvő igényre reagál: olyan felhőmegoldást kínál európai kormányzati és szabályozott iparági szereplők számára, amely nem csupán technológiai, hanem működési és jogi szinten is garantálja az adatok feletti kontrollt.
A digitális szuverenitás azt jelenti, hogy egy ország, intézmény vagy szervezet maga dönthet arról, hol és hogyan tárolja, dolgozza fel és védi meg a digitális adatait – anélkül, hogy külső szolgáltatók vagy más országok beleszólnának ebbe. Ez különösen fontossá vált az Európai Unióban, ahol a szabályozások egyre inkább előírják, hogy az adatkezelés az EU határain belül, helyi ellenőrzés alatt történjen.
Ez a megközelítés új mércét állíthat az adatbiztonság, a megfelelőség és a digitális függetlenség terén, különösen az Európai Unión belül. De mit is jelent ez a gyakorlatban? Miben más, mint az eddigi Azure-szolgáltatások? És miért éri meg ezzel foglalkozni cégeknek vagy állami intézményeknek?
Mi az a Microsoft Sovereign Cloud?
A Microsoft Sovereign Cloud olyan felhőszolgáltatások összessége, amelyeket kifejezetten a digitális szuverenitást komolyan vevő országok és szervezetek igényeire szabtak. Ezek a szolgáltatások lehetővé teszik, hogy az ügyfelek – jellemzően állami szervek, egészségügyi szolgáltatók, pénzintézetek és kritikus infrastruktúra üzemeltetők – teljes kontrollt gyakoroljanak adataik felett.
Ez nem csupán földrajzi lokalizációt jelent, hanem három fontos területre terjed ki:
Technológiai szuverenitás – Az adatok fizikailag az adott országban vagy régióban maradnak, és a feldolgozásuk is ott történik.
Operatív szuverenitás – Az ügyfelek, vagy azok helyi partnerei döntenek arról, ki férhet hozzá a rendszerekhez, akár a Microsoft hozzáférését is korlátozva.
Jogszabályi szuverenitás – A felhőszolgáltatások teljes mértékben megfelelnek az adott ország vagy régió adatvédelmi és iparági szabályozásainak.
A Microsoft az Európai Unióra különösen nagy hangsúlyt fektet: az új kezdeményezés célja, hogy segítsék az európai szervezeteket megfelelni az olyan komplex szabályozásoknak, mint a GDPR, a DORA (Digitális Reziliencia Szabályozás), a NIS2 (hálózatbiztonsági irányelv) és az EU Cloud Code of Conduct.
Alapelvek és működés
A Microsoft Sovereign Cloud nem önálló termék, hanem egy architektúra és szolgáltatási keretrendszer, amely a meglévő Microsoft Azure, Microsoft 365 és Dynamics 365 szolgáltatásokra épül, de kibővített kontroll- és biztonsági képességekkel.
Fő pillérei:
Adatszuverenitás és lokalizáció: Az adatok tárolása és feldolgozása kizárólag adott országban vagy régióban történik.
Hozzáférés-felügyelet: Az ügyfelek szabályozhatják, hogy a Microsoft rendszergazdái hozzáférhetnek-e az adatokhoz vagy sem.
Teljeskörű auditálhatóság: A felhasználók részletes naplózási és ellenőrzési eszközöket kapnak.
Szabályozási megfelelés támogatása: Az architektúra előre validált sablonokat és beállításokat tartalmaz az adott iparági előírásokhoz.
A Microsoft kiemeli, hogy nem egyedül nyújtja ezeket a megoldásokat: helyi partnerekkel – például kormányzati szervekkel, informatikai szolgáltatókkal – együttműködve hozza létre és működteti ezeket a rendszereket.
Miben különbözik az Azure-tól vagy más hagyományos felhőktől?
A Microsoft Azure alapvetően egy globális nyilvános felhő, amely regionálisan elérhető adatközpontokkal működik. Bár kínál lehetőséget az adatok lokalizációjára (pl. európai régió választása), a szolgáltatás alaplogikája szerint a Microsoft infrastruktúráján, az ő irányítása alatt történik minden.
A Sovereign Cloud ezzel szemben:
Szigorúan korlátozza az adatáramlást a megadott földrajzi határokon belül
Teljes ügyfélkontrollt biztosít a hozzáférések felett (még a Microsoft saját adminjai felett is)
Lokális partneri működtetést tesz lehetővé, például állami informatikai ügynökséggel együtt
Dedikált megfelelőségi sablonokat és auditálási lehetőségeket kínál, különösen az állami, egészségügyi vagy pénzügyi szektor számára
Egy másik fontos különbség, hogy az Azure hagyományosan a skálázhatóságot és globális elérhetőséget helyezi előtérbe, míg a Sovereign Cloud a szabályozási és működési megfelelést maximalizálja – még akkor is, ha ez a globális rugalmasság csökkenésével jár.
Erősségek: miért előnyös ez a megoldás?
Teljes kontroll az adatok felett: a felhasználó dönt, hogy ki, mikor, hogyan férhet hozzá
Szabályozásnak való megfelelés egyszerűbbé válik, akár komplex ágazati előírások esetén is
Transzparencia és auditálhatóság: világosan nyomon követhető minden tevékenység
Helyi partnerekkel működik együtt, ami növeli az elfogadottságot és a nemzeti kontrollt
Rugalmas modell: lehetőség van önálló vagy együttműködésen alapuló működésre is
Lehetőségek: kinek ajánlott?
A Microsoft Sovereign Cloud elsősorban azoknak a szervezeteknek készült, amelyek érzékeny adatokkal dolgoznak, és:
Jogszabály kötelezi őket a szuverén működésre (pl. kormányzati intézmények)
Kritikus infrastruktúrát kezelnek (pl. közművek, közlekedés)
Pénzügyi, egészségügyi vagy védelmi ágazatban működnek, ahol a digitális függetlenség elsődleges fontosságú
A magánszektorban is egyre több szervezet vizsgálja ennek lehetőségét, főleg ha nemzetbiztonsági vagy reputációs kockázatot jelenthet az adatkezelés kiszervezése.
Korlátok és kihívások
Magasabb üzemeltetési költség: a lokalizált működés és a megnövekedett kontroll többletkiadással járhat
Kisebb rugalmasság és globális elérhetőség, mivel az adatok szigorúan izolált környezetben maradnak
Technikai összetettség: nem minden szervezet rendelkezik az ehhez szükséges tudással és kapacitással
A megosztott felelősség modell továbbra is érvényes: a Microsoft csak a szolgáltatást biztosítja, az adatbiztonság egy része a felhasználó felelőssége marad
Mit jelent ez nekünk, felhasználóknak és cégeknek?
Felhasználóként egyre több olyan digitális szolgáltatást használunk, ahol személyes vagy érzékeny adatokat adunk meg – legyen szó állami ügyintézésről, egészségügyi nyilvántartásról vagy pénzügyi tranzakciókról. A Sovereign Cloud modell garantálja, hogy ezek az adatok nem kerülnek ki az ország vagy az EU határain kívülre, és azok felett kizárólag az általunk felhatalmazott szervezetek gyakorolhatnak kontrollt.
Céges oldalon ez versenyelőnyt is jelenthet: egy olyan szolgáltatóval dolgozni, amely képes a legszigorúbb adatvédelmi előírásoknak is megfelelni, bizalmat épít az ügyfelekben, partnerekben, hatóságokban.
És mi a helyzet az AWS-el?
Nem csak a Microsoft ismerte fel a digitális szuverenitás növekvő jelentőségét. Az Amazon Web Services is dolgozik saját szuverén felhőmegoldásán, különösen Sovereign-by-Design szemlélettel. Az AWS célja hasonló: lehetőséget biztosítani a kormányzati és szabályozott szektor szereplőinek arra, hogy adataikat teljes mértékben földrajzilag és működésileg is kontroll alatt tarthassák, akár a szolgáltató beavatkozása nélkül is.
A tervek szerint az AWS Európában is olyan felhőkörnyezeteket épít, amelyekben:
Az adatok tárolása és feldolgozása kizárólag uniós területen történik
A hozzáférési jogokat kizárólag az ügyfelek (vagy az általuk kijelölt partnerek) szabályozzák
A szolgáltatások megfelelnek az olyan szabályozásoknak, mint a GDPR, NIS2, DORA
Bár az AWS még nem indította el széles körben a szuverén felhőszolgáltatását, a bejelentett tervek jól mutatják, hogy a „szuverén felhő” nem egy gyártói hóbort, hanem az egész iparág új irányvonala. Ez hosszú távon a felhasználóknak kedvez: versenyhelyzetet teremt, ahol a nagy szolgáltatók egyre biztonságosabb, átláthatóbb és szabályozásbarátabb megoldásokat kínálnak.
Összegzés
A Microsoft Sovereign Cloud nem csupán technológiai újítás, hanem stratégiai válasz Európa digitális szuverenitási törekvéseire. A felhőszolgáltatások következő generációját képviseli, ahol nem csupán a skálázhatóság és rugalmasság számít, hanem a kontroll, a megfelelőség és a biztonság is.
Azoknak a szervezeteknek, akik nem engedhetnek meg maguknak kompromisszumot az adatok feletti uralom terén, ez a megközelítés nem lehetőség, hanem szükségszerűség.