Kubernetes workload: DaemonSet, StatefulSet, Autoscaling
A Kubernetes számomra egy megunhatatlan téma. Nem csupán azért, mert a mikroszolgáltatások futtatásának központi eleme, hanem egy olyan izgalmas világ, ami komplexitása ellenére, logikusan működik.
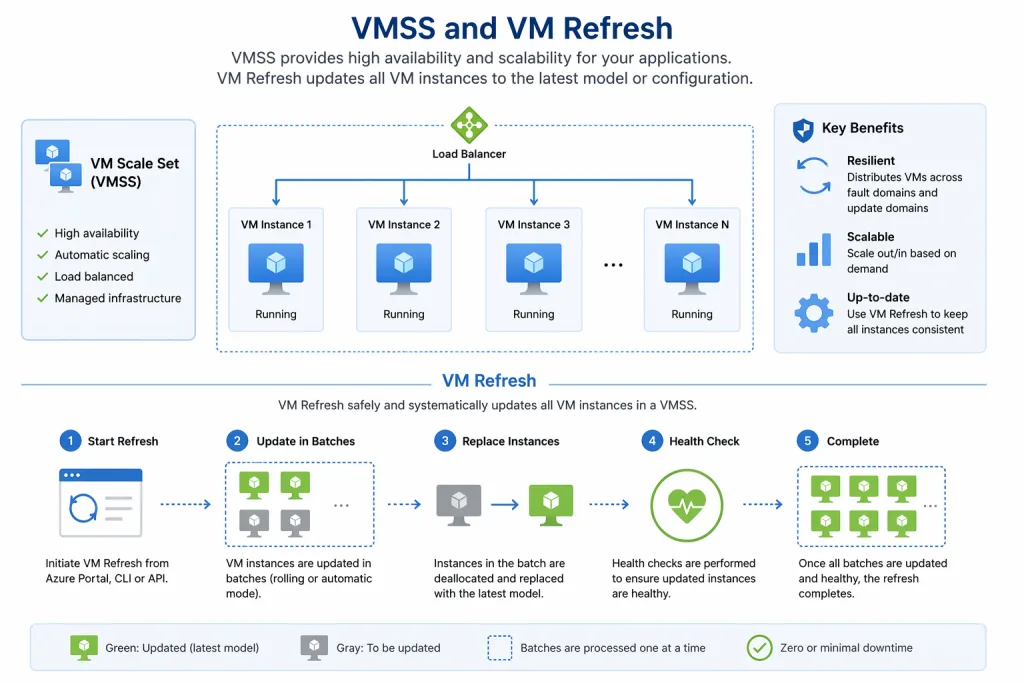
A vállalatok digitális jelenlétének erősítésében ma már kulcsszerepet játszik az, hogy az alkalmazások gyorsan telepíthetők, skálázhatók és megbízhatóan működtethetők legyenek. A Kubernetes pontosan erre van kitalálva. Egy jól felépített rendszerben az alkalmazások nem egyetlen szerveren futnak, hanem egy cluster több node-ján oszlanak el. Ez a megközelítés nemcsak nagyobb rendelkezésre állást biztosít, hanem lehetővé teszi a dinamikus skálázást és az automatizált működést is.
Ma néhány olyan Kubernetes API objektumot fogunk megnézni, amelyek az alkalmazások futtatásának és működtetésének alapját jelentik. Ezek az objektumok határozzák meg, hogyan indulnak el a Pod-ok, hogyan skálázódnak az alkalmazások, hogyan futnak batch feladatok, illetve hogyan kezelhető a hozzáférés a cluster erőforrásaihoz.
Deployment és az alkalmazások telepítése
Amikor egy alkalmazást telepítünk Kubernetes-ben, ritkán hozunk létre közvetlenül Pod-ot. A gyakorlatban szinte mindig egy magasabb szintű vezérlő objektumot használunk.
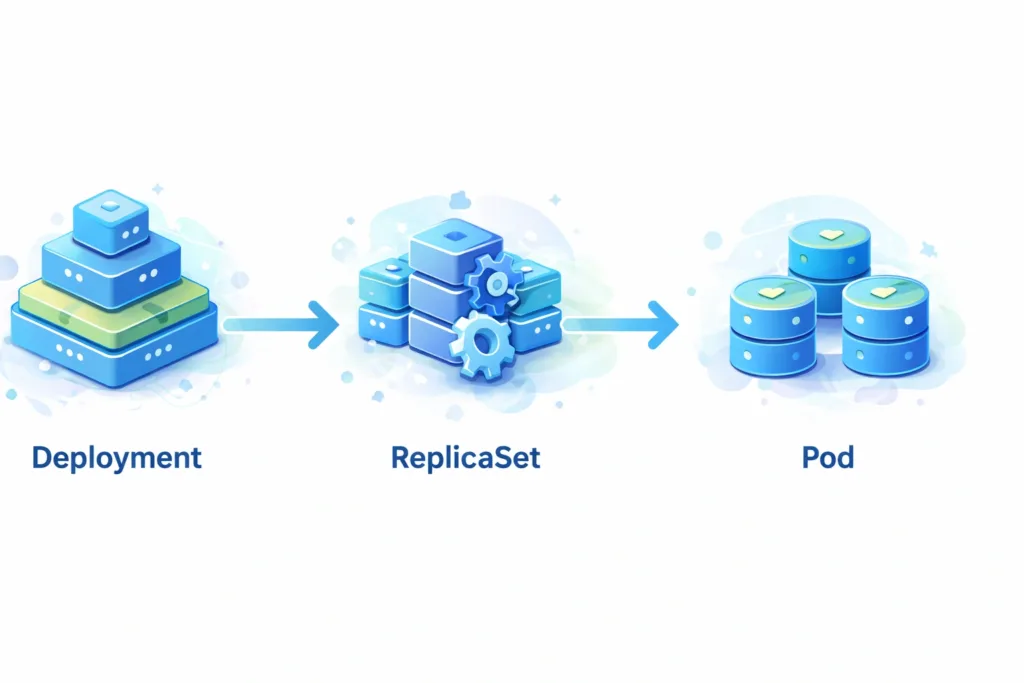
A leggyakoribb ilyen objektum a Deployment. A Deployment egy controller, amely a ReplicaSetek és a Podok állapotát kezeli. Ez a magasabb szintű absztrakció lehetővé teszi, hogy az alkalmazások frissítése, skálázása és adminisztrációja rugalmasabb legyen.
A működés láncolata a következő:
Deployment → ReplicaSet → Pod
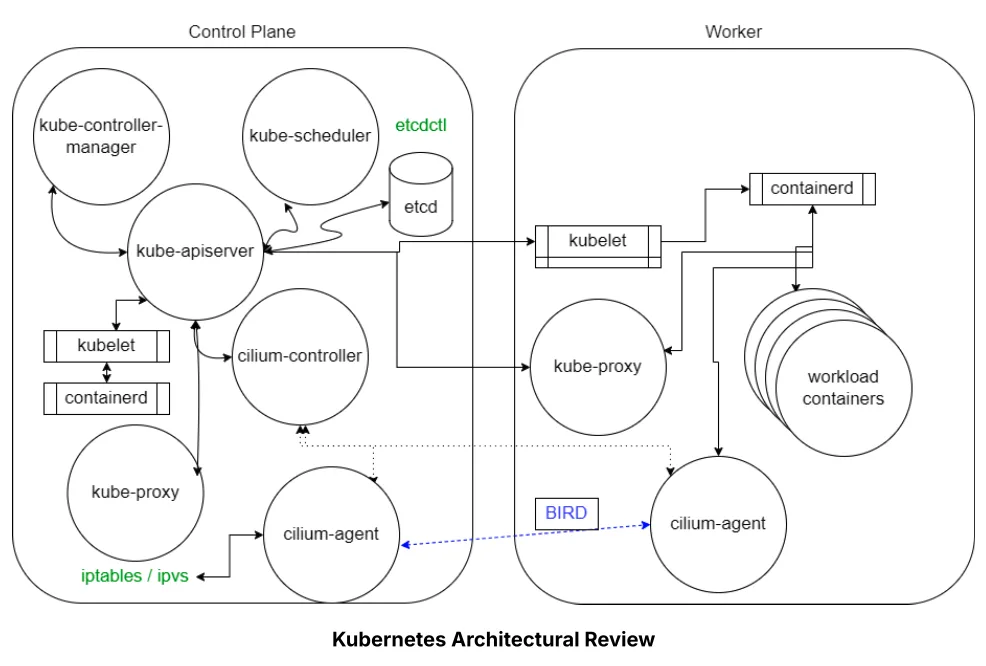
A Pod a Kubernetes legkisebb kezelhető egysége. Egy Pod tipikusan egy vagy több konténert tartalmaz, amelyek együtt futnak és ugyanazt a hálózati valamint tárolási környezetet használják.
A ReplicaSet feladata, hogy biztosítsa a kívánt számú Pod folyamatos működését. Ha például három Pod futását határozzuk meg, a ReplicaSet gondoskodik arról, hogy mindig három példány fusson. Ha egy Pod leáll, a rendszer automatikusan újat indít.
A Deployment ezen a szinten egy további irányítási réteget ad. Lehetővé teszi például a rolling update frissítéseket, amikor az új verziók fokozatosan kerülnek bevezetésre anélkül, hogy az alkalmazás leállna.
DaemonSet: Pod minden node-on
Bizonyos típusú alkalmazásoknak minden node-on futniuk kell egy clusterben. Erre szolgál a DaemonSet.
A DaemonSet biztosítja, hogy egy adott Pod minden node-on fusson a clusterben. Amikor egy új node kerül a clusterbe, a DaemonSet automatikusan elindítja rajta a megfelelő Podot. Amikor pedig egy node eltávolításra kerül, a hozzá tartozó Pod is megszűnik.
Ez a megközelítés különösen hasznos olyan rendszerszintű komponensek esetében, mint például:
- loggyűjtő rendszerek
- monitoring agentek
- biztonsági ellenőrző komponensek
Ezeknek az alkalmazásoknak minden node-on jelen kell lenniük ahhoz, hogy teljes képet kapjanak a cluster állapotáról.
StatefulSet: állapotot kezelő alkalmazások
A legtöbb konténeres alkalmazás stateless módon működik, vagyis a Podok felcserélhetők. Egy Pod megszűnése vagy újraindulása nem jelent problémát.
Vannak azonban olyan alkalmazások, ahol a Pod identitása fontos. Ilyenek például az adatbázisok.
Ezek kezelésére szolgál a StatefulSet. A StatefulSet olyan Kubernetes workload objektum, amely állapotot kezelő alkalmazások működtetésére készült.
A StatefulSet egyik legfontosabb tulajdonsága, hogy minden Pod egyedi identitással rendelkezik. Ez az identitás három elemből áll:
- stabil tároló
- stabil hálózati azonosító
- sorszámozás (ordinal)
A Podok tipikusan sorban indulnak el, például:
- app-0
- app-1
- app-2
Az új Pod csak akkor indul el, ha az előző már sikeresen fut. Ez eltér a Deployment viselkedésétől, ahol a Pod-ok párhuzamosan indulnak.
Ez a viselkedés kulcsfontosságú olyan rendszerek esetében, ahol az indulási sorrend vagy az állapotmegőrzés kritikus.

Autoscaling: automatikus skálázás
A Kubernetes egyik legerősebb képessége az automatikus skálázás.
Az egyik leggyakrabban használt megoldás a Horizontal Pod Autoscaler, röviden HPA. Ez az objektum automatikusan növeli vagy csökkenti a Podok számát egy Deployment, ReplicaSet vagy Replication Controller esetében.
Alapértelmezés szerint a HPA a CPU használat alapján skáláz. Ha a CPU kihasználtság eléri a 80 százalékot, a rendszer új Pod-okat indíthat. A metrikákat a kubelet gyűjti, majd a Metrics Server API-n keresztül érhetők el.
Amikor több Pod-ra van szükség, a rendszer azonnal reagál. Ha viszont csökkenteni kell a Pod-ok számát, a HPA alapértelmezés szerint 300 másodpercet vár, mielőtt új döntést hozna.
A Kubernetes-ben létezik egy másik autoscaling mechanizmus is, a Cluster Autoscaler. Ez már nem Pod-okat, hanem node-okat kezel.
Ha egy Pod nem helyezhető el a cluster-en a rendelkezésre álló erőforrások miatt, a Cluster Autoscaler új node-okat hozhat létre. Ha pedig a node-ok kihasználtsága alacsony, a rendszer idővel eltávolíthatja őket.
Ez különösen fontos felhő környezetben, ahol a nem használt erőforrások költséget jelentenek.
Jobs és CronJobs
Nem minden Kubernetes workload egy folyamatosan futó alkalmazás.
Vannak olyan feladatok, amelyeknek csak egyszer kell lefutniuk, vagy meghatározott időpontokban kell végrehajtódniuk. Erre szolgálnak a Job és a CronJob objektumok.
A Job egy batch feldolgozási mechanizmus, amely meghatározott számú Pod sikeres lefutását biztosítja. Ha egy Pod hibával áll le, a rendszer újraindítja addig, amíg a feladat sikeresen be nem fejeződik.
A Job specifikációjában két fontos paraméter található:
- parallelism: ez határozza meg, hogy hány Pod futhat egyszerre.
- completions: hány sikeres futás szükséges a Job befejezéséhez.
A CronJob a Linux cron működéséhez hasonló időzített futtatást biztosít. Ugyanazt az időszintaxist használja, így például könnyen létrehozható egy napi vagy óránként futó feladat.
Fontos megjegyezni, hogy egy CronJob esetében a futó Podnak idempotensnek kell lennie, mert bizonyos esetekben előfordulhat, hogy egy feladat kétszer is elindul.
RBAC: hozzáférések kezelése
Egy Kubernetes clusterben a biztonság és a hozzáféréskezelés kulcsfontosságú kérdés.
Erre szolgál az RBAC, vagyis a Role Based Access Control rendszer.
Az RBAC négy fő erőforrást használ:
- Role (szerepkör)
- ClusterRole (cluster szintű szerepkör)
- RoleBinding (szerepkör-hozzárendelés)
- ClusterRoleBinding (cluster szintű szerepkör-hozzárendelés)
Ezek segítségével meghatározhatjuk, hogy egy felhasználó vagy szolgáltatás milyen műveleteket hajthat végre a cluster-ben.
Például létrehozhatunk egy Role-t, amely csak Pod-ok olvasását engedélyezi egy adott namespace-ben. Egy másik Role pedig lehetőséget adhat Deployment objektumok létrehozására, de például Service objektumokra már nem.
A RoleBinding és a ClusterRoleBinding feladata az, hogy ezeket a szerepköröket felhasználókhoz vagy szolgáltatásfiókokhoz rendeljék.
Ez a modell lehetővé teszi a legkisebb szükséges jogosultság elvének alkalmazását, ami alapvető biztonsági gyakorlat a modern infrastruktúrákban.
Összegzés
A Kubernetes működésének megértéséhez elengedhetetlen az API objektumok ismerete. A Deployment, DaemonSet, StatefulSet, Job, valamint az autoscaling és az RBAC mind olyan alapvető építőelemek, amelyek meghatározzák, hogyan futnak és működnek az alkalmazások egy clusterben.
A Deployment segít az alkalmazások verziókezelésében és skálázásában. A DaemonSet biztosítja a node-szintű komponensek működését. A StatefulSet lehetővé teszi az állapotot kezelő rendszerek stabil működését. A Job és a CronJob batch feldolgozási feladatokat old meg, míg az autoscaling mechanizmusok a dinamikus terheléshez igazítják az infrastruktúrát.
Végül az RBAC gondoskodik arról, hogy a hozzáférések biztonságosan és kontrollált módon legyenek kezelve.
Ha megértjük ezeknek az objektumoknak a szerepét, akkor már nemcsak alkalmazásokat tudunk futtatni Kubernetesben, hanem valóban képesek leszünk megbízható, skálázható és biztonságos rendszereket építeni.