AWS Spot instance – Felhőalapú számítás költséghatékonyan
- Erőforrás típus: IaaS
- Felhő szolgáltató: Amazon Web Services
- Angol név: EC2 Spot Instance
- Magyar név: EC2 Spot Instance
- Rövidített név (ha van ilyen): Spot Instance
Ahogy a legutóbbi cikkemben írtam a felhőben időről-időre lesznek olyan fel nem használt szabad kapacitások, amelyek bizonyos szempontból veszteséget termelnek a szolgáltatónak. Kíváncsi vagyok, vajon azóta megismerd-e az Azure Spot VM-et. Ennek párja az AWS-ben az EC2 Spot Instance (röviden: Spot Instance). Ma ezt szeretném nektek bemutatni kicsit közelebbről, hátha kedvet kaptok és kipróbáljátok, vagy éppen olyan projekten dolgoztok, ahol ez a tökéletes választás.
Tehát az Amazon Web Services (AWS) is lehetőséget kínál arra, hogy akár 90%-kal olcsóbban használjunk számítási erőforrásokat – ez a Spot instance. Ez a lehetőség különösen vonzó lehet fejlesztőknek, startupoknak és minden olyan technológiai csapatnak, amely rugalmas workload-okon dolgozik, és szeretné optimalizálni az infrastruktúra költségeit.
Mi az az AWS Spot instance?
Az AWS Spot instance olyan virtuális gép (EC2 instance), amit az AWS fel nem használt kapacitásából kínál. Mivel ezek az erőforrások „feleslegesek”, az áruk jelentősen alacsonyabb, mint az on-demand (igény szerinti) vagy reserved instance-oké.
A felhasználók licitálás nélkül, rugalmas áron vehetnek igénybe Spot Instance-okat, és az AWS bármikor visszavonhatja őket, ha a kapacitásra másnak van szüksége. Ezért a Spot instance nem minden megoldáshoz ideális – de bizonyos esetekben hatalmas előnyt jelent.
Mikor érdemes Spot instance-ot használni?
A Spot instance különösen hasznos olyan feladatoknál, amelyek:
- Nem időkritikusak (azaz nem okoz üzletileg kárt, ha a gép leáll)
- Hibamentesen újraindíthatók vagy megszakíthatók
- Rugalmasan skálázhatók (automatikus skálázás, kézi beavatkozás nélkül)
- Rövid ideig tartanak vagy batch jellegűek (20 perc – 1 órás feladatok, vagy olyan tömegesen futtatandó script-ek amelyeknek rövid időre nagy számítási kapacitásra van szüksége. Pl.: CI/CD pipeline-ok, konténeres munkafolyamatok)
- Párhuzamosíthatók (pl. batch feldolgozás)
Ár és megtakarítás
A legnagyobb előny az ár: Spot instance-ok akár 70-90%-kal olcsóbbak lehetnek az on-demand áraknál. Az ár dinamikusan változik a kereslet-kínálat alapján, de nem kell manuálisan licitálni – az AWS automatikusan a legalacsonyabb aktuális áron biztosítja az erőforrást.
Korlátok és kockázatok
A Spot instance legnagyobb hátránya a bizonytalan rendelkezésre állás. Ha az AWS-nek szüksége van az erőforrásra, akkor értesítést küld a leállításról, és 2 percen belül leállítja az instance-ot. Ezért fontos olyan megoldásokat futtatni rajta, amelyek képesek kezelni ezt a megszakítást.
További korlátok:
- Nem garantált a futási idő (lehet hogy több hét, lehet hogy csak egy óra)
- Egyes régiókban vagy instance típusoknál korlátozott a kapacitás
- Nincs SLA (Service Level Agreement) garancia Spot instance-ra
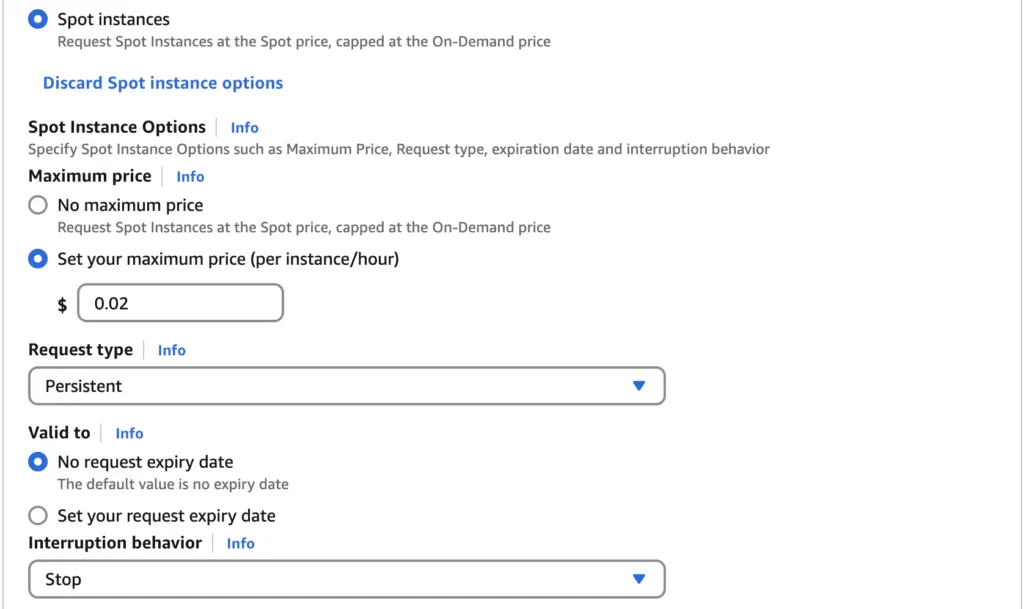
Hol lehet használni Spot instance-okat?
A Spot instance-ok nem csak egyedi EC2 példányokhoz érhetők el. Az AWS világa számos olyan szolgáltatást kínál, ahol beépítve használhatjuk a Spot kapacitást – akár automatikus méretezéssel, konténerkezeléssel vagy teljesen menedzselt környezetekkel kombinálva. Íme néhány jelentős terület:
1. EC2 Auto Scaling Group (ASG)
Az Auto Scaling Group lehetővé teszi vegyes példánytípusok és ármodellek használatát. Például beállíthatjuk, hogy a csoport 70%-a Spot, 30%-a on-demand példányokból álljon. A rendszer automatikusan pótlást végez, ha egy Spot példány megszűnik.
2. Elastic Beanstalk
A Beanstalk egy platformszintű szolgáltatás, amely leegyszerűsíti az alkalmazások telepítését. Beállítható, hogy a háttérben futó EC2 példányok részben vagy teljesen Spot instance-ok legyenek. Ez ideális webalkalmazások költséghatékony futtatásához.
3. Amazon EKS (Elastic Kubernetes Service)
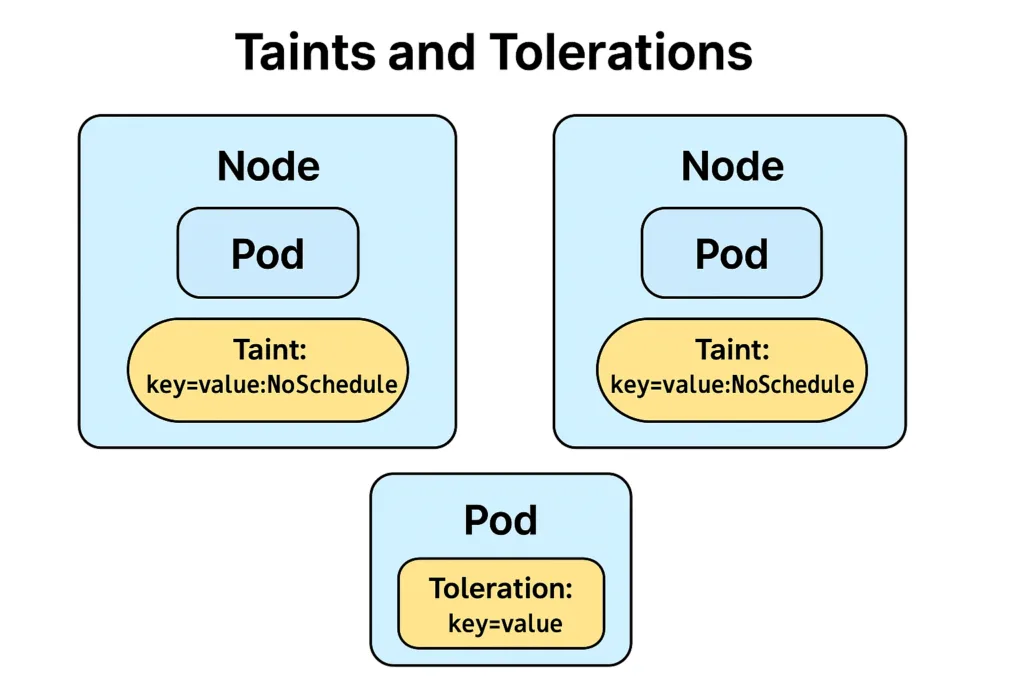
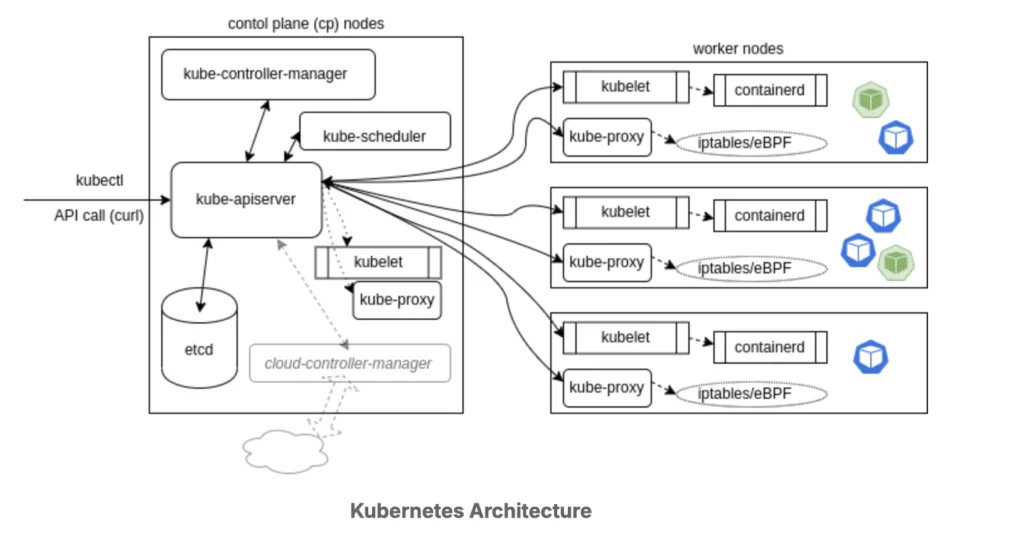
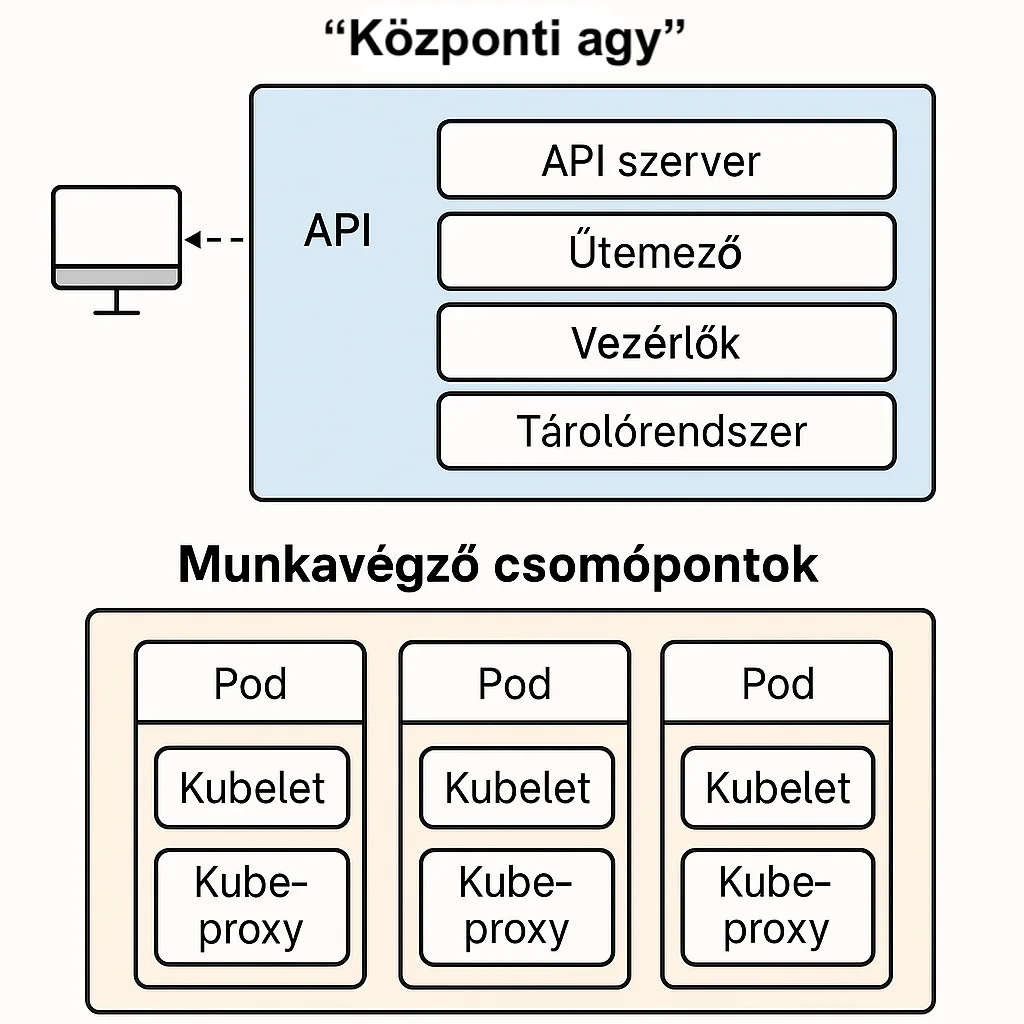
Az EKS Kubernetes klasztereknél támogatja a Spot alapú node-okat. Vegyes node pool segítségével lehetőség van kevésbé kritikus podokat Spot gépekre ütemezni, míg fontos szolgáltatásokat on-demand node-okon futtatunk.
4. AWS Batch
Az AWS Batch egy batch-alapú feldolgozási szolgáltatás, amely automatikusan skálázza az erőforrásokat – beleértve a Spot instance-okat is. Ez ideális például tudományos szimulációk, nagy volumenű renderelés vagy adatelemzés során.
5. Amazon EMR (Elastic MapReduce)
EMR használható Spot instance-okra építve is, főleg Hadoop, Spark vagy Presto alapú analitikai feladatokra. A nem kritikus worker node-ok Spot alapon futtathatók, míg a master node on-demand példány lehet a stabilitás érdekében.
6. Amazon ECS (Elastic Container Service)
Konténeres környezetben, főleg Fargate spot üzemmóddal vagy EC2 alapú klaszterekben, költséghatékonyan futtathatók konténerek Spot instance-okon, ideális CI/CD pipeline-okhoz vagy rövid életű mikroszolgáltatásokhoz.
7. SageMaker
A SageMaker modellek tanításánál is használható Spot training, amely jelentős költségcsökkentést kínál hosszabb, erőforrás-igényes tréning folyamatok során. Az AWS automatikusan menti az állapotot és folytatja, ha egy Spot gép kiesik.
8. Dev/Test környezetek
Fejlesztési és tesztelési környezetek gyakran nem kritikusak – ideális jelöltek a Spot instance-alapú futtatásra. Automatikusan indíthatók, leállíthatók és újraindíthatók anélkül, hogy ez éles rendszereket veszélyeztetne.
9. CI/CD pipeline-ok
Build, teszt és deploy pipeline-ok gyakran futnak rövid ideig és gyakran – ezek kiválóan optimalizálhatók Spot példányokkal, főleg ha konténeres vagy serverless architektúrában futnak.
10. Gépi tanulás, renderelés, transzkódolás
Minden olyan folyamat, ami párhuzamosítható, szakaszos és újraindítható – például videók transzkódolása, képfeldolgozás vagy gépi tanulásos modellek tanítása – ideálisan futtatható Spot példányokon.
Hogyan lehet biztonságosan használni?
- Spot Fleet vagy Auto Scaling Group
Automatikusan kezeli az elérhető Spot instance-okat, és ha kell, más instance típussal pótolja. - Checkpointing
A folyamat időszakos mentése lehetővé teszi a gyors visszaállást. - Mixed Instance stratégia
Kombinálható on-demand és Spot példányokkal egy szolgáltatás, így növelve a rendelkezésre állást. - Containerizáció és Kubernetes
A konténeres architektúrák, különösen az EKS, ideálisan kezelik a dinamikusan változó Spot környezeteket.
Összefoglalás
Az AWS Spot instance egy kiváló eszköz azoknak, akik költséghatékonyan szeretnék működtetni nem kritikus feladataikat a felhőben. Bár kompromisszumot igényel a rendelkezésre állás terén, megfelelő architektúrával és tervezéssel rengeteg pénzt lehet vele megtakarítani.
A Spot instance-ok ma már szinte minden jelentős AWS szolgáltatásba integrálhatók. Nem csak a költségek csökkentését szolgálják, hanem lehetőséget nyújtanak a rugalmas, skálázható és optimalizált architektúrák kialakítására is.
A kulcs a tudatos tervezés – meg kell érteni, hol van szükség állandó rendelkezésre állásra, és hol engedhetjük meg a rugalmas, megszakítható infrastruktúrát.