Amazon S3 Vektorok: új korszak az adatok keresésében
Eddig is úgy gondoltam, hogy az Amazon S3 a világ legjobb felhő tárolási megoldása, hiszen olyan széleskörűen, egyszerűen és költséghatékonyan használható, hogy azzal magasan lekörözi versenytársait.
Teszi ezt úgy, hogy az AI megjelenésével továbbra is az egyik legszélesebb körben használható tárolási megoldás maradt. Az Amazon azonban nem elégedett meg ezzel, hanem tovább dolgozott és nemrég be is jelentették, hogy az Amazon S3 mostantól natívan támogatja a vektorokat.
Ez nem csupán egy egyszerű frissítés, hanem egy komoly lépés afelé, hogy az AI-alapú keresések és alkalmazások még gyorsabbak és hatékonyabbak legyenek, ráadásul közvetlenül ott, ahol az adatokat tároljuk: az S3-ban.
Mi is az az Amazon S3 Vector?
Az Amazon S3 Vector egy új lehetőség arra, hogy vektorokat – azaz gépi tanulási modellekből származó tömörített adatreprezentációkat – natívan tároljak és kereshetővé tegyek az S3-ban. Korábban, ha például képeket, szövegeket vagy videókat szerettem volna hasonlóság alapján keresni, az adataimat először külön vektor adatbázisba kellett töltenem (pl. Weaviate), ahol a hasonlóságkeresést elvégezhettem. Mostantól ez közvetlenül az S3-ban is elérhető.
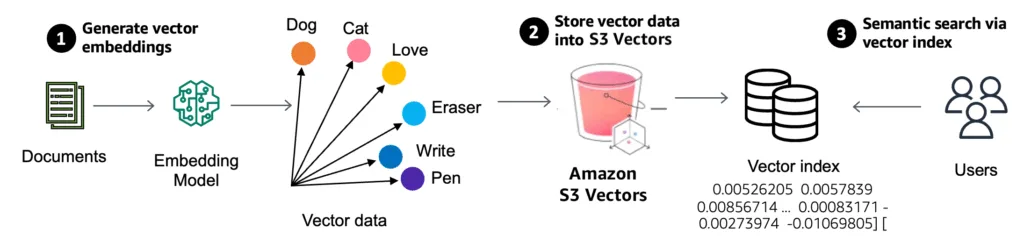
Ez hatalmas előrelépés – nemcsak egyszerűsíti az architektúrát, hanem csökkenti a késleltetést, az összetettséget és a költségeket is.
Hogyan működik?
Az S3 Vector a meglévő Amazon S3 Express One Zone tárhelyre épül, és három fontos komponenst kínál:
- Vector Store (vektortár) – Ebbe töltöm fel a vektorokat és a hozzájuk tartozó metainformációkat.
- Ingest API – Ezen keresztül adhatom meg a vektorokat és az indexelendő adatokat.
- Query API – Ezzel tudok hasonlóság alapján keresni (pl. „melyik képek hasonlítanak erre a képre?”)
Minden vektor egy rekord részeként kerül be, amely lehetővé teszi, hogy ne csak vektor alapján, hanem metaadatok szerint is tudjak szűrni, például dátum, fájltípus vagy címke alapján.
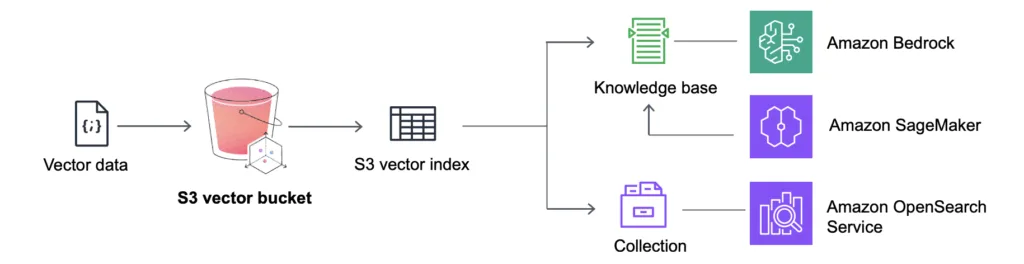
Példák a használatra
1. Dokumentumkeresés
Egy nagy mennyiségű belső dokumentumot tartalmazó gyűjteményben szerettem volna hasonló jelentésű dokumentumokat megtalálni. Ahelyett, hogy kulcsszavas keresést használtam volna, minden dokumentumhoz vektort generáltam egy nyelvi modell segítségével, és azokat töltöttem fel az S3 Vectorba.
Ezután egy új keresés során elég volt megadnom egy kérdést vagy egy rövid szövegrészletet – és az S3 azonnal visszaadta azokat a dokumentumokat, amelyek a legjobban illeszkedtek a jelentésük alapján.
2. Képalapú hasonlóságkeresés
Egy e-kereskedelmi oldalon képek alapján szerettem volna hasonló termékeket ajánlani. A termékfotókat vektorizáltam egy gépi látás modell segítségével, majd betöltöttem az S3 Vectorba. Így amikor egy vásárló feltöltött egy képet, a rendszer pillanatok alatt megtalálta a hozzá leginkább hasonlító termékeket – anélkül, hogy külön vektor-adatbázist kellett volna karbantartanom.
Miben más ez, mint a meglévő megoldások?
A legtöbb vektoros keresési rendszer eddig úgy működött, hogy külön adatbázist kellett használni (pl. Pinecone, Weaviate, FAISS, Qdrant). Ez viszont újabb infrastruktúrát, szinkronizációs feladatokat és összetettebb architektúrát igényelt. Az Amazon S3 Vector ezt az egészet leegyszerűsíti: egy helyen tárolom és keresem az adatokat.
Azt is kiemelném, hogy mivel az S3 Vector az Express One Zone megoldásra épül, ezért alacsony késleltetésű hozzáférést kapok – mindezt az S3 skálázhatóságával és megbízhatóságával együtt.
Korlátok és tudnivalók
Természetesen nem minden esetben ez a legjobb megoldás. A jelenlegi verzió:
- csak az S3 Express One Zone-on keresztül működik,
- maximum 250 kB méretű rekordokat támogat,
- és előzetes (preview) státuszban van, így még nem éles környezetbe szánt végleges termék.
A vektorok betöltéséhez és a keresésekhez is REST API-t használhatok, de egyelőre nincs közvetlen AWS konzolos támogatás.
Mikor érdemes használni?
Én akkor fogom választani az S3 Vector-t, ha:
- már eleve S3-ban tárolok adatokat (képeket, szövegeket),
- AI-alapú hasonlóságkeresésre van szükségem,
- és szeretném leegyszerűsíteni az architektúrát, elkerülve a külön vektor-adatbázisokat.
Összegzés
Az Amazon S3 Vector egy fontos mérföldkő a natív, felhőalapú AI-alkalmazások területén. Ha te is vektoros keresést építenél, és az adataid már most is S3-ban vannak, akkor ez egy kiváló lehetőség arra, hogy gyorsan és hatékonyan vezess be intelligens keresési képességeket – közvetlenül a tárhelyeden.
Ha szeretnél még többet megtudni, akkor becsatolom ide a hivatalos blog cikket.
Én biztosan tesztelek vele a következő AI-projektem során. Ha te is érdeklődsz a hasonló technológiák iránt, most érdemes elkezdeni a kísérletezést.