Aki régen dolgozik Azure-ban, mint én is, rendszeresen kap értesítő e-maileket, amelyekben biztonsági okokból kérik a felhasználót az infrastruktúra módosítására. Most is jött egy ilyen, október elején: a Microsoft arra figyelmeztet, hogy az Azure Tárfiókoknál 2026. február 3. után már csak a TLS 1.2 vagy újabb verzió lesz támogatott.
Ez az értesítés elsősorban azokat érinti, akiknek a Tárfiókjai még TLS 1.0 vagy 1.1 protokollt is elfogadnak. Ezek a régebbi titkosítási eljárások ma már elavultnak számítanak, és nem támogatják a modern kriptográfiai algoritmusokat, ezért a Microsoft fokozatosan megszünteti a használatukat.
Mi az a TLS és miért fontos?
A TLS (Transport Layer Security) egy biztonsági protokoll, amely az internetes adatátvitel védelmét szolgálja. A korábbi verziók (1.0 és 1.1) több mint 20 évesek, és ma már nem felelnek meg a biztonsági követelményeknek. A TLS 1.2 gyorsabb és biztonságosabb kommunikációt biztosít, amely jobban védi az adatokat a lehallgatás és a manipuláció ellen.
Mi a teendő?
Ha az Azure Tárfiókod TLS 1.0 vagy 1.1 protokollt is enged, akkor 2026. február 3-ig frissítened kell a beállításokat, különben az alkalmazásaid nem fognak tudni biztonságosan csatlakozni a szolgáltatáshoz.
A Microsoft ajánlása egyértelmű:
Állítsd be a Minimális TLS-verziót 1.2-re (vagy újabbra).
Ellenőrizd, hogy az alkalmazásaid és SDK-jaid is támogatják a TLS 1.2-t.
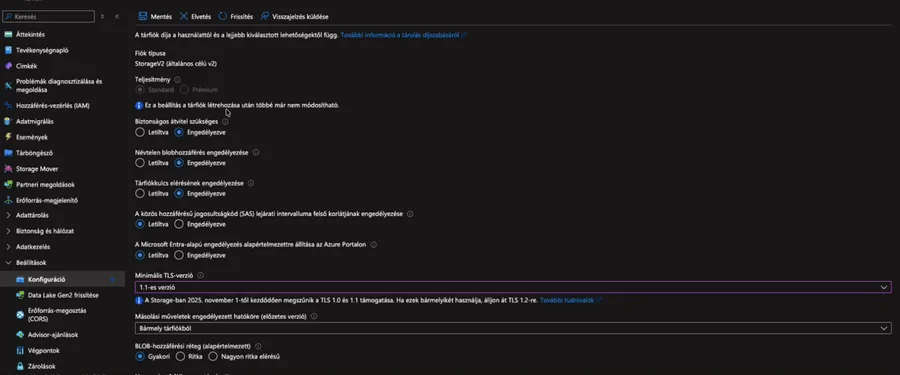
Hogyan lehet beállítani a TLS 1.2-t az Azure portálon?
A beállítás módosítása néhány kattintás az Azure portálon:
Lépj be az Azure Portalba.
Keresd meg a módosítani kívánt Tárfiókot.
A bal oldali menüben válaszd a Beállítások > Konfiguráció (Settings > Configuration) menüpontot.
A Minimális TLS-verzió (Minimum TLS version) beállításnál válaszd ki a TLS 1.2 opciót.
Mentsd el a módosítást (Mentés / Save).
Ha több Tárfiókod van, érdemes Azure Policy-t is használni, hogy központilag kikényszerítsd a TLS 1.2 beállítást minden fiókra.
Meddig van időm ezt elvégezni?
A határidő 2026. február 3., eddig kell minden Tárfiókon elvégezni a frissítést. Ezt követően a TLS 1.0 és 1.1 kapcsolatokat az Azure Tárfiók már nem fogadja el.
Aki addig nem módosítja a beállításokat, annak az alkalmazásai hibát fognak adni, amikor megpróbálnak kapcsolódni a Tárfiókhoz.
Összefoglalás
A változás célja, hogy az Azure-felhasználók biztonságosabb és korszerűbb titkosítási eljárásokat használjanak. A frissítés mindössze néhány percet vesz igénybe, de elengedhetetlen a jövőbeni hibamentes működéshez.
Amikor az OpenAI bejelentette a ChatGPT Atlas-t, azonnal letöltöttem és feltelepítettem a gépemre, hogy kipróbáljam. Első gondolatom az volt, hogy a ChatGPT vastagkliensét használom. Majd ahogy elmélyedtem benne, rájöttem, hogy ez egy teljesen más megközelítése az internetezésnek.
Az AI alapvetően a kérdéseinkre válaszol és az utasításainkat követi, de közben teljesen kihasználja azt, hogy ez egy böngésző. Amikor egy linkre kattintok a megszokott kinézetű chat-ablakban, osztott képernyőn megnyílik a weboldal. Itt lehetőségem van arra, hogy a megnyitott weboldal tartalmaival kiegészítve beszélgessek tovább az AI-val. Ez olyan érzés, mintha a GitHub CoPilot-ot használnám a Visual Studio Code-ban – csak éppen a teljes interneten.
Szerintem ez mindenképpen egy új dimenzióba helyezi az online böngészést. Talán ahhoz tudnám hasonlítani, amikor Elon Musk előrukkolt a Tesla-val, vagy Steve Jobs bemutatta az első iPhone-t. És ezen hasonlatokban nem arra gondolok, hogy valami forradalmian újat mutattak be, hanem arra, hogy újragondolták azt, amit addig ismertünk. A ChatGPT Atlas is ilyen – az internetes élményt formálja újra, alapjaiban.
Amit viszont nem értek: miért nem a Google-nak jutott ez eszébe? Megöregedtek? Elfáradtak? A Google mesterséges intelligencia-kiegészítése a keresőben amúgy is inkább vicces, mint hasznos. Nem ezt vártam. Bár tudom, ha a keresőóriás meglépte volna azt, amit most az OpenAI az Atlas-szal, akkor elesett volna sok milliárdnyi reklámbevételtől.
Nem véletlen, hogy az elmúlt egy évben már nem használom a Google keresőjét – egyszerűen elavult és szinte használhatatlan. A ChatGPT Atlas viszont megmutatta, hogyan nézhet ki a böngészés a jövőben, ha a mesterséges intelligencia nem csak válaszol, hanem valóban együtt gondolkodik velem.
Amikor a böngésző és az AI összeér, megszűnik a határ az információ és a megértés között. Nem kell külön keresnem, olvasnom, értelmeznem, majd kérdeznem – a rendszer ezt mind egyben teszi. Az Atlas nem egyszerűen egy böngésző: ez az első olyan felület, ahol az internet és az AI világa egyesül. És ahogy most látom, ez csak a kezdet.
Mitől különleges ez a böngésző?
A ChatGPT Atlas nem egyszerűen egy új termék, hanem az internethasználat újragondolása. Az OpenAI szerint ez a böngésző „a ChatGPT-vel a középpontban” készült, és célja, hogy a felhasználó munkáját, kontextusát és eszközeit egyetlen, intelligens felületen egyesítse.
A tavalyi évben a ChatGPT-ben megjelent a keresés funkció, amely azonnal az egyik legnépszerűbbé vált. Most azonban az OpenAI ezt a funkcionalitást egy teljes böngészőbe emelte át. Az Atlas lehetővé teszi, hogy a ChatGPT mindenhol ott legyen – megértse, mit csinálok, és segítsen anélkül, hogy másik oldalt vagy alkalmazást kellene megnyitnom.
A böngésző emlékezete („Browser memories”) teljesen opcionális, és a felhasználó kezében marad az irányítás – az adatok bármikor törölhetők, archiválhatók, vagy kikapcsolható a funkció.
Agent mód: Ez az egyik legizgalmasabb rész – bizonyos előfizetési szinteken (Plus, Pro, Business) elérhető. Az Agent (ügynők) mód segítségével az AI nem csak beszélget, hanem „kattint, navigál, feladatokat végez” a böngészőn belül. Például: „Keresd meg ezt az éttermet, rendeld meg az alapanyagokat”, „Készíts piackutatást a versenytársakról, majd írj belőle összefoglalót” – mindez anélkül, hogy külön programban kellene dolgoznom.
Az OpenAI hangsúlyozza, hogy a biztonság és adatvédelem kiemelt: az AI nem fér hozzá automatikusan a fájlrendszerhez, nem futtat kódot, és minden érzékeny műveletnél megerősítést kér a felhasználótól. Az Atlas jelenleg macOS-re áll rendelkezésre, más platformokra (Windows, iOS, Android) hamarosan érkezik.
Hol tart most és mit érdemes tudni?
Az Atlas most indul – egy ígéretes, de még fejlődő termék. A korai felhasználói élmények szerint bár az integráció izgalmas, néhány funkció még finomításra szorul. Például a keresési eredmények listája korlátozott, és a folyamatok még nem mindig zökkenőmentesek. Biztonsági szakértők figyelmeztettek, hogy az AI-alapú böngészők érzékenyek lehetnek a „prompt-injection” típusú támadásokra – vagyis olyan webes instrukciókra, amelyek képesek befolyásolni az AI viselkedését. Az OpenAI szerint dolgoznak a védelem erősítésén.
Miért érdekes ez nekünk?
Ha kezdő vagy az AI és az internetes böngészés ilyen modern formái felé, akkor az Atlas számunkra több okból is izgalmas:
Egyszerűbbé tesszük az internetezést: nem kell külön alkalmazást megnyitni, nem kell másolgatni-beilleszteni a tartalmakat a ChatGPT-be – mindent egy helyen tehetek.
Azonnali segítséget kapok: ha találok egy weboldalt, és nem vagyok biztos a tartalmában, az AI-val azonnal beszélhetek róla: „Mi a lényege?”, „Mi az, amit kiemelnél?”, „Hol van erre alternatív forrás?” – így nem csak passzívan olvasok, hanem aktívan gondolkodom.
Több időm marad a tényleges feladatra: mivel az AI képes részmunkákat átvenni (pl. Agent mód), nekem nem kell annyit kattintgatnom – az értelmezésre, döntéshozatalra koncentrálhatok.
Ha vállalati környezetben dolgozom, akkor ez komoly lehetőség: gyorsabban készíthetek elemzést, összegzést, mert a böngészőm és az AI egyben van.
Összegzés
Én úgy látom, hogy a ChatGPT Atlas nem csupán egy új böngésző. Ez egy lépés afelé, hogy a webes szokásunk egyre inkább „agentikus” legyen – vagyis a rutinmunkákat átruházhassuk egy intelligens asszisztensre, miközben mi a lényegre koncentrálhatunk.
Ez egy hatalmas erejű eszköz, amelytől nem magát az AI-tól kell tartanunk, hanem attól, hogy mi emberek talán még nem nőttünk fel a felelősségteljes használatához.
Azért, mint minden AI alapú megoldást, ezt is kezeljük a helyén. Ne hagyatkozzunk rá mindig!
A felhőben a rendelkezésre állás és a hibatűrés kulcsfontosságú, hiszen a legtöbb vállalat napi működése az ilyen szolgáltatásokra épül. Az Amazon Web Services (AWS) például 99,99%-os SLA-t (Service Level Agreement) vállal a legtöbb szolgáltatására, ami éves szinten mindössze egy órányi megengedett leállást jelent. Ennek ellenére időnként előfordulhatnak átmeneti fennakadások – ilyen volt a 2025. október 20-i esemény is, amely jól demonstrálta, mennyire gyorsan képes reagálni az AWS egy globális szintű problémára.
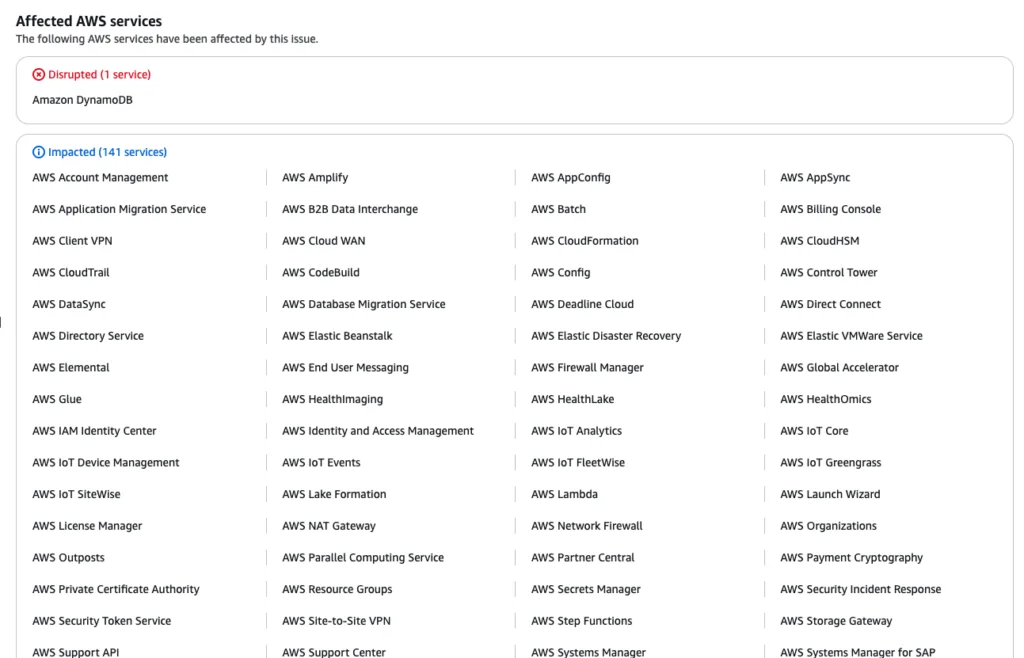
A hiba gyökere az US-East-1 (Észak-Virginia) régióban jelentkezett, és több mint 140 AWS-szolgáltatás működésére is kihatott – különösen azokra, amelyek DNS-feloldásra vagy központi vezérlősíkra (control plane) támaszkodnak.
Bár az európai (Frankfurt, EU-Central-1) régió nem volt közvetlenül az esemény központja, számos szolgáltatás itt is tapasztalt átmeneti hibákat. Ennek oka, hogy több globális AWS-komponens – például az IAM/SAML bejelentkezés, az ECR image-tárolás vagy a globális API-végpontok – részben az US-East-1-hez kapcsolódik.
Hivatalos idővonal (CEST)
09:11 – AWS vizsgálja a megnövekedett hibaarányokat és késéseket több szolgáltatásban (US-EAST-1).
09:51 – A hibák megerősítést nyernek, az AWS Support API és konzol is érintett.
10:26 – A DynamoDB végpontoknál jelentős hibák lépnek fel, további szolgáltatások is érintettek.
11:01 – Az AWS azonosítja a probléma lehetséges okát: DNS-feloldási hiba a DynamoDB végpontnál.
11:22 – Kezdeti helyreállítási jelek tapasztalhatók néhány szolgáltatásnál.
11:27 – Jelentős javulás, a legtöbb kérés már sikeresen teljesül.
12:03 – A globális szolgáltatások (IAM, DynamoDB Global Tables) is helyreállnak.
12:35 – A DNS-hiba teljesen elhárítva, a legtöbb művelet ismét normálisan működik.
13:08 – 14:10 – Az EC2 indítási hibák és a Lambda polling-késések fokozatosan javulnak.
14:48 – 15:48 – Az EC2 indítási korlátozások enyhülnek, a legtöbb Availability Zone újra működik.
16:42 – 18:43 – A hálózati terheléselosztó (Network Load Balancer) egészség-ellenőrző alrendszer hibát okoz több szolgáltatásban (Lambda, CloudWatch, DynamoDB).
18:43 – 20:13 – További mitigációk, a hálózati problémák fokozatosan megszűnnek.
20:22 – 21:15 – Szinte minden AWS szolgáltatás helyreállt, csak néhány EC2-indítás és Lambda maradt részben érintett.
22:03 – 23:52 – Teljes szolgáltatás-visszaállás az US-EAST-1 régióban.
00:01 (október 21.) – Az AWS hivatalosan is normál működést jelent.
Hatások és tapasztalatok
A kiesés során világszerte számos ismert platform – többek között a Snapchat, a Fortnite, a Reddit és a Venmo – részleges vagy teljes leállást tapasztalt. A felhőszolgáltatások közötti erős függőségek miatt a hiba nem csupán az AWS-t érintette, hanem több külső rendszer és alkalmazás működésében is zavart okozott.
A vizsgálat szerint a probléma nem biztonsági incidens vagy kibertámadás következménye volt, hanem egy belső DNS-feloldási hiba, amely a DynamoDB szolgáltatás elérhetetlenségéhez vezetett, majd tovagyűrűzött az azt használó szolgáltatásokon keresztül.
Tanulságok
Az AWS kiesése emlékeztetett arra, hogy még a legnagyobb globális felhőszolgáltatók esetében is előfordulhatnak ritka, rövid ideig tartó fennakadások. Fontos azonban kiemelni, hogy az ilyen események rendkívül ritkák, és az AWS gyors helyreállítási folyamatai miatt a szolgáltatások általában néhány órán belül normalizálódnak.
Ez az eset is jól mutatta az AWS infrastruktúra érettségét és reakcióképességét – a hibát hamar azonosították, a helyreállítás fokozatosan zajlott, és az ügyfelek többsége számára a szolgáltatások néhány órán belül elérhetővé vált. Az esemény így inkább megerősítette, mintsem gyengítette a felhőszolgáltatásokba vetett bizalmat: az AWS ökoszisztéma bizonyította, hogy képes gyorsan és hatékonyan kezelni váratlan globális problémákat.
Amikor fejlesztőként program csomagokat publikálunk vagy automatizálunk, a biztonság mindig kulcskérdés. A szoftverellátási lánc támadásai egyre gyakoribbak, ezért a GitHub most javította a hitelesítést és a token-kezelést. Az egész folyamat középpontjában a Personal Access Token (PAT) áll — ez az a digitális kulcs, ami a fejlesztők mindennapjait biztonságosabbá és szabályozottabbá teszi.
Mi az a PAT, és miért fontos?
A Personal Access Token (PAT) egy digitális azonosító, amellyel hitelesítem magam a GitHub-on vagy az npm-en anélkül, hogy jelszót kellene megadnom. Olyan, mint egy személyre szabott kulcs, amivel belépek egy zárt rendszerbe – de csak azokhoz az ajtókhoz, amelyekhez ténylegesen van jogosultságom.
A PAT azért fontos, mert:
Biztonságosabb, mint a jelszó, nem kerül közvetlenül a kódba vagy pipeline-ba.
Automatizált folyamatokhoz (CI/CD, build, deploy) elengedhetetlen, mivel emberi beavatkozás nélkül hitelesít.
Korlátozható és forgatható, így ha kiszivárog, a kár minimalizálható.
Más szóval: minden, amit a fejlesztői rendszerekben „tokenk-ént” használunk — legyen az npm, GitHub vagy API — valójában egy Personal Access Token, csak más néven vagy kontextusban jelenik meg.
A token típusok közötti különbségek
A GitHub háromféle token-mechanizmust használ — ezek közül az első volt a klasszikus PAT, a második a továbbfejlesztett granularis verzió, a harmadik pedig már a PAT nélküli jövő.
1. Klasszikus PAT (Classic Token) – a régi hozzáférés
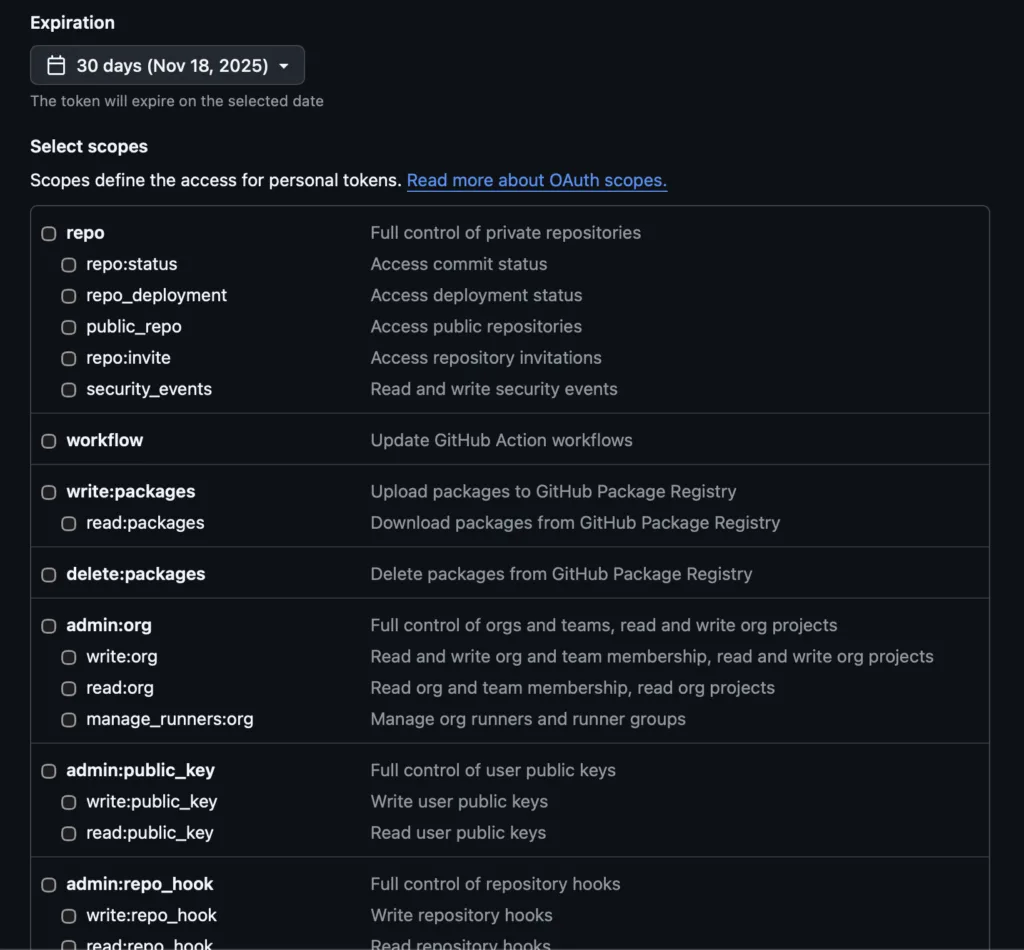
A klasszikus PAT hatókörös, tehát megadható, milyen tág jogosultságokkal rendelkezik (pl. repo). Ugyanakkor a hatóköre nem elég finom (jellemzően minden repo, amihez a felhasználónak hozzáférése van), és a lejárat nem volt kötelező – emiatt nagyobb a kockázat, ha kiszivárog.
2. Granularis PAT (Fine-grained Access Token) – a finomítás
A granularis PAT bevezetésével a GitHub sokkal precízebb jogosultságkezelést adott a kezünkbe. Beállíthatom, hogy:
pontosan mely repository-hoz fér hozzá,
milyen műveletekre jogosít (pl. olvasás, írás, admin),
és meddig érvényes legyen (alapértelmezés szerint 7 nap, maximum 90).
Ez csökkenti a támadási felületet, és jobban illeszkedik a vállalati biztonsági irányelvekhez is.
A Trusted Publishing nem azt jelenti, hogy megszűnnek a Personal Access Token-ek (PAT) – sok esetben továbbra is szükség van rájuk – hanem azt, hogy egy biztonságosabb alternatívát kínál az automatizált csomag-kezeléshez. Ebben a megközelítésben a CI/CD rendszer (például GitHub Actions vagy GitLab CI/CD) az OpenID Connect (OIDC) protokollt használja, és rövid életű hitelesítést kap az adott csomag-registry (pl. npm) felé. Így a folyamat során nem kell előre létrehozott vagy tárolt PAT-et használnom, mert a futás idejére automatikusan generálódik a jogosultság.
Ez a megközelítés jelentősen csökkenti a token-kezelés kockázatát – nincs olyan hosszú életű kulcs, amit elfelejtek forgatni vagy ami kiszivároghat –, de nem helyettesíti a PAT-eket más típusú műveletekhez vagy API-hívásokhoz. A Trusted Publishing jelenleg támogatott a GitHub Actions és GitLab CI/CD környezetben, és egyre több CI-platform fogja követni ezt az irányt.
Mi változik most konkrétan?
A GitHub az npm ökoszisztémán keresztül vezeti be a PAT-kezelés első nagy változását. A mostani frissítés három fő területet érint, és minden esetben jól látszik, hogyan változik a korábbi működés.
Terület
Korábbi állapot
Új szabály
PAT élettartam
A tokenek alapértelmezett lejárata 30 nap volt, a klasszikus PAT akár korlátlanul is élt.
Az új granularis PAT alapértelmezett lejárata 7 nap, maximum 90 nap.
Klasszikus PAT-ek
Továbbra is használhatók voltak, teljes hozzáféréssel.
Teljes kivezetés: 2025 november közepétől minden klasszikus PAT érvénytelen lesz.
WebAuthn/passkey alapú 2FA váltja, ami ellenáll a phishing-támadásoknak.
Ezek a változások október közepétől indulnak, és november közepéig minden klasszikus token megszűnik.
Példák, ahol PAT-et használunk
CI/CD pipeline-ban: amikor a GitHub Actions új verziót publikál npm-re, PAT segítségével hitelesít.
Helyi fejlesztéskor: a git push vagy npm publish művelet PAT alapján engedélyezett.
Integrációs eszközöknél: például a Dependabot vagy a Renovate PAT-tel fér hozzá a repo-hoz, hogy automatikus frissítéseket küldjön.
Hogyan készülj fel?
Új granularis PAT-eket hozol létre, és minden pipeline-ban lecseréled a régieket.
Áttérsz az OIDC-alapú Trusted Publishing használatára, ahol lehetséges.
Rendszeresen rotálod a még meglévő PAT-eket.
Bevezeted a WebAuthn alapú 2FA-t, hogy megerősítsed a fiókom védelmét.
Összegzés
A Personal Access Token-ek (PAT) a modern fejlesztői hitelesítés alapját jelentik.
Különösen fontos felhő megoldásokkal való integrálásnál (pl. Azure DevOps Pipelines vagy AWS CodePipeline), mert így biztosíthatjuk, hogy csak a szükséges műveletekhez kapunk hozzáférést, és a felhőerőforrásokat is biztonságosan kezelhetjük.
A GitHub most azért változtat, hogy ezek a tokenek rövidebb életűek, korlátozottabb hatókörűek és biztonságosabbak legyenek. Ez az átmenet az automatizált, tokenmentes jövő felé vezet — ahol az azonosítás már teljesen automatizált és emberi beavatkozás nélküli.
Én személy szerint támogatom ezt az irányt. Ez a változás nemcsak engem véd, hanem mindenkit, aki a GitHub-ra és az npm-re épít.
A felhőalapú technológiák rohamos terjedésével egyre nagyobb hangsúlyt kap az erőforrásokhoz való hozzáférés kezelése. Az elmúlt hónapokban már több cikkben is körbejártuk, hogyan épülnek fel a modern felhőarchitektúrák, és milyen eszközökkel tarthatók átláthatóan karban. Most azonban elérkeztünk egy olyan témához, ami nélkül minden korábbi tudás bizonytalan lábakon állna: a hozzáférés-kezeléshez. Ennek egyik legfontosabb pillére az RBAC, vagyis a Role-Based Access Control – magyarul szerepkör-alapú hozzáférés-vezérlés.
Képzeljünk el egy nagyvállalatot, ahol több száz vagy több ezer ember dolgozik különböző projekteken. Nem mindenki férhet hozzá mindenhez – a fejlesztők nem módosíthatják a pénzügyi adatokat, az adminisztrátor viszont nem feltétlenül lát bele az alkalmazás kódjába. Az RBAC éppen ezt a problémát oldja meg: egyértelműen meghatározza, ki mit tehet és mit nem.
Mi az RBAC lényege?
Az RBAC alapelve, hogy a hozzáférési jogokat nem közvetlenül a felhasználókhoz, hanem szerepkörökhöz rendeljük. Ezek a szerepkörök előre definiált engedélyeket tartalmaznak, amelyek meghatározzák, milyen műveletek hajthatók végre adott erőforrásokon. A felhasználók ezután egy vagy több szerepkört kaphatnak – így az engedélyezés egyszerre lesz átlátható, rugalmas és könnyen kezelhető.
A koncepció három alapeleme:
Felhasználók (Users) – azok a személyek vagy szolgáltatások, akik hozzáférnek az erőforrásokhoz.
Szerepkörök (Roles) – engedélyek gyűjteménye, például „Reader”, „Contributor” vagy „Owner”.
Hozzárendelések (Role Assignments) – ezek kapcsolják össze a felhasználót, a szerepkört és az adott erőforrást.
Hogyan működik az RBAC az Azure-ban?
Az Azure RBAC az Azure Resource Manager (ARM) modellre épül, és segítségével szabályozható, hogy ki milyen műveleteket végezhet el Azure-erőforrásokon – például virtuális gépeken, tárfiókokon, adatbázisokon vagy hálózati elemekben.
Az Azure-ban minden erőforrás hierarchikus struktúrában helyezkedik el:
Management Group (Felügyeleti csoport) – a legfelső szint, amely több előfizetést is összefoghat.
Subscription (Előfizetés) – az erőforrások logikai egysége, ahol a számlázás és az erőforrás-kvóták kezelése történik.
Resource Group (Erőforráscsoport) – az erőforrások rendezésére szolgáló konténer, például egy adott projekt vagy alkalmazás elemei számára.
Resource (Erőforrás) – az egyes Azure-szolgáltatások, például virtuális gépek, tárfiókok, adatbázisok vagy hálózati elemek.
Egy szerepkör-hozzárendelés bármelyik szinten megadható, és öröklődik a hierarchia alatti szintekre. Ha például valaki Reader jogot kap egy teljes előfizetés szinten, akkor automatikusan olvashatja az összes erőforráscsoport és erőforrás tartalmát abban az előfizetésben.
RBAC a gyakorlatban (példa)
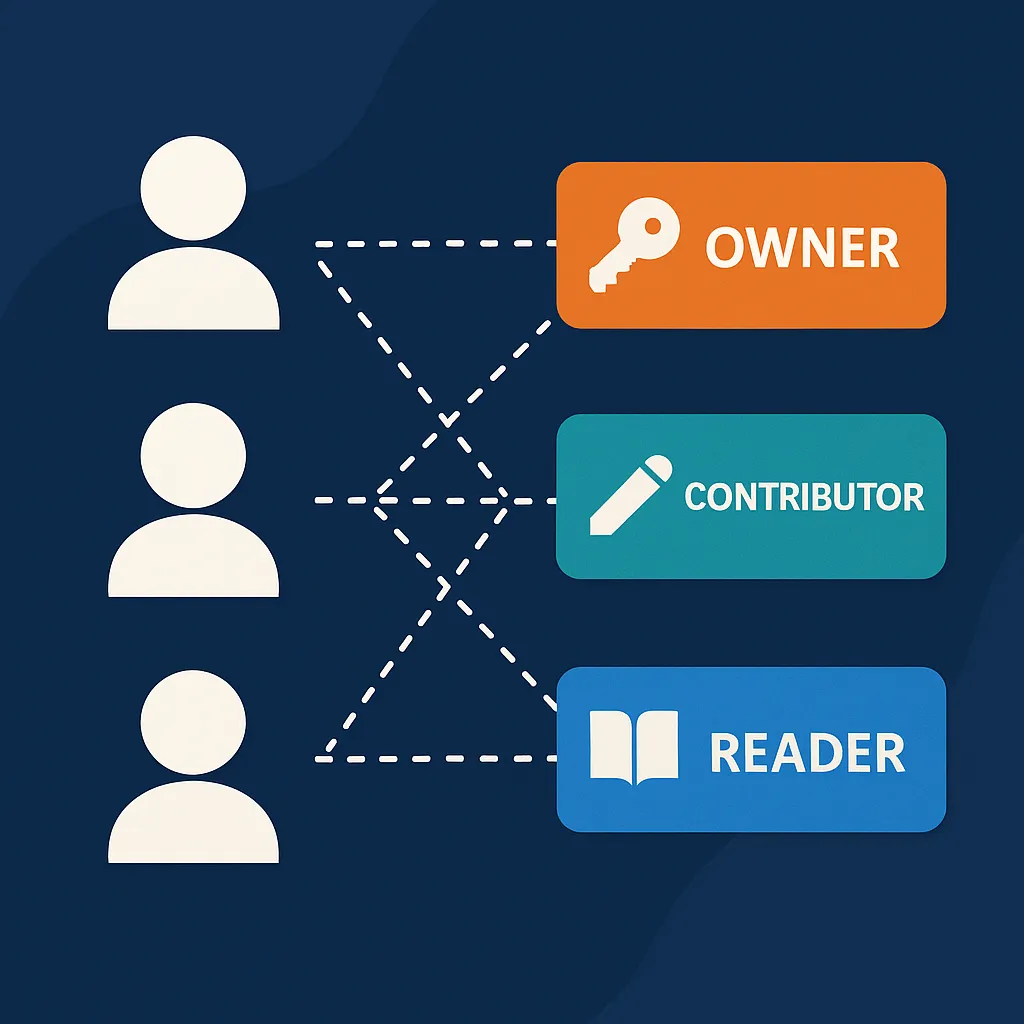
Képzeljük el, hogy egy fejlesztőcsapat három szereplőből áll:
Attila, a vezető fejlesztő
Péter, az infrastruktúra adminisztrátor
Zoli, a tesztelő
Az IT biztonsági elv szerint mindenkinek csak a munkájához szükséges jogokat adjuk meg.
Attila (Contributor) – létrehozhat, módosíthat és törölhet erőforrásokat a fejlesztői Resource Group-ban, de nem kezelheti a hozzáféréseket.
Péter (Owner) – teljes körű hozzáféréssel rendelkezik, így módosíthatja a szerepköröket és erőforrásokat is.
Zoli (Reader) – csak megtekintheti a fejlesztési környezetben található erőforrásokat, de nem módosíthat semmit.
Ez a megközelítés egyszerre biztonságos és hatékony, hiszen mindenki csak azt látja és azt kezeli, ami a feladata ellátásához szükséges.
RBAC szerepkörök az Azure-ban
Az Azure több mint 120 beépített szerepkört kínál, de a leggyakoribbak közé tartozik:
Owner – teljes hozzáférés mindenhez, beleértve a hozzáférés-kezelést is.
Contributor – minden erőforrást módosíthat, de nem kezelheti a jogosultságokat.
Reader – csak olvasási hozzáféréssel rendelkezik.
User Access Administrator – mások jogosultságait kezelheti, de magukat az erőforrásokat nem módosíthatja.
Ezen felül lehetőség van egyedi szerepkörök létrehozására is, ha a beépített szerepkörök nem fedik le pontosan a szervezet igényeit. Egyedi szerepkörök JSON formátumban definiálhatók, és pontosan meghatározható bennük, milyen műveletek engedélyezettek vagy tiltottak.
Az RBAC előnyei
Biztonság – Csökkenti a túlzott jogosultságok kockázatát, így kevesebb az emberi hiba vagy jogosulatlan hozzáférés.
Átláthatóság – Könnyen ellenőrizhető, ki milyen jogokkal rendelkezik.
Skálázhatóság – Nagyvállalati környezetben is egyszerűen kezelhető a jogosultságok bővülése.
Automatizálhatóság – A szerepkörök hozzárendelhetők automatizált szkriptekkel vagy Terraform kódokkal is.
Az RBAC korlátai
Bár az RBAC rendkívül hasznos, nem minden esetben elégséges.
Nem tudja kezelni az adatszintű hozzáféréseket (például egy SQL tábla soraira vonatkozó jogosultságokat).
A komplex szervezeti hierarchiákban a szerepkörök öröklődése nehezen átláthatóvá válhat.
Túl sok egyedi szerepkör esetén nő az adminisztrációs teher és a hibalehetőség.
A cégek számára az RBAC legnagyobb előnye a kontroll és a biztonság egyensúlya. Ahelyett, hogy mindenki korlátlanul hozzáférne mindenhez, az RBAC lehetővé teszi, hogy a hozzáférés csak a szükséges mértékben legyen biztosítva.
A felhasználók számára ez azt jelenti, hogy egyértelműen látják, mire jogosultak, és nem kell aggódniuk a véletlen hibák miatt. Egy fejlesztő például nyugodtan dolgozhat a saját projektjén anélkül, hogy kockáztatná más rendszerek működését. A rendszergazdák pedig gyorsabban és pontosabban tudják kiosztani az engedélyeket, akár automatizált folyamatokon keresztül is.
Összegzés
A Role-Based Access Control az egyik legfontosabb biztonsági és hatékonysági alapelv a felhőben. Az Azure RBAC egy kifinomult, de logikusan felépített rendszer, amely segít abban, hogy a szervezetek biztonságosan, mégis rugalmasan kezeljék a hozzáféréseket.
Az alapelve egyszerű: mindenkinek csak annyi jogot adjunk, amennyire valóban szüksége van.
Ez a szemlélet nemcsak az Azure-ban, hanem bármely modern informatikai környezetben elengedhetetlen, ahol a bizalom és az ellenőrzés kéz a kézben jár.
Ma is egy Kubernetes témájú cikket hoztam. Legutóbb a Kubernetes belső kommunikációját írtam le. Amikor belekezdtem a Kubernetesről szóló cikksorozatba, arra vállalkoztam, hogy lépésről lépésre mutatom be, miért olyan meghatározó ez a technológia a modern felhő– és konténervilágban. A korábbi cikkekben már kitértünk arra, hogy hogyan épül fel a fürt, mi a szerepe az ütemezőnek, és miként alakul át a régi monolitikus alkalmazásmodell a mikroszolgáltatások felé.
Most eljutottunk ahhoz a ponthoz, ahol a technológia legapróbb, mégis kritikus részletei – a kapszulák közötti kommunikáció és a hálózati plugin-ek – kerülnek reflektorfénybe. Ebben a részben azt járjuk körül, hogyan jut el egy kapszula (Pod) egyik pontból a másikba – akár ugyanazon a gépen, akár másik node-on -, milyen feladatokat lát el ilyenkor a CNI (Container Network Interface), és milyen hálózati modellek, trükkök és kihívások vannak a háttérben.
1. A Kubernetes hálózati elvárások
Mielőtt belemerülnénk a technikai megvalósításba, nézzük meg, mit is ígér a Kubernetes hálózati modellje – ezeknek az elvárásoknak kell megfelelnie bármely gyakorlati rendszernek:
Minden kapszulának egyedi, fürtszintű IP-címe kell legyen. Nem privát, izolált cím, hanem olyan, amit a teljes fürtben használni tudunk.
Kapszulák között nincs NAT (Network Address Translation) — minden forgalom „mezei” IP-címekkel zajlik.
Kapszulák, akár ugyanazon a node-on vannak, akár különböző node-okon, közvetlenül elérhetik egymást.
A node-ok (gépek, amelyeken futnak a kapszulák) elérik a rajtuk lévő kapszulákat, és szükség szerint a node-ok is kommunikálnak a kapszulákkal.
A hálózati házirendek (NetworkPolicy) használata révén szabályozható, hogy melyik kapszula kit érhet el (ingress, egress) – de ez már „magasabb” réteg, amit a plugin-eknek is támogatniuk kell.
Természetesen a Kubernetes felhasználók nem akarnak mindentkézzel konfigurálni – a hálózatnak „láthatatlannak” kell lennie: működnie kell a háttérben, megbízhatóan és automatikusan.
2. Hol kapcsolódik be a CNI – és mit csinál pontosan?
A CNI (Container Network Interface) nem egy konkrét hálózati eszköz, hanem egy szabvány (interfész) és hozzá tartozó könyvtárkészlet, amely arra szolgál, hogy különféle plugin-ek révén a Kubernetes node-ok (és rajtuk futó konténer-rendszerek) dinamikusan konfigurálhassák a hálózati környezetet.
A Kubernetes komponensei – elsősorban a kubelet, a konténer runtime (például containerd vagy CRI-O) és maga a CNI plugin-ek kódja -együtt dolgoznak, hogy amikor egy Pod-ot elindítanak vagy leállítanak, a hálózati környezet is ennek megfelelően jöjjön létre, módosuljon, vagy takarításra kerüljön.
A tipikus folyamat (ADD / DEL / CHECK műveletek) így néz ki:
A kubelet jelzi a konténer runtime-nak, hogy el szeretne indítani egy Pod-ot.
A runtime elindítja a konténereket a Pod alá.
Amikor a futtató környezet képes hálózati feladatokra, a kubelet meghívja a CNI plugint ADD parancssal.
A CNI plugin-ek végrehajtják a hálózati konfigurációt: létrehozzák a hálózati névteret (network namespace), hozzáadják a hálózati interfészt (pl. veth párok), beállítják az IP-címet (IPAM segítségével), útvonalakat, DNS-t/stb.
Ha később a Pod megszűnik, a CNI DEL parancssal takarítja ki az eszközöket (interfészek, címek)
Fontos, hogy a CNI plugin-ek láncolhatók is – azaz lehet egy fő plugin (pl. Calico, Cilium) mellett kiegészítő plugin-ek is, mint bandwidth, portmap, stb.
Például, ha szeretnénk szabályozni, hogy egy Pod mennyi sávszélességet kapjon be- vagy kimenő forgalomra, hozzá lehet adni a bandwidth plugint a CNI konfigurációhoz.
3. A gyakori hálózati modellek és plugin-ek
Az interfész-réteg (CNI) mögött olyan plugin-ek állnak, amelyek különféle hálózati megközelítéseket valósítanak meg. Íme néhány általános modell és példa kiemelt plugin-ekre:
3.1 Bridge / VETH alapú modell (klasszikus „local” modell)
Ez a legegyszerűbb forma: a node-on belül egy „bridge” jön létre, és a Pod interfészei (veth pár) rá vannak kötve erre a hídra. Így az adott node-on belül a kapszulák kommunikálhatnak. IP-címeket pl. host-local IPAM plugin biztosít. Előnye, hogy egyszerű és jól átlátható; hátránya, hogy ha több node van, szükség van valamilyen router-re vagy overlay technikára, hogy a forgalom átjusson node és node között. (Ez a „bridge + route” vagy „bridge + overlay” modell)
3.2 Overlay hálózat (VXLAN, IP-in-IP, GRE stb.)
Amikor két node közötti forgalomnak „alagutaznia” kell, gyakran használják az overlay technológiákat. Ilyenkor a Pod-ok IP-címe egy virtuális hálózaton belül van (a „virtuális kontinens”), és a fizikai hálózaton csomagokat kapszulázzák (encapsulate), hogy átjussanak node-ról node-ra. A népszerű overlay technikák között van VXLAN, IP-in-IP, GRE. Például a Flannel alapértelmezett módban VXLAN-t használ.
3.3 Native routing / BGP alapú modell
Egy másik megközelítés az, hogy a pod IP-ket közvetlenül routoljuk a node-ok között, mint ha egy valódi IP-hálózat lenne, és nem használnánk kapszulázást. Ebben a modellben gyakran alkalmaznak BGP-t (Border Gateway Protocol) a route-propagációhoz. A Calico például képes arra, hogy “unencapsulated” (vagy opcionálisan encapsulated) módon működjön BGP-vel — így a hálózat egyszerűbbé válhat, ha a fizikai hálózat is támogatja.
3.4 eBPF alapú megoldások
Az egyik legfrissebb trend, amelyet a Cilium képvisel, hogy a kernel mélyebb rétegeit használja (eBPF, XDP), és nagy sebességű, alacsony késleltetésű adatforgalmat tud nyújtani, miközben támogatja a hálózati szabályokat, L7-szűrést, szolgáltatásszintű policyket stb. Érdekesség: Cilium képes akár helyettesíteni kube-proxy funkciókat is, hiszen a belső forgalom kezelését, load balancinget eBPF hash táblákkal végezheti.
3.5 Több CNI plugin együtt – Multus
Van helyzet, amikor egy kapszulának több hálózatra is szüksége van (például egy belső adatforgalmi háló és egy másik dedikált háló). Ezt teszi lehetővé a Multus, amellyel egy pod több hálózati interfésszel is rendelkezhet, és párhuzamos CNI plugin-eket lehet használni.
4. Gyakorlati példák és konfigurációk
Az előző cikkekhez mellékelt CNI konfigurációs fájl (bridge típusú) már bemutatott egy alapvető konfigurációt. Nézzünk most pár gyakorlati példát és jellemző paramétert:
isGateway: true → a híd viselkedhet úgy, hogy gateway funkciói is vannak (pl. forgalom továbbítása)
ipMasq: true → IP-maszkálás engedélyezése
Az ipam alatt a host-local plugin kiosztja a címet a megadott tartományból, és beállítja az útvonalakat.
Ha például szeretnénk porttérképezést (hostPort) – azaz, hogy a pod portjait a node portjaira visszük —, akkor a CNI konfigurációnak tartalmaznia kell egy portmap plugint és be kell állítani a capabilities: {"portMappings": true} mezőt.
Ugyanígy, a traffic shaping (sávszélesség-korlátozás) támogatásához hozzáadható a bandwidth plugin. Ezzel annotation-ökkel meg lehet mondani, hogy egy Pod mennyi be- és kimeneti sávszélességet használhat.
5. Kihívások és finomhangolási lehetőségek
Akár egy otthoni fejlesztői klasztert építesz, akár nagy méretű produkciós fürtöt, a hálózati reszletek sokféle kihívást hoznak:
Teljesítmény és overhead: Overlay technikák (kapszulázás) CPU- és hálózati overhead-et hoznak magukkal. Érdemes mérni, tesztelni, hogy az adott CNI plugin és beállítás hogyan viselkedik a tényleges terhelés alatt. (Egy friss tanulmány például különböző CNI-k teljesítményét vizsgálta edge környezetekben.)
Skálázhatóság és routing: Nagy fürtökben a route-ok kezelése, a BGP vagy más dinamikus routing megoldások kezelése kritikus.
Biztonság és izoláció: A hálózati policiák (NetworkPolicy) biztosítják, hogy ne minden Pod hozzáférhető mindenhonnan. Ehhez a CNI pluginnak támogatnia kell a policiarendszert.
Plugin kompatibilitás és frissítések: Ha több plugin (pl. bandwidth, portmap) van láncban, gondoskodni kell arról, hogy verziók kompatibilisek legyenek, ne legyenek függőségi konfliktusok.
IPv6 támogatás, dual-stack: Egyre több rendszer használ IPv6-ot, néha IPv4+IPv6 kombinációban. A CNI-nek és plugin-eknek is alkalmasnak kell lenniük erre.
Szolgáltatások (Service) és load balancing integrációja: A Pod-Pod kommunikáció önmagában csak egy része az egész képnek — a szolgáltatásoknak stabil címet kell adni, belső load balancert kell biztosítani, és a node-port / ingress forgalmat is kezelni kell.
6. Összegzés és tanulságok
A Kubernetes hálózati alapjai, különösen a Pod-Pod kommunikáció és a CNI plugin-ek működése, kulcsfontosságúak ahhoz, hogy megbízható, skálázható és biztonságos fürtöket építsünk.
A CNI adott interfészeket biztosít ahhoz, hogy a Kubernetes komponensek (kubelet, runtime) együttműködhessenek a hálózati plugin-ekkel, és dinamikusan kezelhessék a hálózati erőforrásokat.
A hálózati plugin-ek (bridge, overlay, BGP / routing, eBPF) különféle kompromisszumokat kínálnak – választásuk függ a fürt méretétől, teljesítményigénytől, topológiától és a biztonsági elvárásoktól.
Több hónapja olvashattok cikkeket a Kubernetesről, ahol megismerkedtünk a fürt felépítésével, és láttuk, hogyan működik együtt a vezérlősík és a munkavégző csomópontok. Olyan ez, mint amikor egy várost építünk: először megteremtjük az alapokat, majd egyre több részletet adunk hozzá. Most viszont elérkeztünk ahhoz a ponthoz, amikor a város lakói – a kapszulák – nemcsak magukban léteznek, hanem beszélniük is kell egymással.
A történet tehát itt válik igazán emberközelivé: hiába áll minden készen, ha nincs út, amin eljutunk a szomszédhoz, és hiába van házunk, ha nem tudjuk becsengetni a barátainkhoz. A Kubernetes világában ezeket az „utakat” és „kapukat” a hálózati beállítások és a szolgáltatások biztosítják.
A hálózat szerepe a Kubernetesben
A Kubernetes egyik legfontosabb alapelve, hogy a kapszula (pod) az alap számítási egység. Egy kapszula több konténert is tartalmazhat, és ezek mind azonos IP-címet osztanak meg. Hálózati szempontból tehát egy kapszula úgy viselkedik, mint egy önálló virtuális gép vagy fizikai szerver.
Ez azonban három kihívást hoz magával, amelyeket minden fürtnek meg kell oldania:
Konténer-konténer kommunikáció ugyanazon kapszulán belül – ezt maga a kapszulázás oldja meg.
Kapszula-kapszula kommunikáció a fürt bármely csomópontján.
Külső forrás-kapszula kommunikáció, amelyet a szolgáltatások (Services) biztosítanak.
Fontos tudni, hogy a Kubernetes önmagában nem konfigurál hálózatot. A fürt üzemeltetőinek kell olyan hálózati megoldást biztosítaniuk (például CNI pluginnal), amely lehetővé teszi a kapszulák közötti közvetlen kommunikációt.
Szolgáltatások (Services) a Kubernetesben
A szolgáltatások célja, hogy stabil hálózati elérhetőséget nyújtsanak a kapszulák számára. Mivel a kapszulák dinamikusan jönnek létre és tűnhetnek el, az IP-címük is változhat. Egy szolgáltatás viszont állandó végpontot ad, amely mögé a kapszulák rendeződnek.
A legfontosabb típusok:
ClusterIP – alapértelmezett típus, amely csak a fürtön belül érhető el. Ezzel kapszula–kapszula kommunikációt tudunk megvalósítani.
NodePort – fix portot nyit minden csomóponton, amelyen keresztül kívülről elérhető a szolgáltatás.
LoadBalancer – felhőszolgáltatóknál használatos, ahol a külső terheléselosztót integrálja.
ExternalName – DNS alapú átirányítás külső szolgáltatásra.
Ezek segítségével biztosítható, hogy az alkalmazások belső és külső kliensei mindig megtalálják a működő példányokat, függetlenül attól, hogy a kapszulák IP-címe változik.
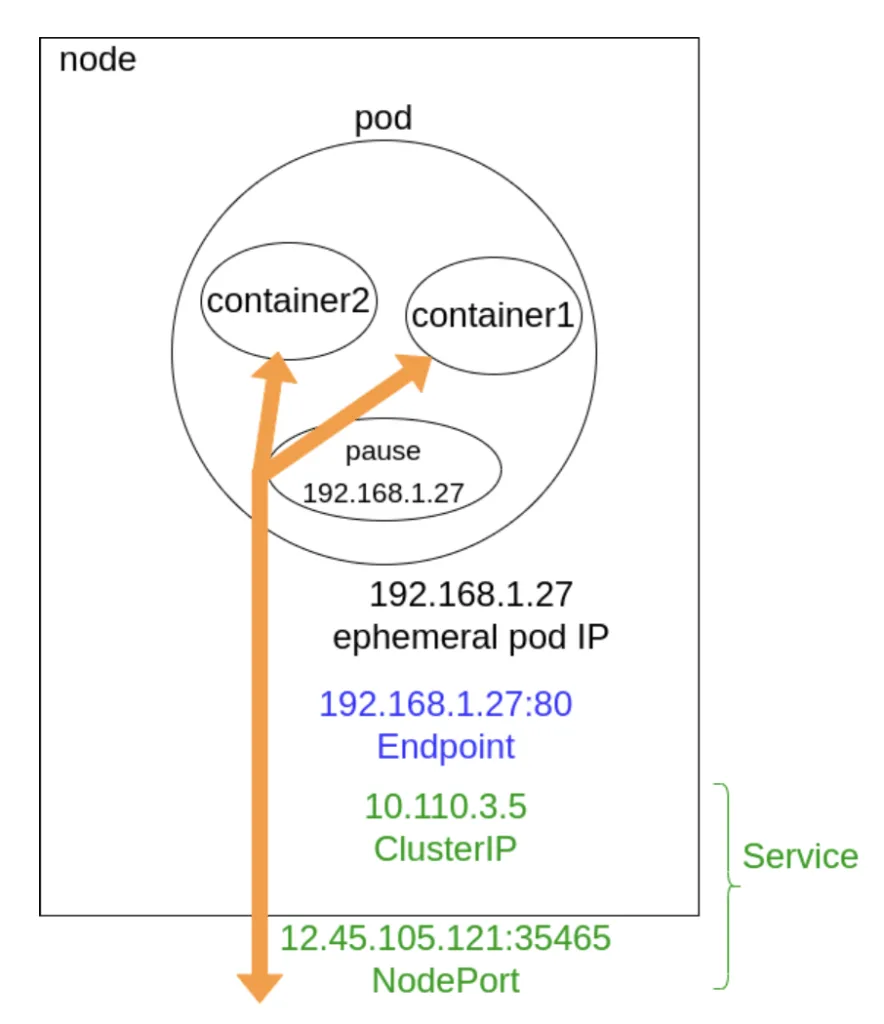
A pause container szerepe
Érdemes megemlíteni a pause konténert is, amely minden kapszulában jelen van – bár a felhasználó ezt közvetlenül nem látja. Feladata, hogy lefoglalja az IP-címet és biztosítsa a hálózati névteret, mielőtt a többi konténer elindul. Ez egy technikai részlet, de nélkülözhetetlen a kapszulák stabil működéséhez.
Kapcsolódás a külvilághoz
Amikor egy szolgáltatásnak a fürtön kívülről is elérhetőnek kell lennie, több megoldás létezik:
NodePort a legegyszerűbb, de kevésbé rugalmas megoldás.
Ingress vagy IngressController, amely HTTP(S) szintű szabályozást tesz lehetővé, és tipikusan terheléselosztással együtt használjuk.
Proxy megoldások, amelyek szintén irányíthatják a forgalmat.
Így lesz teljes a kép: a kapszulák egymással és a külvilággal is kommunikálhatnak, stabil, jól szabályozott csatornákon keresztül.
Összegzés
A Kubernetes világában a hálózat és a szolgáltatások jelentik azt az „érrendszert”, amely összeköti az életet adó szerveket. A kapszulák önmagukban csak sejtek, de a hálózat biztosítja az összhangot, a szolgáltatások pedig a megbízható híd szerepét töltik be a belső és külső világ között.
Az elmúlt időszak eseményei olyanok, mint egy mese, ami váratlanul rémálommá vált. Képzeld el, hogy van egy kis kikötő, ahol a hajók évek óta ugyanazt a megbízható szállítótól kapják az alkatrészeket, ráadásul ingyen. A kapitányok megszokták, hogy mindig időben érkezik az utánpótlás, és minden zökkenőmentesen működik. Egy nap azonban a kikötőt átveszi egy új tulajdonos, aki közli: a régi, készleten lévő alkatrészek ugyan még elérhetők, de újak már nem lesznek, legalábbis nem ingyen.
A kapitányok előtt három út marad: átállnak az új, drágább rendszerre, saját megoldást keresnek, vagy alternatív kikötőt választanak.
Technológiailag ez a helyzet tükrözi, amit néhány napja a Bitnami Docker image-k kapcsán bejelentettek. Sok fejlesztői közösség számára hirtelen egy új realitással kell szembenézni – és most megnézzük együtt, mit is jelent ez a változás, és milyen lehetőségeink vannak.
Mi az a Bitnami?
A Bitnami egy régóta ismert projekt, amely célul tűzte ki, hogy nyílt forrású szoftvereket (pl. adatbázisokat, webkiszolgálókat, cache-rendszereket) „do‐it‐yourself” egyszerűségű csomagként kínáljon: konténerképek, Helm chartok, könnyű telepíthetőség. Évtizedeken át sok Kubernetes-projekt, fejlesztő és üzemeltető használta ki előre konfigurált Bitnami image-eket és chartokat, mivel ezek stabilan, dokumentáltan és viszonylag kevés törés mellett működtek.
A Bitnami projekt most a Broadcom portfóliójába tartozik (Broadcom a VMware-t vásárolta fel), és ennek kapcsán stratégiai átalakítást hajt végre a konténerkép-disztribúciójában.
Miért fontos ez a változás?
A Bitnami eddig szerepelt sok Kubernetes infrastruktúra alapvető építőköveként: telepíthető komponensek, megbízható konténerképek, és helm chartok, amelyek akadálymentesítették az alkalmazások bevezetését. Amikor ez a támogatás visszavonul, többféle technikai és gyakorlati kockázat jelenik meg:
A docker.io/bitnami publikus regisztrációs hely (ahonnan sok image eddig szabadon letölthető volt) a változások hatására mérséklődik, és sok verziós címke eltűnik.
Az eddigi képek átkerültek egy Bitnami Legacy (bitnamilegacy) regiszterbe, ahol nem kapnak több kiadást, frissítést, biztonsági javítást.
Egy új, Bitnami Secure Images (bitnamisecure) hivatalosan nem „közösségi” szolgáltatás, hanem vállalati előfizetéshez kötött, fizetős kínálat.
A publikus Helm chartok (az OCI manifestjeik) frissítése is szünetel: a forráskód továbbra is elérhető marad GitHub-on, de az automatikus képek, verziófrissítések nem mindig jönnek majd.
A végleges “központi” publikus Bitnami regiszter törlése 2025. szeptember 29-én volt.
A Bitnami Secure Images vállalati előfizetésként érhető el, ára a források szerint több ezer dollár havonta, jellemzően 6 000 USD/hó körüli szinten indul.
Mindez azt jelenti, hogy ha nem léptünk időben, a Kubernetes klaszterekben, CI/CD folyamatokban, frissítési és automatikus skálázási műveletek során hirtelen hibaüzenetekkel (például ImagePullBackOff, ErrImagePull) találkozhatunk, amikor a rendszer nem tudja letölteni a szükséges képeket.
Mit okozhat a Kubernetes alapú rendszerekben?
Ha nem készültünk fel:
Új podok nem indulnak el – amikor a fürt új csomópontot indít vagy új replika szükséges, a rendszer letöltené a Bitnami image-t, de ha az már nem elérhető, hibát kapunk: ErrImagePull vagy ImagePullBackOff.
Frissítés vagy skálázás meghiúsul – ha egy alkalmazást új verzióra frissítenénk, de a chartban vagy a konfigurációban Bitnami image hivatkozás van, akkor az update művelet elbukhat.
Biztonsági elmaradások halmozódnak – a bitnamilegacy képek fagyottak: nem kapnak további biztonsági frissítést, így elavult, sérülékeny komponensek maradhatnak használatban.
Rejtett függőségek okozta meglepetések – nemcsak közvetlen alkalmazásaink használhatják Bitnami képeket, hanem alcsomagok, segédkonténerek, init container-ek is, amelyek rejtetten hivatkozhatnak a bitnami regiszterre.
CI/CD pipeline-ok hibái – ha build vagy teszt folyamat során Bitnami képet húzunk be (pl. adatbázis konténer, migrációs konténer), akkor az egész pipeline leállhat.
Összességében tehát egy jól működő rendszerben sok esetben „hallgatólagos” függőségek fognak megbukni, és váratlan leállások vagy hibák léphetnek fel.
Milyen lehetőségeink vannak a problémák megoldására?
Ahogy a halász a történetben új kikötőt vagy hajót választhat, nekünk is több stratégiánk van:
1. Átirányítás a Bitnami Legacy Registry (bitnamilegacy)
Ez a legegyszerűbb ideiglenes megoldás: módosítjuk a konfigurációkat (helm values, deployment spec) úgy, hogy a repository: bitnamilegacy/… formát használjuk, és tartsuk meg a jelenlegi címkéket, amíg át tudunk térni.
Előny: viszonylag kevés munkával elérhető átmeneti működés. Hátrány: ezek az image-ek nem kapnak új frissítéseket vagy biztonsági javításokat — idővel elavultak lesznek.
Ha ezt választjuk, erősen ajánlott saját privát regiszterbe tükrözni (mirror), hogy legalább ne függjünk harmadik féltől.
2. Használjuk a Bitnami Secure Images (BSI) szolgáltatást
A Bitnami bejelentette, hogy új, „secure”, hardened képek és Helm chartok szolgáltatása indul, amely verziókezelést, SBOM-ot, CVE-transzparenciát, és egyéb vállalati tulajdonságokat ad. Ez a megoldás azonban jellemzően fizetős, és inkább vállalati környezetekben lesz értelmes választás. Ha előfizetünk, akkor a képek és chartok publikusan már nem a bitnami regiszteren lesznek, hanem automatikus privát vagy dedikált OCI regisztereken. A Bitnami beígérte, hogy a Secure Images kínálat kisebb, de biztonságosabb verziókat fog tartalmazni (distroless képek, kisebb támadási felület).
3. Teljes elszakadás a Bitnami képektől – alternatívák és saját build
Ez a leginkább javasolt hosszú távon: magunknak választunk más képeket (például hivatalos Docker képeket, más közösségi projektek képeit), vagy akár a Bitnami számára elérhető open source konténerforrásokból saját képeket építünk és menedzselünk.
A Bitnami-forráskódok (Dockerfile-ok, Helm chartok) továbbra is elérhetők GitHubon Apache 2 licenccel — tehát jogilag megengedett saját építésre.
Kiválaszthatunk megbízható, aktív közösségű alternatívákat (pl. hivatalos image-ek, distro-specifikus build-ek).
Szükség lehet az értékek és beállítások átalakítására, mert nem minden image viselkedik ugyanúgy, mint a korábbi Bitnami verziók.
Célszerű bevezetni folyamatos integrációs (CI) pipeline-ban a képek tesztelését, vulnerability scan-t, hogy újabb függőségi hibák ne csússzanak be.
Lépésként részleges migráció is szóba jöhet: először a kritikus komponenseket „lecsupaszított”, alternatív képekkel cserélni, majd haladni tovább.
4. Audit és függőségek feltérképezése
Mielőtt döntenénk, célszerű átfogó auditot végezni:
Kikeresni az összes konténerkép-hivatkozást (pl. grep bitnami a manifestekben).
Megszámolni azokat a fürtön belüli podokat, amelyek Bitnami képet használnak (pl. kubectl get pods -A -o json | jq … | grep bitnami)
Felmérni, mely komponensek kritikusak, melyek kevésbé veszélyeztetettek, hogy prioritásokat állíthassunk.
Tesztelni a migrált konfigurációkat staging környezetben, hogy ne érjen minket meglepetés élesben.
5. Fokozatos átállás, párhuzamos környezetek
Nem feltétlenül kell mindent egyszerre lecserélni. Lehet fokozatosan:
Kritikus komponensek migrálása
Tesztkörnyezetek kipróbálása
Monitorozás, visszajelzések gyűjtése
Végleges átállás
Ez csökkentheti a kockázatot, és lehetőséget ad arra, hogy közbe avatkozzunk, ha valami nem működik.
Összegzés
Ez jelentős változás a konténeres és Kubernetes-alapú rendszerek világában. Ha nem készültünk fel, akkor ImagePull hibák, skálázási problémák és biztonsági elmaradások várnak ránk.
A legbiztosabb megoldás hosszú távon az, ha függetlenedünk a Bitnami-tól: alternatív képeket használunk, saját építésű konténereket alkalmazunk, és megfelelő folyamatokat építünk be (audit, tesztelés, scanning). Addig is átmeneti megoldásként a Bitnami Legacy regiszter használata segíthet.
Most képzeld el, hogy ebben a világban sétálsz egy városban, ahol minden háznak (a kapszulának) van saját, egyedi címe (IP-je). Ezzel a címmel bárki rátalálhat, és eljuthat a megfelelő ajtóhoz. Olyan mint egy házszám, vagy GPS koordináta.
Hogyan működik ez a címkiosztás, és hogyan kapcsolódnak a kapszulák a külvilághoz? Erről szeretnék neked írni néhány gondolatot.
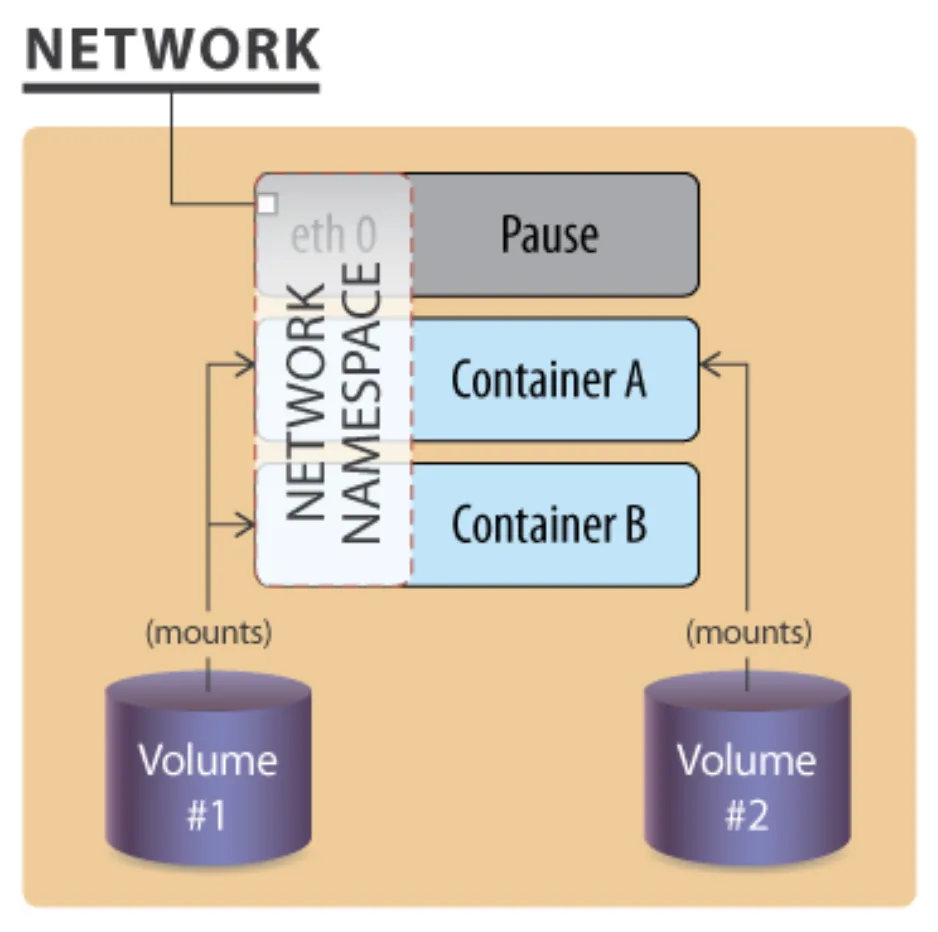
Kapszula és hálózati névtér
Egy Kubernetes kapszula (Pod) olyan, mintha több szoba lenne egy közös lakásban: minden konténer külön szobát kap, de ugyanazt a hálózati névteret (network namespace) osztják meg. Ez azt jelenti, hogy a kapszula minden konténere ugyanazzal az IP-címmel rendelkezik.
A háttérben egy különleges szereplő, a pause konténer gondoskodik arról, hogy a kapszula egy IP-címet kapjon.
A pause konténer önmagában nem futtat alkalmazást, de létrehozza a hálózati környezetet.
A kapszula többi konténere ebbe a környezetbe csatlakozik, így osztoznak az IP-címen és a hálózati interfészen.
Ez a megoldás egyszerűsíti a fejlesztők életét: nincs szükség külön IP-címek kiosztására minden konténerhez, és a belső kommunikáció is egyszerűbb.
Konténerek közti kommunikáció
Ha a kapszulán belüli konténerek egymással akarnak kommunikálni, több lehetőségük van:
vagy folyamatközi kommunikációval (IPC) üzenhetnek egymásnak.
Ez olyan, mintha egy lakásban élő családtagok néha egymáshoz szólnak, néha pedig egyszerűen cetlit hagynak a hűtőn.
A kapszulától a külvilágig: Service és NodePort
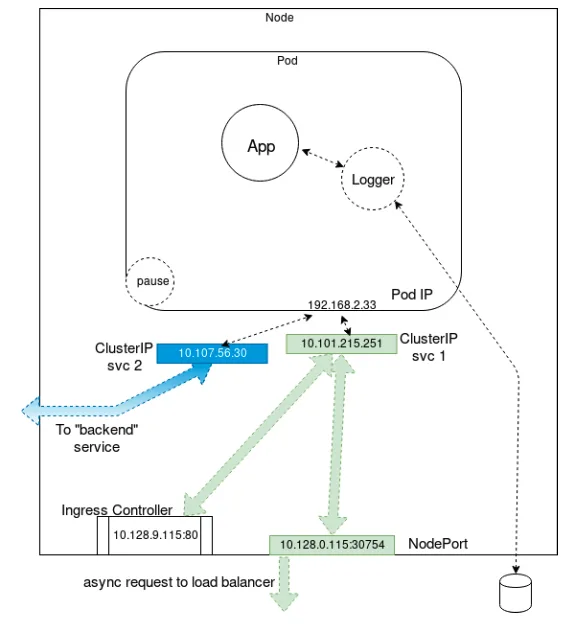
A fürtön belül minden kapszula elérhető a saját IP-címén, de a külvilág számára ez nem elegendő. Ahhoz, hogy egy külső felhasználó vagy rendszer is elérje a kapszulát, szükség van egy Service objektumra.
A legegyszerűbb típus a NodePort:
a Kubernetes egy magas sorszámú portot nyit meg a node-on (például 30000-32767 tartományban),
ezen a porton keresztül érkezik a forgalom a kapszulába,
a Service egy endpointot hoz létre, amely összeköti a kapszula IP-címét és a portját.
Ez biztosítja, hogy a hálózati csomagok a megfelelő konténerhez jussanak.
A hálózati forgalom útja
A NodePort és más szolgáltatások működésében kulcsszereplők a Kubernetes hálózati komponensei:
A kube-proxy figyeli a szolgáltatásokat, és gondoskodik arról, hogy a forgalom a megfelelő kapszulába jusson. Ehhez iptables vagy ipvs szabályokat használ.
Az iptables a Linux kernel beépített tűzfal- és forgalomirányító eszköze, amely szabályokkal határozza meg, hogyan kell kezelni a csomagokat.
Az ipvs (IP Virtual Server) modernebb, nagy teljesítményű forgalomirányítási megoldás, amely hatékonyabb load balancingot biztosít.
A kube-controller-manager pedig állandóan figyel (ún. watch loop-okkal), hogy ha változás történik – például új kapszula indul, vagy egy régi törlődik – a szolgáltatások és az endpointok mindig naprakészek legyenek.
Ez a háttérmunka szinte láthatatlan, de garantálja, hogy a felhasználó mindig eléri a szolgáltatást.
Miért fontos ez a modell?
Az „egy IP minden kapszulának” megközelítés egyszerre biztosít egyszerűséget és kiszámíthatóságot:
a fejlesztőknek nem kell bonyolult port mappingot kezelniük,
a hálózat minden kapszula esetében azonos módon viselkedik,
a skálázás, frissítés és hibaelhárítás is könnyebb.
Nem véletlen, hogy ez a modell vált iparági szabvánnyá: a Kubernetes a világ legnagyobb rendszereiben is megbízhatóan működik ezen az alapokon.
Korábban részletesen bemutattam a CDN alapfogalmait, ahol szó volt arról, hogy miként lehet a tartalmakat közelebb vinni a felhasználókhoz, csökkentve a késleltetést és tehermentesítve az eredeti szervereket. Utána írtam az AWS CDN megoldásáról is az AWS CloudFront szolgáltatásról.
Most egy lépéssel tovább megyünk, és megmutatom az Azure CDN-t, amely a Microsoft felhőszolgáltatásának egyik legfontosabb eleme. Gondoljunk bele: mi történik, ha egy nagy nemzetközi esemény közvetítése, egy webáruház kampányidőszaka vagy egy globális alkalmazás frissítése egyszerre több millió felhasználóhoz jut el? Ilyenkor mutatkozik meg igazán, mennyit ér egy jól felépített CDN.
Mi az Azure CDN?
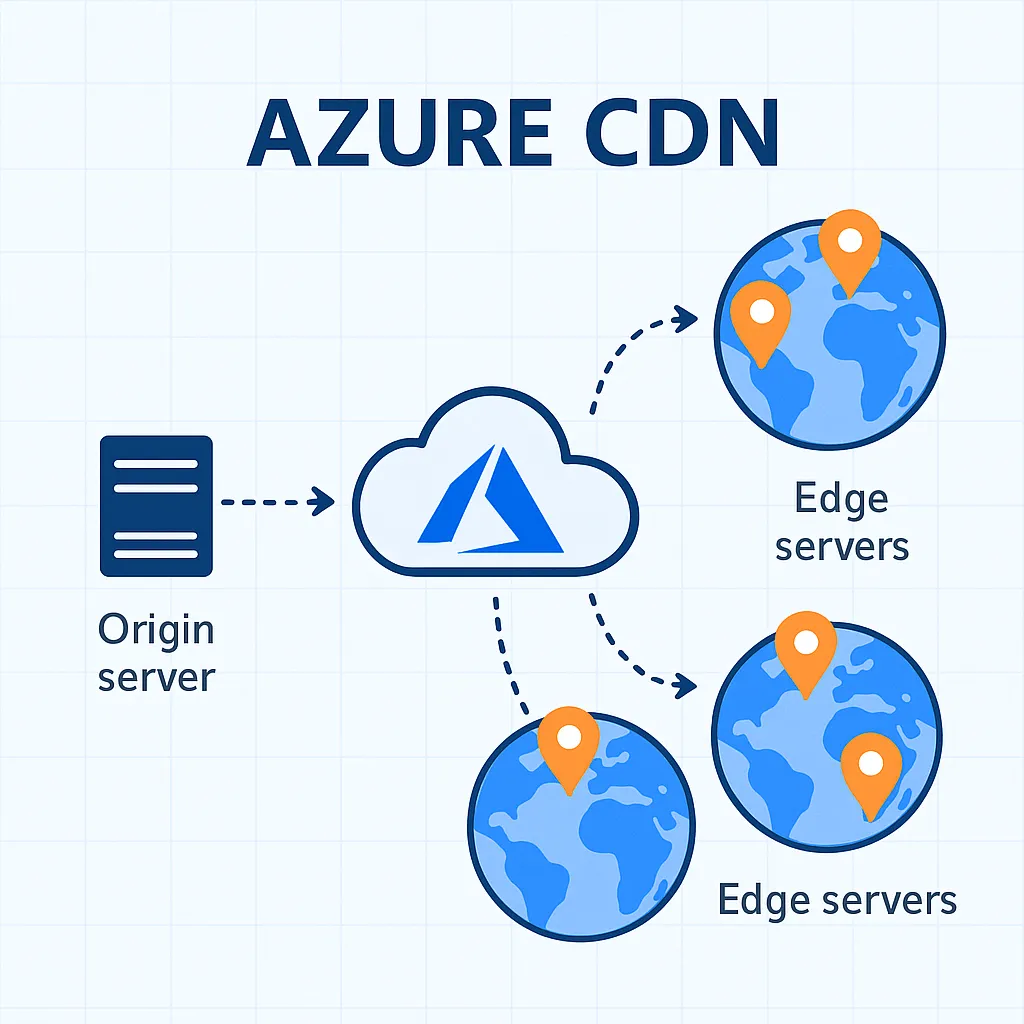
Az Azure Content Delivery Network (CDN) lényege, hogy a tartalmakat – legyen szó weboldalról, képekről, videókról vagy alkalmazásfájlokról – világszerte elérhető peremhálózati (edge) szervereken tárolja. Ezek a szerverek közelebb vannak a végfelhasználókhoz, így az adatok gyorsabban töltődnek be, csökken a hálózati késleltetés, és a felhasználói élmény jelentősen javul. Jelenleg kétféle háttérhálózaton érhető el:
Azure CDN from Microsoft, amely a Microsoft saját globális hálózatát használja.
Azure CDN from Edgio, amely korábban Verizon/Edgecast néven működött, de átnevezés után is elérhető opció maradt.
A korábbi Azure CDN from Akamai szolgáltatás 2023. októberében kivezetésre került, így ma már nem érhető el új előfizetők számára.
Erősségek
Globális jelenlét: a Microsoft saját hálózata és az Edgio közösen biztosítanak világszintű edge pontokat.
Biztonság:HTTPS támogatás, token alapú hitelesítés és modern titkosítási szabványok.
Rugalmasság: fejlett szabálykezelés a gyorsítótárazás finomhangolásához.
Analitika: részletes statisztikák a forgalomról és a teljesítményről.
Lehetőségek és korlátok
Az Azure CDN nem old meg minden teljesítményproblémát. Ha a tartalomforrás lassú vagy hibásan konfigurált, a CDN nem tudja ellensúlyozni. Emellett költséggel is jár: a globális adatforgalom és a speciális funkciók használata külön díjazás alá eshet. Fontos a gondos tervezés, hogy a szolgáltatás valóban értéket adjon.
Felhasználási esetek
Weboldalak:WordPress alapú oldalak esetén a képek és videók gyorsan betöltődnek bárhonnan a világon.
E-kereskedelem: nemzetközi webshopok stabil vásárlói élményt tudnak biztosítani csúcsidőben, például Black Friday alatt.
Streaming: videószolgáltatók számára akadozásmentes lejátszást biztosít még extrém terhelés mellett is.
Azure CDN és AWS CloudFront. Mikor?
Mindkét szolgáltatás globális lefedettséget, integrációt és biztonságot kínál.
Azure CDN: előnyös azoknak, akik elsősorban Microsoft-ökoszisztémát használnak.
AWS CloudFront: jobban illeszkedik az Amazon szolgáltatásaihoz, például az S3-hoz és a Lambda@Edge-hez.
A választás gyakran attól függ, melyik felhőszolgáltatót használja az adott szervezet elsődlegesen.
Összegzés
Az Azure CDN ideális választás minden olyan vállalat számára, amely globális jelenlétet, gyorsabb betöltődést és jobb felhasználói élményt szeretne biztosítani. Ez közvetlen üzleti előnyt is jelent: nagyobb konverziós arányt, elégedettebb ügyfeleket és jobb piaci megítélést.