

Golden image refresh: egységes OS-verzió egyszerűbben
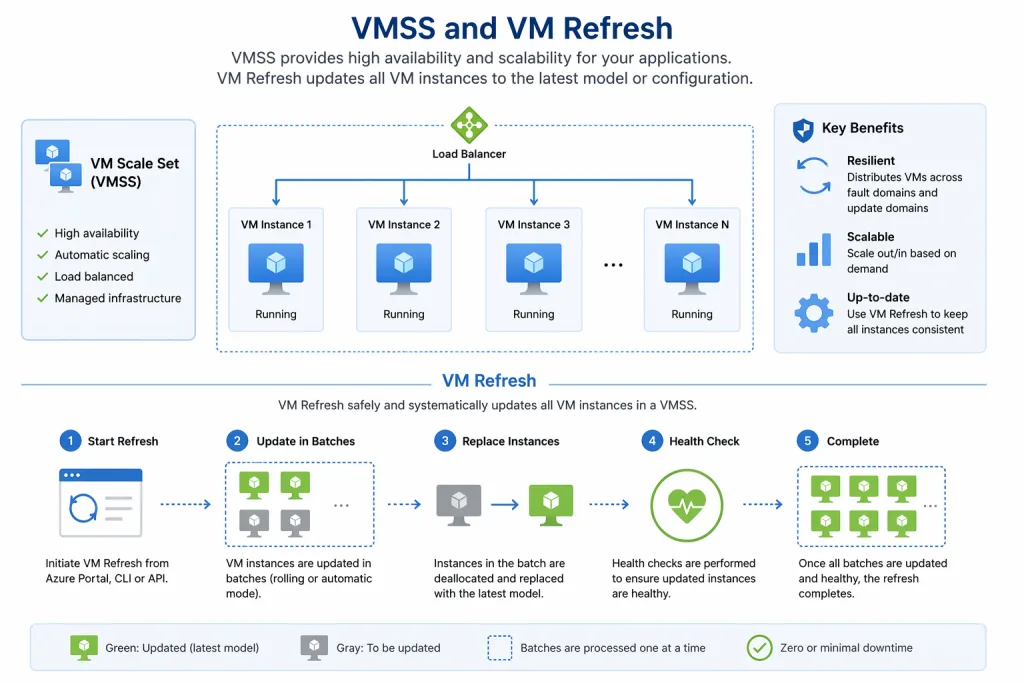
Amikor virtuális gépeken futnak a céges alkalmazások, hamar eljutunk a VMSS (virtuális gép-méretezési csoportok) használatának dilemmájához, hiszen könnyen skálázható, jól konfigurálható, magas rendelkezésre állású rendszereket lehet építeni. Ráadásul egyetlen ilyen cluster akár 1000 VM-ig is bővíthető.
Azonban ebben az esetben a VM-ek frissítése mindig extra időt és odafigyelést igényelt, mert általában nehézkes. Én magam is láttam olyan infrastruktúrát, ahol a DevOps csapat pontosan tudta, mit kellene frissíteni, de senki nem merte „megnyomni a gombot”, mert bármennyire is felkészültél, az élő rendszeren előfordult némi meglepetés.
Erre a problémára ad választ a Golden Image refresh stratégia, amely Azure-on ez egy strukturált, eszköztámogatott folyamat, így jelentősen megkönnyíti a verziókövetést, a pipeline-alapú frissítést és az auditálhatóságot azokhoz az időkhöz képest, amikor mindenki maga találta ki, hogyan tartja karban a szerver parkját.
Mi az a Golden Image?
A Golden Image egy előre összeállított, jóváhagyott rendszerkép – egy rögzített, verziókezelt sablon, amelyből az összes VM-et létrehozzák. A Golden Image általában négy dolgot tartalmaz kötelezően:
- előre telepített szoftverkörnyezet
- a szervezet belső compliance elvárásaihoz igazodó beállítások
- konfigurált és biztonsági szempontból „megerősített” operációs rendszer
- aktuális biztonsági frissírtések
Korábban a legelterjedtebb megközelítés az úgynevezett „update in place” volt: bejelentkeztél egy futó VM-be, elvégezted a frissítést, és reménykedtél, hogy a többi gép is hasonló állapotban van. Az idő előrehaladtával minden egyes gép máshogy nézett ki belülről – más kernel verzió, maradt tesztelési csomag, valaki feltelepített valamit, amit aztán elfelejtett eltávolítani. Ezt hívják snowflake server jelenségnek: minden gép egyedi és megismételhetetlen, és ezért egyre nehezebben kezelhető.
A Golden Image refresh ezzel szemben az immutable infrastructure (megváltoztathatatlan infrastruktúra) elvén alapul: a futó rendszert nem módosítod, hanem kicseréled egy tiszta, ellenőrzött állapotból indított új példányra.
Hogyan épül fel az architektúra?
A Golden Image refresh három rétegben működik, és a rétegek egymásra épülnek – ez az image dependency flow.
- Az első réteg maga a Golden Image, amelyet egy dedikált „Golden Image Team” publikál és verziókezel. Minden környezet – dev, staging, prod – saját fájlban rögzíti, hogy melyik Golden Image verziót használja. Automatikus frissítés nem történik: minden változás explicit, Git-ben követett döntés.
- A második réteg a custom image (egyedi képfájl), amelyet egy pipeline épít a Golden Image fölé. Ez tartalmazza az alkalmazásspecifikus konfigurációkat és függőségeket, és ez az, amit a VMSS deployment ténylegesen használ.
- A harmadik réteg a VMSS telepítés, amely a custom image alapján indítja a példányokat, és frissítéskor fokozatosan lecseréli azokat az új verzióra.
Ha a Golden Image frissül, az egész lánc lefut újra: a Golden Image Team publikál egy új verziót, a custom image pipeline lefut, új custom image verzió készül, és a VMSS instance-ek az új verzióra váltanak. A forgalom fokozatosan kerül át az új instance-ekre, a régieket pedig fázisosan vonják ki – így a szolgáltatás elérhető marad a folyamat alatt.
A VMSS frissítési folyamata lépésről lépésre
- Azonosítod az új Golden Image verziót a megfelelő Image Gallery-ben
- Feature branch-en frissíted a pkrvariables fájlt az új verzióra
- Merge request-en jóváhagyatod és beolvasztod a változást
- Lefuttatod a custom image pipeline-t, amely elkészíti az új custom image-t
- Telepíted az új képfájlt az operational pipeline-on keresztül vagy Terraform-al
Manual vs. automatic upgrade – és miért számít a különbség
VMSS esetén az alábbi két frissítési metódust használtuk korábban:
Az automatic upgrade esetén az összes instance egyszerre frissül. Ez gyors, de teljes vagy részleges leállással járhat – az alkalmazás addig nem elérhető, amíg az új instance-ek fel nem állnak. Ez az alapértelmezett mód.
A manual upgrade esetén a példányokat egyenként frissíted. A többi közben fut, az alkalmazás elérhető marad. Ez 10-15 percnyi teljesítménycsökkenéssel jár, de leállás nélkül.
Ami fölött még tapasztalt mérnökök is gyakran elsiklanak, hogy amikor frissítik a Terraform-kódot, majd lefuttatják a terraform apply parancsot a megfelelő beállítások ellenőrzése nélkül, akkor éles környezetben akár az összes instance egyszerre leállhat.
A manual módhoz először a provider.tf fájlban kell explicit beállítás:
provider "azurerm" {
features {
virtual_machine_scale_set {
reimage_on_manual_upgrade = false
roll_instances_when_required = false
}
}
}
Ezután a VMSS resource Terraform kódjában frissíteni kell a source_image_id értékét az új custom image verzióra, és az upgrade_mode paramétert "Manual"-ra kell állítani:
source_image_id = "/subscriptions/subscriptionid/resourceGroups/rgname/providers/Microsoft.Compute/images/confluence-prd-v-24052450"
upgrade_mode = "Manual"
automatic_instance_repair = [{
enabled = false
grace_period = "PT30M"
}]
computer_name_prefix = "Appname-prd"
overprovision = false
upgrade_mode = "Manual"
single_placement_group = true
secure_boot_enabled = false
A terraform apply lefuttatása után a VMSS szerver tagokat egyenként kell manuálisan frissíteni, hogy a szolgáltatás folyamatosan elérhető maradjon.
Hogyan oldja meg ezt a Golden Image refresh?
Az új image verzió publikálása után az instance-ek fokozatosan cserélődnek le. Az új, frissített image-ből épülő instance-ek fokozatosan veszik át a forgalmat, miközben a régi instance-ek még futnak. Csak akkor vonják ki a régieket, ha az újak már stabilan működnek. Ez azt jelenti, hogy sem teljes leállás, sem hosszú kézi folyamat nem szükséges – a frissítés kontrollált, visszakövethető és biztonságos.
Standalone VM-ek frissítése
A VMSS-sel ellentétben standalone VM-eknél nincs fleet és nincs fokozatos instance-csere, hanem minden VM önálló egység, amelyet külön kell kezelni. A Golden Image refresh itt is ugyanazt a célt szolgálja, de a folyamat egyszerűbb, és kevesebb mozgó részből áll.
Nem minden operációs rendszer verzióhoz készül automatikusan Golden Image. Ha egy adott OS verzióhoz már létezik Golden Image, a frissítés egyszerű: az új verzióra hivatkozol, és a folyamat a már ismert módon zajlik.
Ha viszont egy OS verzióhoz még nincs Golden Image – mert például régebbi vagy kevésbé elterjedt rendszerről van szó, amelyre a Golden Image Team még nem készített sablont – akkor custom image-t kell létrehozni. Ez azt jelenti, hogy te magad állítod össze azt a rendszerképet, amelyből a VM-et indítod, és a frissítés ennek verzióváltásával történik – például 1.0-ról 1.1-re.
Amit mindkét esetben fontos előre tudni: amikor a Terraform kódban megváltoztatod a source_image_id értékét, a Terraform nem frissíti a meglévő VM-et – hanem lecseréli. VMSS esetén ez fokozatosan, instance-enként történik. Standalone VM esetén viszont az egész erőforráscsoport érintett lehet. A terraform plan futtatásakor replace műveleteket fogsz látni az alábbi erőforrásokon:
- a VM maga
- az OS disk
- a data disk attachment-ek
- a role assignment-ek
- a VM extension
Ami megmarad és helyben frissül:
- a network interface
- a disk encryption set
Ez nem hiba – ez a várt viselkedés. De ha valaki nincs felkészülve rá, a terraform plan kimenete ijesztőnek tűnhet. Érdemes előre tudni, hogy pontosan ez fog történni, és ez a helyes működés.
Validáció és ellenőrzés
A deployment után nem elég, hogy lefutott a pipeline. Az elvárható ellenőrzési lépések: az instance-ek egészségi állapotának ellenőrzése, a sikeres provisionálás visszaigazolása, az alkalmazás és a szolgáltatások működésének verifikációja, valamint a scale set frissítési státuszának és hibamutatóinak figyelemmel kísérése.
Röviden:
- instance-ek egészségi állapotának ellenőrzése
- sikeres provisionálás visszaigazolása
- alkalmazás és szolgáltatások működésének verifikációja
- scale set frissítési státuszának és hibamutatóinak figyelemmel kísérése
Ez az a lépés, amelyet időnyomás alatt a legtöbben igyekeznek kihagyni, vagy lerövidíteni – és ahol a legtöbb utólagos incidens gyökere kereshető.
Ami ebből a legfontosabb
A Golden Image refresh nem egy bonyolult megoldás. Csupán egy másfajta szemlélet, amely bármekkora infrastruktúrán alkalmazható: ne frissíts futó rendszert, helyette cseréld ki egy tiszta, ellenőrzött állapotból indítottra. Az eszközök – Azure Image Gallery, Packer, Terraform – ma már elérhetők és jól dokumentáltak. A nehéz rész nem a technika, hanem a következetesség: verziókezelés, jóváhagyási folyamat, és az a döntés, hogy nem nyúlsz hozzá közvetlenül az élő géphez.
Szándékosan hagytam ki ebből a cikkből a monitoring konfigurációját, a health probe beállítását és az availability zone-ok közötti elosztást. Nem azért, mert nem fontosak – hanem mert ezeket csak akkor érdemes beállítani, ha az alapfolyamat már működik és érthető. Aki ezekre is kíváncsi, annak lesz folytatás.