Korábban már beszéltem az Azure-ről és az AWS-ről, mint lehetséges felhőplatformról 2026-ban. Ebben a videóban a Google Cloud Platformot (GCP) mutatom be, ami egy AI-first szemléletű felhő.
Az AI-first stratégia lényege, hogy a Google a mesterséges intelligenciát tette minden terméke és szolgáltatása alapvető mozgatórugójává, így az már nem csak egy extra funkció, hanem az elsődleges fejlesztési szempont. Ez a szemléletmód a felhasználóhoz alkalmazkodó, segítőkész technológiát és saját, specifikus hardveres infrastruktúrát (például TPU-kat) állít a cég teljes működésének középpontjába.
A Google Cloud egyik legnagyobb erőssége, hogy itt az AI nem kiegészítő, hanem alapértelmezett része a platformnak. A videóban szó lesz a Gemini modellcsaládról, a Vertex AI-ról, az adatplatformok szerepéről, és arról is, hogy kinek lehet jó választás a GCP.
Azt is elmondom, mikor nem ideális a Google Cloud, például klasszikus enterprise lift-and-shift megközelítés esetén.
Aki rendszeresen fejleszt vagy oktat AI megoldásokat – legyen szó Azure OpenAI-ról vagy bármilyen LLM integrációról –, az pontosan ismeri a problémát: a Retrieval-Augmented Generation (RAG) rendszerek lelke az adat, de az adataink többsége „halott” formátumokban csücsül. Itt jön képbe a Docling.
PDF-ek, Word dokumentumok, Excel táblák – Ezek emberi olvasásra kiválóak és látványosak, de a gépek számára gyakran emészthetetlenek.
Az Mentor KlubosAzure oktatásaim során rendszeresen bemutatom a klasszikus „Enterprise Chat” felépítést:
Feltöltünk fájlokat egy Azure Storage Account-ra.
Létrehozunk egy Azure AI Search indexet.
Az OpenAI Foundry Studio-ban összekötjük a modellt az adatokkal.
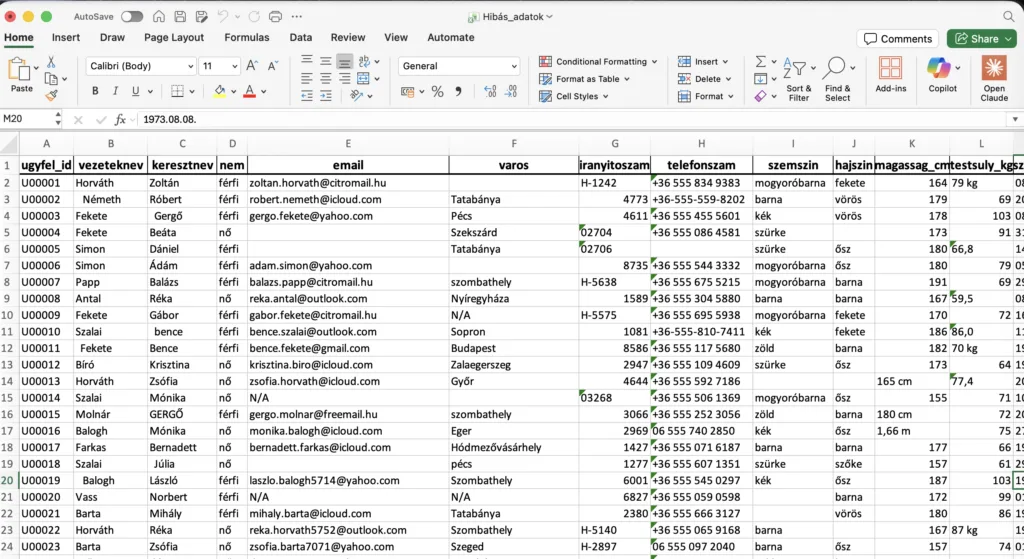
A demó mindig látványos, de a valóságban sokszor hiányérzete van a z oktatáson résztvevőknek. Miért? Mert ha egy PDF tele van táblázatokkal, hasábokkal vagy lábjegyzetekkel, a beépített „chunking” (daraboló) algoritmusok szétesett, értelmezhetetlen szövegmasszát adnak át a keresőnek. Ugyanez a probléma az Excel táblázatokkal is.
Nincs olyan képzés, amikor nem teszik fel a kérdést: „Excel táblában is képes keresni az AI?„ Korábban az volt a válaszom, hogy nem és valójában közvetlenül nem is tud benne keresni, még RAG esetén sem.
Az eredmény: a használt LLM hiába zseniális, ha a kereső rossz kontextust ad neki. Garbage In, Garbage Out.
A megoldás: Strukturált Markdown
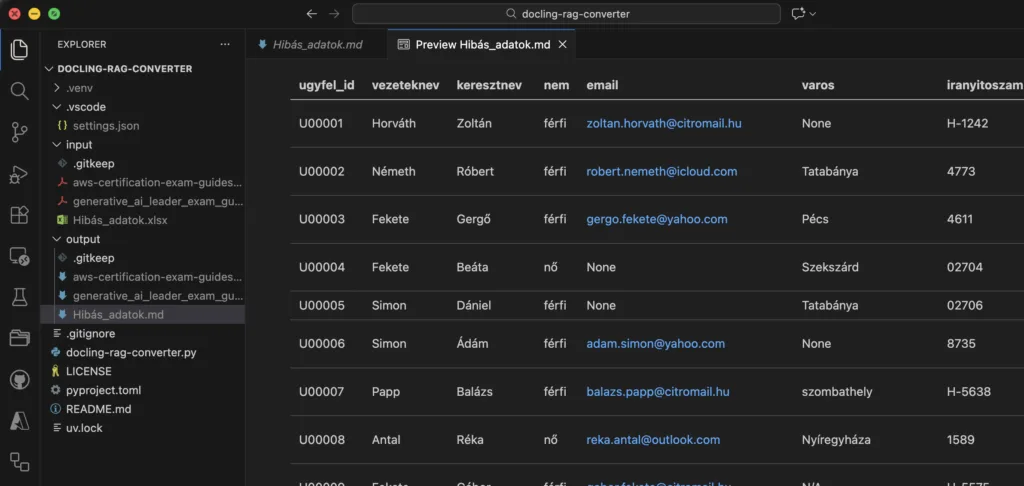
A tapasztalatom az, hogy az LLM-ek imádják a Markdown formátumot. A Markdown tisztán leírja, mi a főcím, mi az alcím, és ami a legfontosabb: megőrzi a táblázatok szerkezetét. Ezért a gyors és látványos bemutatóknál, már előkészített fájlokkal érkezem
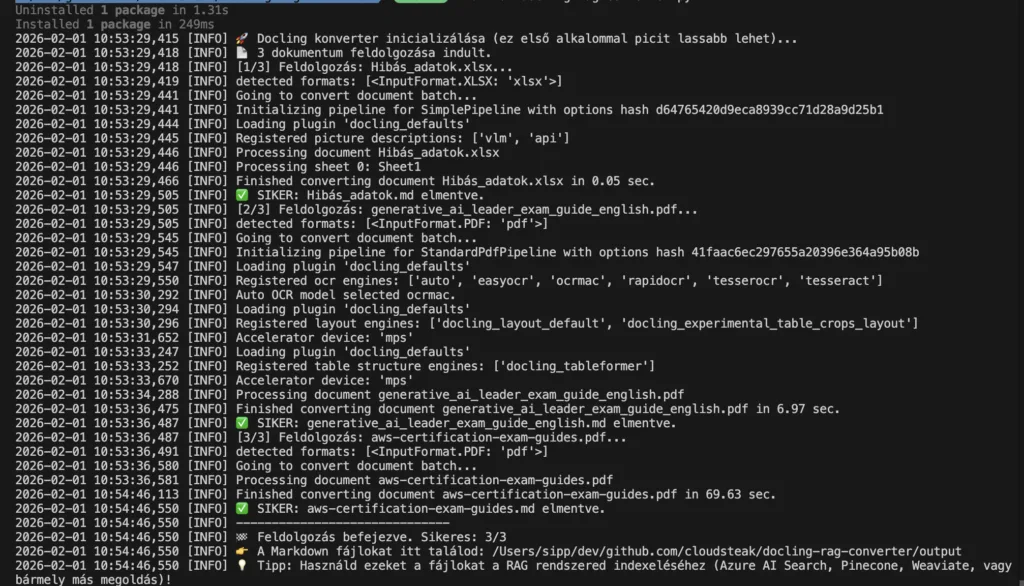
De ki akar kézzel konvertálni több száz, vagy több ezer vállalati PDF-et? Senki. Ezért hoztam létre egy egyszerű, bárki által használható megoldást, aminek a lelke a Docling.
Mi az a Docling?
A Docling egy új generációs, nyílt forráskódú megoldás, ami nem csak kiolvassa a szöveget a fájlokból, hanem látja és érti is az oldalak szerkezetét (Layout Analysis).
Míg a hagyományos konverterek (pl. PyPDF) gyakran sorról sorra olvassák a szöveget (így a kéthasábos cikkek összekeverednek), a Docling felismeri a blokkokat. Képes komplex táblázatokat, fejléceket és lábjegyzeteket is helyreállítani, és mindezt egy tiszta, strukturált Markdown fájlba menti.
Mondhatjuk, hogy ez a RAG szempontjából aranyat ér. Ha a Docling által generált .md fájlt adod oda az Azure AI Search-nek (vagy bármilyen más vektorkeresőnek), a válaszok pontossága drasztikusan javulni fog. Ezzel pedig időt és pénzt takaríthatunk meg.
A kész eszköz: Docling RAG Converter
Ha szeretnéd kipróbálni, hogyan is teljesít és ne kelljen a nulláról kódolnod, készítettem egy Python alapú eszközt, amit a GitHub-on közzé is tettem. Ez az egyszerű projekt egy számomra kedvelt alapra épül: a Python mellett az uv csomagkezelőt használja, ami villámgyors és brutálisan egyszerű használni is.
Nem kell Python gurunak lenned. A célom az volt, hogy bárki, aki RAG rendszert épít, pillanatok alatt elő tudja készíteni az adatait.
1. Előkészületek
Szükséged lesz a git-re és az uv-re. Ha az uv még nincs fent, egy sorral telepítheted:
Windows (PowerShell):powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
Mac/Linux:curl -LsSf https://astral.sh/uv/install.sh | sh
2. Töltsd le a kódot
Klónozd le a projektet a gépedre:
git clone https://github.com/cloudsteak/docling-rag-converter.git
cd docling-rag-converter
3. Futtasd a konvertert
Az uv zsenialitása, hogy nem kell manuálisan virtuális környezetet (venv) létrehoznod vagy pip-pel bajlódnod. A következő parancs mindent elintéz helyetted (letölti a Docling-ot, a függőségeket és a szükséges AI modelleket):
uv run docling-rag-converter.py
Hogyan működik?
Az első futtatáskor a script létrehoz egy input és egy output mappát. (ha szükséges, de ez része a projektnek)
Másold be a feldolgozni kívánt fájljaidat az input mappába (PDF, DOCX, XLSX, HTML, PPTX).
Futtasd újra az uv run docling-rag-converter.py parancsot.
Dőlj hátra. A script végigmegy a fájlokon, és az output mappába generálja a tökéletesen formázott .md fájlokat.
Miért jobb ez az Azure OpenAI-hoz?
Ha ezeket a generált Markdown fájlokat töltöd fel a Storage Account-ra a nyers PDF-ek vagy XLSX-ek helyett:
Jobb Chunking: Az Azure AI Search a Markdown fejlécek (#, ##) mentén logikusan tudja darabolni a szöveget. Nem vág ketté mondatokat vagy gondolatmeneteket.
Táblázat-értés: A nyelvi modell (pl. GPT-4o-mini) a Markdown táblázatokat kiválóan értelmezi. Ha megkérdezed, hogy „Mennyi volt a bevétel Q3-ban?”, a modell pontosan ki tudja olvasni a cellát, míg egy szétesett szövegből csak találgatna.
Kevesebb Hallucináció: Mivel a forrásanyag tiszta és strukturált, az AI kevésbé hajlamos kitalálni dolgokat.
Eredeti XLSX:
Konvertált md fájl (előnézetben), AI által támogatott formában:
Összegzés
A Docling használatával a „fekete doboz” PDF-ekből és Excel fájlokból strukturált, szemantikus Markdown-t csináltunk. Amikor ezt feltöltöd a Storage Account-ra, és indexeled a Foundry-ban, a kereső pontosan tudni fogja, hol kezdődik egy táblázat, és melyik adat melyik oszlophoz tartozik.
Az eredmény? Egy RAG alapú dokumentum keresési megoldás, amellyel az AI pontosan válaszol.
Ez a kis extra lépés a pipeline elején választja el a „játék” demókat a valódi, production-ready vállalati megoldásoktól. Próbáld ki a megoldást, és kezd el Te is AI-al kezelni a céges dokumentumokat, bármilyen RAG megoldással!
Te hogyan oldod meg az adat-előkészítést? Írd meg a véleményed vagy a tapasztalataidat kommentben!
Ha pedig érdekelnek a hasonló Azure és AI tartalmak:
Nem rég fejeztem be egy videós képzési anyagot a Mentor Klub részére, ahol a résztvevők megismerhették az Azure-on belül elérhető OpenAI megoldásokat. Ennek részeként bemutattam az Azure OpenAI Studio felületét is, ami valójában az Azure AI Foundry egyik funkcionális eleme. Mindkettőt elég gyakran használom, különböző projektekben és különböző célokra. Hogy éppen melyik a jobb egy adott feladathoz, azt többnyire az aktuális projekt igényei döntik el.
A Microsoft azonban az elmúlt hónapokban egy olyan változtatást indított el, amely alapjaiban alakítja át azt, ahogyan eddig AI-megoldásokat építettünk Azure-ban. A Foundry platform fokozatosan átveszi az Azure OpenAI Studio szerepét, kiszélesítve annak lehetőségeit és egységesítve az AI-fejlesztés teljes ökoszisztémáját.
Mi volt az Azure OpenAI Studio szerepe
A Microsoft az Azure OpenAI Studio felületet arra hozta létre, hogy egyszerű legyen kipróbálni és tesztelni az Azure által kínált OpenAI modelleket. A felület segítségével lehetett:
modelleket kipróbálni egy játszótérben
finomhangolt modelleket kezelni
API-végpontokat és kulcsokat elérni
kötegelt feldolgozást és tárolt befejezéseket használni
értékeléseket futtatni
és még sok hasznos AI programozást segítő funkciót.
Az Azure OpenAI Studio azonban alapvetően egy modelltípusra, az Azure által értékesített OpenAI modellekre épült. Ez a projektjeim során is érezhető volt: ha más modellgyártó megoldását szerettem volna használni, akkor azt külön kellett integrálni vagy külső szolgáltatásból kellett elérni.
Ez az a pont, ahol a Foundry teljesen más szemléletet hoz.
Mit kínál a Microsoft Foundry?
A Microsoft Foundry egy egységes AI-platform, amely több modellszolgáltatót, több szolgáltatást és teljes életciklus-kezelést egy felületre hoz. A Microsoft Learn dokumentum így fogalmaz: a Foundry egy nagyvállalati szintű platform, amely ügynököket, modelleket és fejlesztői eszközöket egy helyen kezel, kiegészítve beépített felügyeleti, monitorozási és értékelési képességekkel .
A legfontosabb különbségek a következők.
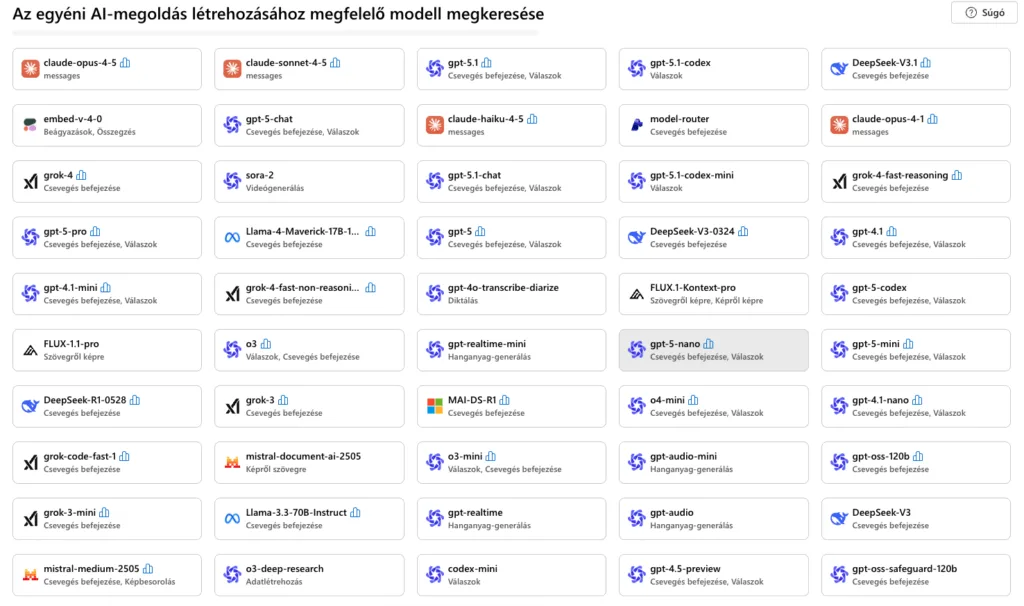
Széles modellkínálat
Az Azure OpenAI-val szemben a Foundry nem korlátozódik egyetlen gyártóra. Elérhetők többek között:
Azure OpenAI modellek
DeepSeek
Meta
Mistral
xAI
Black Forest Labs
Stability, Cohere és más közösségi modellek
És ez még csak a jéghegy csúcsa.
Ügynökszolgáltatás és többügynökös alkalmazások (AgenticAI)
A Foundry API kifejezetten ügynökalapú fejlesztéshez készült, ahol több modell és komponens együttműködésére van szükség.
Egységes API különböző modellekhez
A Foundry egységes API-t biztosít, így a fejlesztőnek nem kell minden gyártó logikáját külön megtanulnia.
Vállalati funkciók beépítve
A Foundry felületén eleve jelen vannak:
nyomkövetés
monitorozás
értékelések
integrált RBAC és szabályzatok
hálózati és biztonsági beállítások
Gyakorlatilag, minden ami a nagyvállalati és biztonságos működéshez elengedhetetlen.
Projektalapú működés
A Foundry projektek olyan elkülönített munkaterületek, amelyekhez külön hozzáférés, külön adatkészletek és külön tároló tartozik. Így egy projektben lehet modelleket, ügynököket, fájlokat és indexeket is kezelni anélkül, hogy más projektekhez keverednének.
Amikor még csak Azure OpenAI-val dolgoztam, előfordult, hogy egy ügyfél Meta vagy Mistral modellt szeretett volna kipróbálni összehasonlításként. Ezt külön rendszerben kellett megoldani. A Foundry megjelenésével ugyanabban a projektben elérhetővé vált:
GPT-típusú modell
Mistral
Meta
DeepSeek
és még sok más
Egy projekten belül egyszerre lehet kísérletezni, mérni és értékelni különböző modellek viselkedését.
Mit jelent ez a felhőben dolgozó szakembereknek
A Foundry nem egyszerűen egy új kezelőfelület. A gyakorlati előnyei:
Egységes platform, kevesebb különálló eszköz
Könnyebb modellválasztás és modellváltás
Átláthatóbb üzemeltetés, biztonság és hálózatkezelés
Bővíthető modellkínálat
Konszolidált fejlesztői élmény és API
A dokumentáció többször hangsúlyozza, hogy a Foundry nemcsak kísérletezésre, hanem üzleti szintű, gyártásra kész alkalmazásokra is alkalmas. Ez a mindennapi munkában is érezhető.
Miért előnyös ez a vállalatoknak
A vállalatok számára a Foundry több szempontból stratégiai előrelépés:
Egységes biztonsági és megfelelőségi keretrendszer
Több modellgyártó támogatása egy platformon
Könnyebb üzemeltetési kontroll
Gyorsabb AI-bevezetési ciklus
Rugalmasabb fejlesztési irányok
A Foundry megjelenésével a cégek már nem csak egyetlen modellre vagy ökoszisztémára építenek, hanem több szolgáltató képességét is bevonhatják anélkül, hogy töredezett lenne a rendszer.
Tulajdonság
Azure OpenAI
Foundry
Közvetlenül az Azure által értékesített modellek
Csak Azure OpenAI
Azure OpenAI, Black Forest Labs, DeepSeek, Meta, xAI, Mistral, Microsoft
Partner és Közösség modellek a Marketplace-en keresztül – Stability, Cohere stb.
✅
Azure OpenAI API (köteg, tárolt befejezések, finomhangolás, értékelés stb.)
Az Azure OpenAI Studio jó kiindulási pont volt az Azure AI-képességeinek megismerésére és modellek kipróbálására.
A Microsoft Foundry azonban túlnő ezen a szerepen: egységes platformot biztosít a teljes AI-fejlesztési életciklushoz, több modellgyártóval és kiterjesztett vállalati funkciókkal.
A Microsoft nem leváltja az Azure OpenAI-t, hanem beépíti egy nagyobb, átfogóbb rendszerbe. Ez a lépés hosszú távon kiszámíthatóbb, hatékonyabb és sokkal rugalmasabb AI-fejlesztést tesz lehetővé.
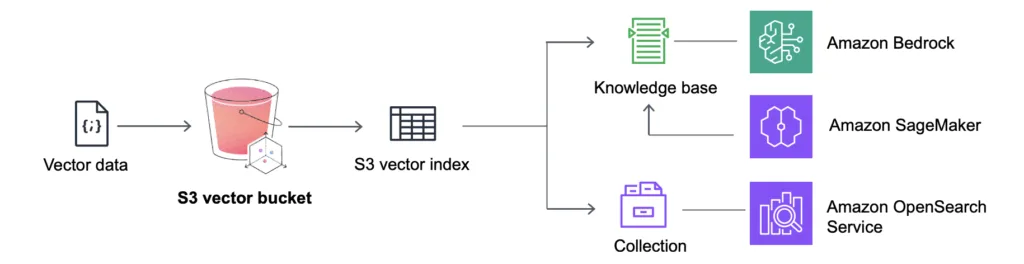
Eddig is úgy gondoltam, hogy az Amazon S3 a világ legjobb felhő tárolási megoldása, hiszen olyan széleskörűen, egyszerűen és költséghatékonyan használható, hogy azzal magasan lekörözi versenytársait.
Teszi ezt úgy, hogy az AI megjelenésével továbbra is az egyik legszélesebb körben használható tárolási megoldás maradt. Az Amazon azonban nem elégedett meg ezzel, hanem tovább dolgozott és nemrég be is jelentették, hogy az Amazon S3 mostantól natívan támogatja a vektorokat.
Ez nem csupán egy egyszerű frissítés, hanem egy komoly lépés afelé, hogy az AI-alapú keresések és alkalmazások még gyorsabbak és hatékonyabbak legyenek, ráadásul közvetlenül ott, ahol az adatokat tároljuk: az S3-ban.
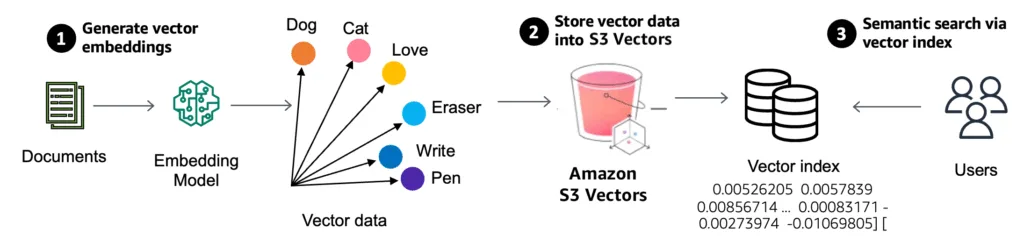
Mi is az az Amazon S3 Vector?
Az Amazon S3 Vector egy új lehetőség arra, hogy vektorokat – azaz gépi tanulási modellekből származó tömörített adatreprezentációkat – natívan tároljak és kereshetővé tegyek az S3-ban. Korábban, ha például képeket, szövegeket vagy videókat szerettem volna hasonlóság alapján keresni, az adataimat először külön vektor adatbázisba kellett töltenem (pl. Weaviate), ahol a hasonlóságkeresést elvégezhettem. Mostantól ez közvetlenül az S3-ban is elérhető.
Ez hatalmas előrelépés – nemcsak egyszerűsíti az architektúrát, hanem csökkenti a késleltetést, az összetettséget és a költségeket is.
Vector Store (vektortár) – Ebbe töltöm fel a vektorokat és a hozzájuk tartozó metainformációkat.
Ingest API – Ezen keresztül adhatom meg a vektorokat és az indexelendő adatokat.
Query API – Ezzel tudok hasonlóság alapján keresni (pl. „melyik képek hasonlítanak erre a képre?”)
Minden vektor egy rekord részeként kerül be, amely lehetővé teszi, hogy ne csak vektor alapján, hanem metaadatok szerint is tudjak szűrni, például dátum, fájltípus vagy címke alapján.
Példák a használatra
1. Dokumentumkeresés
Egy nagy mennyiségű belső dokumentumot tartalmazó gyűjteményben szerettem volna hasonló jelentésű dokumentumokat megtalálni. Ahelyett, hogy kulcsszavas keresést használtam volna, minden dokumentumhoz vektort generáltam egy nyelvi modell segítségével, és azokat töltöttem fel az S3 Vectorba.
Ezután egy új keresés során elég volt megadnom egy kérdést vagy egy rövid szövegrészletet – és az S3 azonnal visszaadta azokat a dokumentumokat, amelyek a legjobban illeszkedtek a jelentésük alapján.
2. Képalapú hasonlóságkeresés
Egy e-kereskedelmi oldalon képek alapján szerettem volna hasonló termékeket ajánlani. A termékfotókat vektorizáltam egy gépi látás modell segítségével, majd betöltöttem az S3 Vectorba. Így amikor egy vásárló feltöltött egy képet, a rendszer pillanatok alatt megtalálta a hozzá leginkább hasonlító termékeket – anélkül, hogy külön vektor-adatbázist kellett volna karbantartanom.
Miben más ez, mint a meglévő megoldások?
A legtöbb vektoros keresési rendszer eddig úgy működött, hogy külön adatbázist kellett használni (pl. Pinecone, Weaviate, FAISS, Qdrant). Ez viszont újabb infrastruktúrát, szinkronizációs feladatokat és összetettebb architektúrát igényelt. Az Amazon S3 Vector ezt az egészet leegyszerűsíti: egy helyen tárolom és keresem az adatokat.
Azt is kiemelném, hogy mivel az S3 Vector az Express One Zone megoldásra épül, ezért alacsony késleltetésű hozzáférést kapok – mindezt az S3 skálázhatóságával és megbízhatóságával együtt.
Korlátok és tudnivalók
Természetesen nem minden esetben ez a legjobb megoldás. A jelenlegi verzió:
csak az S3 Express One Zone-on keresztül működik,
maximum 250 kB méretű rekordokat támogat,
és előzetes (preview) státuszban van, így még nem éles környezetbe szánt végleges termék.
A vektorok betöltéséhez és a keresésekhez is REST API-t használhatok, de egyelőre nincs közvetlen AWS konzolos támogatás.
Mikor érdemes használni?
Én akkor fogom választani az S3 Vector-t, ha:
már eleve S3-ban tárolok adatokat (képeket, szövegeket),
AI-alapú hasonlóságkeresésre van szükségem,
és szeretném leegyszerűsíteni az architektúrát, elkerülve a külön vektor-adatbázisokat.
Összegzés
Az Amazon S3 Vector egy fontos mérföldkő a natív, felhőalapú AI-alkalmazások területén. Ha te is vektoros keresést építenél, és az adataid már most is S3-ban vannak, akkor ez egy kiváló lehetőség arra, hogy gyorsan és hatékonyan vezess be intelligens keresési képességeket – közvetlenül a tárhelyeden.
Ha szeretnél még többet megtudni, akkor becsatolom ide a hivatalos blog cikket.
Én biztosan tesztelek vele a következő AI-projektem során. Ha te is érdeklődsz a hasonló technológiák iránt, most érdemes elkezdeni a kísérletezést.
A generatív mesterséges intelligencia világában már nem csak az számít, milyen nagy egy modell vagy hány milliárd paramétere van. Az is legalább ennyire fontos, hogyan tudjuk kiegészíteni és finomítani a modell működését. Korábban írtam a Retrieval-Augmented Generation (RAG) működéséről és előnyeiről. Most egy viszonylag új, de egyre nagyobb figyelmet kapó megközelítésről írok: ez a Cache-Augmented Generation (CAG).
Ebben a cikkben bemutatom, mit jelent a CAG, hogyan működik, miben más, mint a RAG, és mikor érdemes egyik vagy másik módszert választani.
Hogyan jutottunk el a RAG-tól a CAG-ig?
Amikor a nagy nyelvi modellek (LLM-ek) elterjedtek, hamar kiderült, hogy zárt tudású modellekkel nem tudjuk tartani a lépést a világ gyorsan változó információival. Ez hívta életre a RAG koncepcióját, ahol a modell a válasz előtt külső forrásokból (pl. céges dokumentumtárból, tudásbázisból) keres információt, és ezt beemeli a generálásba.
A RAG tehát egyfajta „keresés + válasz” kombinációt jelentett.
Később azonban új kihívások merültek fel:
nőtt a felhasználói igény a valós idejű válaszadásra,
sok rendszerben ismétlődő kérdések jelentkeztek,
és a RAG-es lekérdezések nem mindig voltak költséghatékonyak.
Ez vezetett el a Cache-Augmented Generation (CAG) gondolatához: ha egyszer már válaszoltunk valamire, miért ne tárolnánk el?
Mi az a Cache-Augmented Generation (CAG)?
A CAG lényege, hogy a generatív modell működését nem külső dokumentumokkal támogatjuk meg (mint a RAG esetén), hanem egy belső gyorsítótárra (cache) építünk, amely korábbi válaszokat vagy tudáselemeket tárol. Ez a cache lehet előre feltöltött (pl. sablonos kérdésekre adott válaszokkal), vagy dinamikusan épülhet ki a felhasználók aktivitása alapján.
A CAG technikai alapjai – amit érdemes tudni
A modern CAG-rendszerek több trükköt is bevetnek a hatékonyság növeléséhez:
Előzetes betöltés (Preloading) a kontextusablakba – a modell „látóterébe” már előre bekerül a fontos tudásanyag.
KV-cache (Key-Value Cache) – a modell tárolja a korábban generált tokenekhez tartozó rejtett állapotokat, így újrahasznosíthatók.
Hasonlóság-alapú visszakeresés – a rendszer nemcsak azonos promptokra reagál, hanem felismeri a jelentésbeli hasonlóságokat is.
Hogyan különbözik a CAG a RAG-től?
A RAG működéséhez elengedhetetlen egy jól strukturált tudásbázis. A modell először lekérdezi a számára releváns dokumentumokat, majd ezek alapján alkot választ. Ezzel szemben a CAG nem keres semmit, hanem a saját „emlékezetére” támaszkodik.
Szempont
RAG
CAG
Tudásforrás
Külső (pl. dokumentumok, adatbázis)
Belső (cache, előre betöltött tudás)
Teljesítmény (sebesség)
Lassabb a keresés miatt
Nagyon gyors, különösen ismétlődő kérdésekre
Erőforrásigény
Magasabb
Alacsonyabb
Pontosság friss információnál
Magas (aktuális tudás elérhető)
Korlátozott (nincs frissítés automatikusan)
Ideális alkalmazás
Dokumentumkereső, intelligens asszisztens
Ügyfélszolgálat, chatbot, sablonos válaszok
Valós példák RAG és CAG alkalmazásra
RAG példa: Képzeld el, hogy van egy cég belső dokumentumtára, ahol a HR, pénzügy és IT leírások PDF-ben elérhetők. Ha egy dolgozó megkérdezi: „Hány nap szabadság jár 3 év munkaviszony után?”, a RAG-alapú asszisztens lekérdezi a vonatkozó HR-dokumentumot, beemeli a szövegbe, és ennek alapján ad választ.
CAG példa: Ugyanez a dolgozó hetente ötször kérdezi meg: „Hogyan tudom megváltoztatni a jelszavam?” – a rendszer ezt a kérdést egyszer már megválaszolta. A CAG gyorsítótára felismeri az ismétlődést, és azonnal visszaadja a korábbi választ, teljes generálás nélkül.
RAG + CAG együtt
Egy ideig úgy tekintettünk a RAG és a CAG módszerekre, mint egymással versengő megoldásokra. Én viszont azt tapasztalom, hogy nem kizárják, hanem épp kiegészítik egymást.
Egy modern AI rendszer például működhet így:
Első lépés: a rendszer megvizsgálja, van-e releváns találat a cache-ben (CAG).
Ha nincs megfelelő találat, akkor lekérdez egy külső tudásbázist (RAG) és generál egy új választ.
Ez az új válasz eltárolódik a cache-ben, így legközelebb már gyorsabban és olcsóbban elérhető.
Ez a lépcsőzetes logika optimalizálja az erőforrás-használatot, miközben nem mond le sem a sebességről, sem a pontosságról.
Én úgy látom, hogy a jövő generatív rendszerei ezt a kettős stratégiát fogják követni: a CAG biztosítja a gyorsaságot és kiszámíthatóságot, míg a RAG gondoskodik a mély, megalapozott válaszokról. A kettő együtt nemcsak hatékonyabbá teszi a rendszert, hanem javítja a felhasználói élményt is.
Mely AI modellek használják ezeket?
RAG-et használ:
OpenAI GPT + retrieveres példák (pl. ChatGPT Enterprise tudásbázis integráció)
Mistral nyílt forrású LLM-ek kontextusablakos gyors betöltéssel
GPT-4 Turbo – optimalizált KV-cache rendszerrel működik, nagy prompt ismétlések esetén gyorsabb válasz
Claude 3 (Anthropic) – cache-szerű belső rejtett állapotkezelést használ kontextuson belül
Egyes cégek saját implementációi (pl. HelpDesk-rendszerek belső cache-sel)
Összefoglalás
A CAG nem egy újabb buzzword – hanem egy valódi válasz a generatív AI rendszerek skálázhatósági és sebességbeli kihívásaira. A RAG továbbra is verhetetlen, ha friss, kontextusban gazdag válaszokra van szükség. A CAG viszont ott nyer, ahol gyorsaság, egyszerűség és alacsony költség a cél.
Én egyre gyakrabban építek be CAG-alapú logikát a prototípusaimba, főleg akkor, ha nagy felhasználószámra kell tervezni. Ha pedig RAG-re van szükség, már tudom, mikor és hogyan érdemes bevetni.
A jövő generatív rendszerei nem választanak egyet a kettő közül – hanem dinamikusan kombinálják őket.
Előző cikkemben bemutattam az RAG alapjait, koncepcióját és főbb összetevőit. Amint olvashattuk a Retrieval-Augmented Generation (RAG) egyedülálló ereje abban rejlik, hogy képes releváns dokumentumokból és adatforrásokból valós időben információt visszanyerni és azt integrálni generált válaszaiba.
Abban a cikkben is említettem, hogy a RAG célja az, hogy az AI modellek ne csak logikus és összefüggő válaszokat adjanak, hanem azokat a legfrissebb és legpontosabb információk alapján állítsák elő. Ez különösen hasznos olyan területeken, ahol az adatok gyorsan változnak, például jogi, pénzügyi vagy technológiai területeken. Emellett olyan esetekben előnyös, amikor fontos számunkra az adatok pontossága. (pl.: AI alapú keresés dokumentum tárakban)
Ez a cikk a RAG-hoz kapcsolódó dokumentumkezelési technológiákra fókuszál, amelyek kulcsszerepet játszanak a rendszer hatékonyságában és pontosságában. Úgy érzem, hogy ez az a terület, ahol jelenleg a legkevesebb zaj van az AI világán belül.
Vektor adatbázisok
A vektor adatbázisok (dokumentumtárak) a RAG alapvető elemei. Ezek olyan adatbázisok, amelyekben a dokumentumokat és az azokban lévő információkat numerikus vektorokként tárolják. Ez lehetővé teszi a gyors és pontos keresést a releváns tartalmak között, a következő módon:
Dokumentumok átalakítása (embedding): A dokumentumok tartalmát vektorrá (számmá) alakítjuk természetes nyelvi feldolgozó modellek, például BERT vagy más embedding modellek segítségével.
Keresés (search): Egy új kérdés esetén a rendszer szintén vektort generál, majd ezt összehasonlítja az adatbázisban lévő vektorokkal, hogy megtalálja a releváns dokumentumokat.
Ebből is látszik, hogy amikor ilyen keresést végzünk, akkor nem kulcsszavakra keresünk, hanem összehasonlítást végzünk, így a találatok pontossága is más jellegű lesz.
Az embedding technológiák a RAG rendszerek motorjai. Az embedding lépésben a szöveges adatokat numerikus vektorokká alakítják, amelyek tartalmazzák a szöveg jelentését és kontextusát. Ez kulcsfontosságú a hasonlósági kereséshez, amely a releváns információk megtalálásának egyik alapvető eszköze.
Példa: Egy orvosi dokumentumtárban a „szívritmuszavar” kifejezés numerikus vektora alapján a rendszer az összes releváns tanulmányt és cikket előkeresheti.
Modellek: Olyan nyílt forráskódú modellek, mint a Sentence-BERT vagy a Hugging Face embedding modelljei, széles körben használatosak a RAG rendszerekben.
Újrarangsorolás (Reranking)
A RAG rendszerek gyakran több releváns dokumentumot is visszakeresnek, amelyeket rangsorolni kell. Az újrarangsorolás célja, hogy a leginkább releváns dokumentumok kerüljenek at LLM elé. Ez különösen fontos nagy méretű dokumentumtárak esetén.
Példa: Egy ügyfélszolgálati alkalmazás esetén a rendszer kiemeli a legfrissebb dokumentumokat a relevancia növelése érdekében. Vagy az első körben összegyűjtött információhalmazt tovább finomítjuk, hogy valóban csak a legrelevánsabb találatokat adjuk vissza a felhasználónak.
A lekérdezés fordítási technikák olyan lépések sorozatát foglalják magukban, amelyek javítják a lekérdezés átalakítás (embedding) és a dokumentum átalakítás közötti relevancia valószínűségét. Ez a folyamat biztosítja, hogy a kérdések pontosabban illeszkedjenek a dokumentumokhoz, javítva ezzel a visszakeresés és a válaszgenerálás minőségét.
Néhány kapcsolódó technika:
Szemantikai illeszkedés javítása: A technikák közé tartozik a szemantikai keresés alkalmazása, amely figyelembe veszi a szavak jelentését és kontextusát, nem csupán a szintaktikai egyezéseket. Ez különösen fontos a természetes nyelvű lekérdezések esetében, ahol a felhasználók különböző módon fogalmazhatják meg ugyanazt a kérést.
Lekérdezés elemzése és finomítása: A felhasználói kérdések gyakran többértelműek lehetnek. Ezen technikák célja, hogy ezeket a lekérdezéseket pontosítsák, szinonimákat vagy kapcsolódó kifejezéseket azonosítsanak, és szükség esetén a lekérdezést újrafogalmazzák a relevancia növelése érdekében.
Átalakítás (embedding) optimalizálása: A lekérdezéseket és a dokumentumokat numerikus vektorokká alakítják, és a lekérdezés fordítás során a cél az, hogy a lekérdezés embedding minél közelebb kerüljön a releváns dokumentumok beágyazásaihoz a vektortérben, ezáltal növelve a releváns találatok valószínűségét.
Ezen kívül még vannak egyéb technikák is, amelyeket majd a konkrét példáknál ismertetek.
Miért fontosak ezek a technológiák?
A dokumentumkezelési technológiák integrálása kulcsfontosságú a RAG rendszerek sikeréhez. Ezek az eszközök biztosítják a pontos, releváns és gyors információ-visszakeresést, ami elengedhetetlen a magas színvonalú generált válaszokhoz. Az olyan területeken, mint az egészségügy, a pénzügyek és az oktatás, ezek a technológiák forradalmasíthatják az adatokhoz való hozzáférést.
A RAG rendszerek és a dokumentumkezelési technológiák folyamatos fejlődése lehetővé teszi, hogy az AI rendszerek egyre intelligensebbé és hatékonyabbá váljanak. Ahogy ezek az eszközök egyre jobban integrálódnak a mindennapi életbe, várhatóan tovább növelik a mesterséges intelligencia alkalmazási lehetőségeit.
A jobb érthetőség kedvéért, hamarosan konkrét megoldásokkal is jelentkezem ebben a témában. 🙂
Talán már unalmasan hangzik, de ezt a cikket is így kell kezdenem. A mesterséges intelligencia (AI) gyors fejlődése során egyre több olyan technológia és módszertan jelenik meg, amely segít az információk hatékonyabb feldolgozásában és a felhasználók igényeinek pontosabb kielégítésében. Az egyik ilyen technológia a Retrieval-Augmented Generation (röviden RAG), amely az AI világának egy izgalmas területe. Számomra is ez jelenleg az egyik legérdekesebb terület.
RAG Alapok: Mi is az a Retrieval-Augmented Generation?
A RAG technológia lehetővé teszi, hogy a mesterséges intelligencia rendszerek pontosabb, tényszerűbb és relevánsabb válaszokat adjanak különböző kérdésekre, mivel képesek valós időben külső forrásokból származó információkat integrálni a működésükbe. Ezzel minimalizálva az AI egyik sajátosságát a hallucinációt. Emelett egy AI-al erősített dokumentumkezelést valósíthatunk meg.
A generatív mesterséges intelligencia (Generative AI), mint például a GPT modellek, kiválóan alkalmasak a természetes nyelvű szövegek előállítására. Azonban ezek a modellek kizárólag az előzetes tanulás során betáplált adatok alapján dolgoznak, amelyek idővel elavulhatnak. Itt jön képbe a RAG, amely kiegészíti a generatív képességeket azáltal, hogy valós idejű információk kinyerését is lehetővé teszi. Ez különösen fontos az olyan helyzetekben, amikor az aktuális vagy változó információk elérése létfontosságú.
Mi a koncepció?
A Retrieval-Augmented Generation egy olyan technika, amely két különböző, de egymást kiegészítő AI-komponenst ötvöz: az információ-visszakeresést (retrieval) és a szövegalkotást (generation). Ez a megközelítés a következőképpen működik:
Kérdés: A felhasználó egy kérdést tesz fel vagy egy információs kérést küld a rendszernek. Ezt a prompt engineering technikájával valósítja meg.
Információ-visszakeresés: A RAG rendszer első lépésként külső adatforrásokban (pl.: adatbázisokban, dokumentumtárakban vagy weboldalakon) keres releváns adatokat a kérdés megválaszolásához.
Adatok integrálása: Az így összegyűjtött adatokat továbbítja a generatív modellhez (LLM), amely ezek alapján állítja elő a választ.
Válasz generálása: A generatív modell egy koherens, természetes nyelvű választ ad, amely tartalmazza a visszakeresett információkat.
A RAG célja tehát az, hogy az AI modellek ne csak logikus és összefüggő válaszokat adjanak, hanem azokat a legfrissebb és legpontosabb információk alapján állítsák elő. Ez különösen hasznos olyan területeken, ahol az adatok gyorsan változnak, például jogi, pénzügyi vagy technológiai területeken. Emellett olyan esetekben előnyös, amikor fontos számunkra az adatok pontossága. (pl.: AI alapú keresés dokumentum tárakban)
A RAG alapvető komponensei
Habár a RAG egyszerű szolgáltatásnak tűnik, szükséges a fontosabb komponensek ismerete, amely segít megérteni és helyesen használni azt.
Retrieval modul: Ez az a rész, amely az adatok kinyeréséért felelős. A modell egy külső forrásból, például egy vektoradatbázisból, dokumentumtárból vagy más adattárolóból keres ki releváns információkat.
Generációs modul: Ez a generatív nyelvi modell, amely a kinyert adatokat felhasználva állítja elő a választ. Példa lehet erre a GPT-4 vagy más LLM-ek.
Integrációs réteg: Ez köti össze a két modult, biztosítva, hogy a kinyert adatok megfelelő formátumban és kontextusban kerüljenek a generációs modell elé.
Fontos megjegyezni, hogy a generatív modulnál a nyelvi modell (LLM) nem feltétlenül egy nyilvános kell hogy legyen. Tehát nem kell olyan modellt használnunk, amely internet kapcsolattal rendelkezik. Ez azért fontos nekünk, mert így egy teljesen zárt, izolált és biztonságos dokumentum kezelést is megvalósíthatunk a cégünkön belül.
Hogyan kapcsolódik a RAG az AI világához?
Ez ez érdekes kérdés lehet, annak ellenére, hogy az AI-ról beszélve említjük ezt a technológiát. A RAG technológia közvetlenül megoldja az AI egyik legnagyobb problémáját: naprakész információk kezelésére. Míg a hagyományos nyelvi modellek (LLM-ek) az előzetes tanulásuk során szerzett ismeretekre támaszkodnak, a RAG lehetőséget ad a valós idejű információk integrálására. Ez kulcsfontosságú olyan területeken, mint:
Ügyfélszolgálat: Releváns és aktuális válaszok biztosítása a vállalati dokumentációk és szabályzatok alapján.
Orvosi kutatás: Legfrissebb tudományos eredmények integrálása a diagnózis támogatásába.
Oktatás: Pontos, hiteles válaszok nyújtása a tananyagok alapján az aktuális technológia területén.
Miért fontos a RAG?
A RAG technológia jelentősége abban rejlik, hogy egyesíti a generatív modellek kreativitását és a tényszerű adatok pontosságát. Ezáltal képes olyan megoldásokat nyújtani, amelyek nemcsak modernek, hanem hitelesek is. A jövőben a RAG szerepe várhatóan tovább növekszik, különösen az olyan iparágakban, ahol az információk megbízhatósága és aktualitása kulcsfontosságú.
A RAG valódi ereje a dokumentum kezelésben rejlik, amelyről a következő cikkben olvashattok majd.