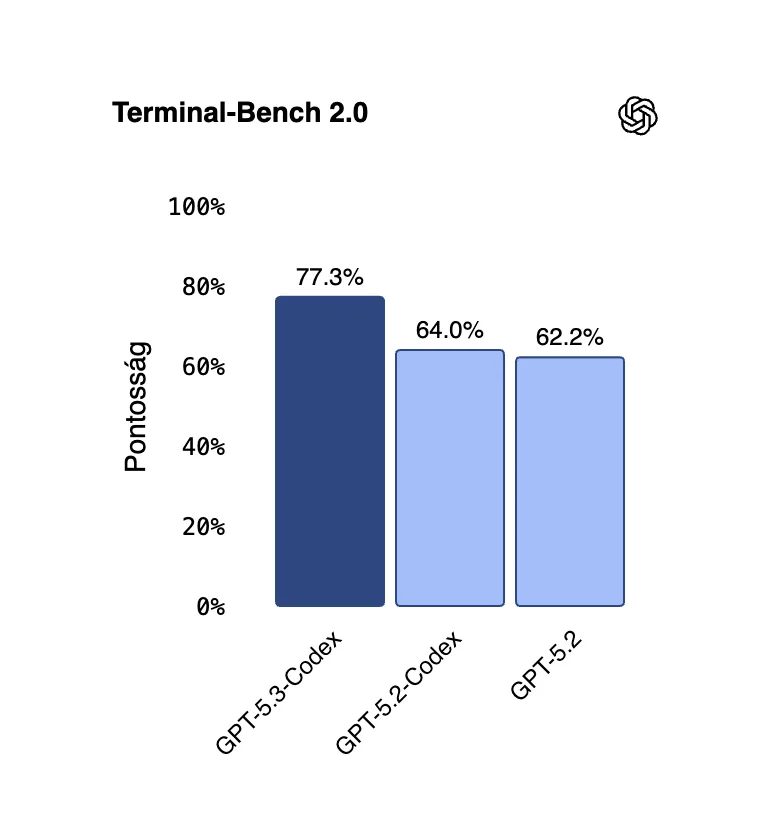
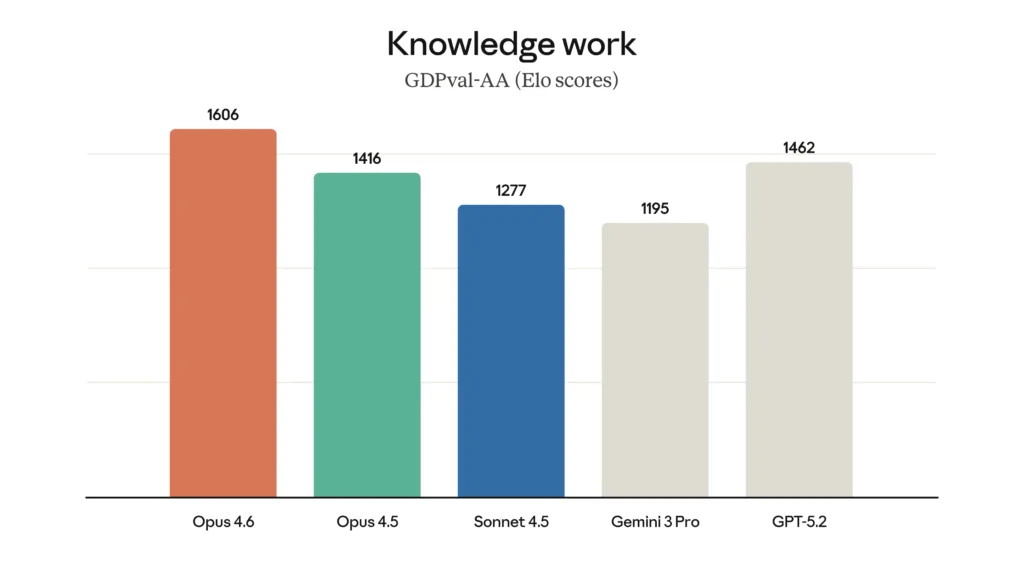
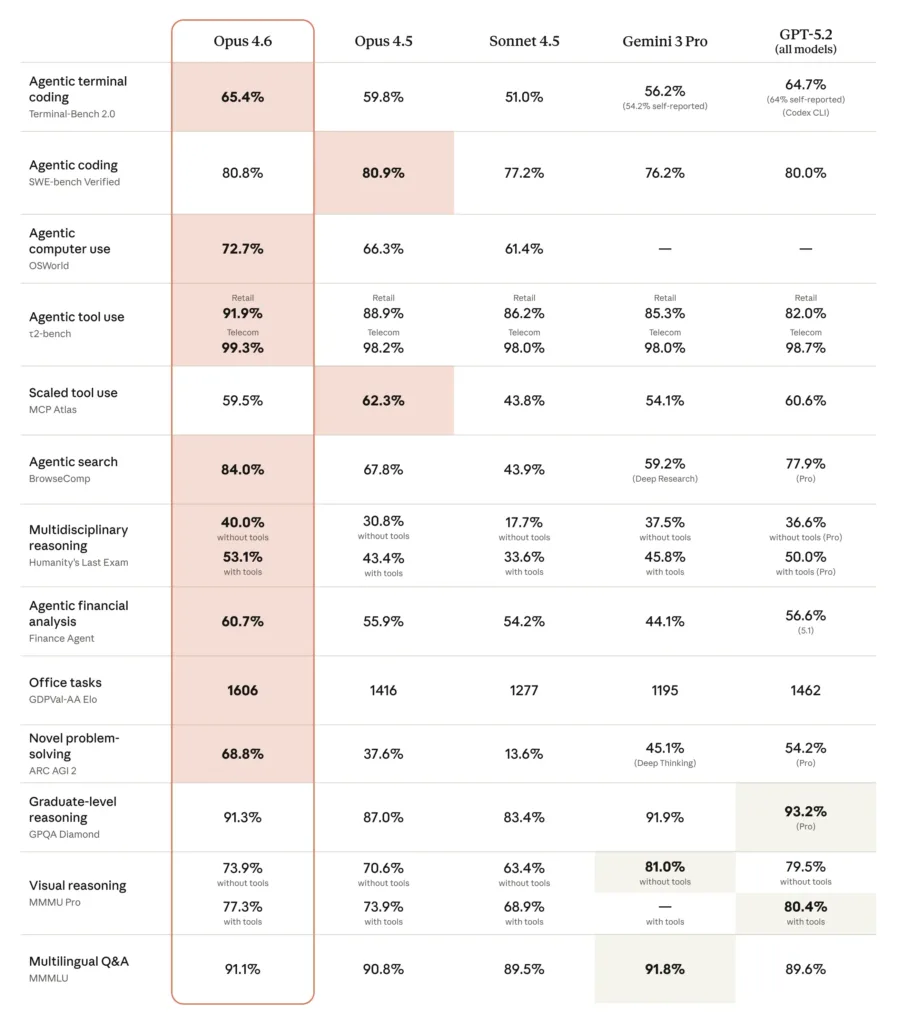
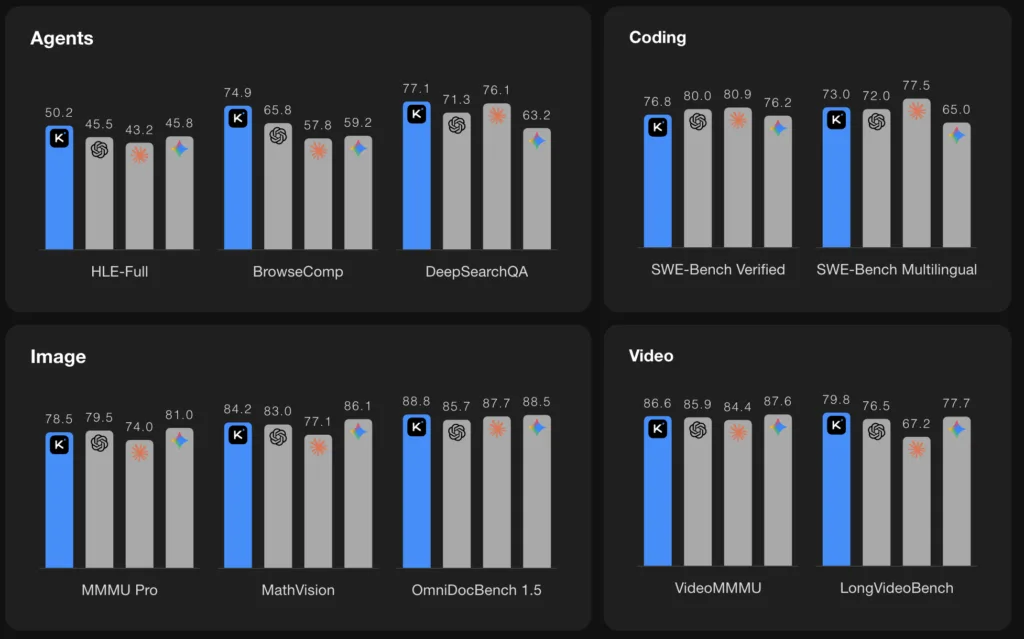
Microsoft Azure és OpenAI 2026: új korszak az AI-ban?
Amikor AI-ról beszélek, időről időre együtt említettem a Microsoft és az OpenAI nevét. A két cég együtt formálta azt, amit ma enterprise AI-nak hívunk. Azure + GPT modellek. Copilot. ChatGPT integrációk. Egy ökoszisztéma, ami nagyon gyorsan alapértelmezetté vált. Kettejük kapcsolatáról és az első lépésekről olvashattál már korábban. Abban a cikkben, nem feltétlenül ezt a jövő képet vázoltam neked, ami sok szempontból teljesül is.
Azt azonban akkor még nem lehetett megjósolni, ami most kezdődött el. Mert egy fontos stratégiai elmozdulás látszik. Egyértelműen, nem ez volt a tervük, de talán maga a piac, ami mindent megváltoztatott.
A Microsoft megerősítette, hogy hosszabb távon csökkenteni szeretné a függőségét az OpenAI modelljeitől, és saját foundation modellek fejlesztésébe fektet komoly erőforrásokat. Ez nem bulváros szakítás, hanem stratégiai érettség és reakció a többi szolgáltató (AWS, Google Cloud) által mutatott trendekre.
És habár elsőre ez sokkolóan hathat, én úgy gondolom, hogy inkább egy logikus lépés volt.
Mi történik valójában?
A Microsoft nem “kapcsolja le” az OpenAI-t. A két fél között továbbra is élnek szerződések, több évre szóló együttműködéssel. Az Azure OpenAI Service továbbra is működik.
Ami változik, az a hangsúly. A Microsoft saját AI-modell fejlesztési kapacitást épít, hiszen eddig erre nem sok energiát fordított. Inkább kényelmes pozícióból figyelte az eseményeket, miközben az OpenAI modelljeit kínálta. Most saját compute, saját kutatócsapatok, saját architektúra lesz. Ennek célja:
- nagyobb kontroll
- költségoptimalizálás
- kisebb külső függőség
- stratégiai önállóság
Enterprise világban ez teljesen logikus lépés, bár a Google-től már ebben eléggé lemaradt.
Egy nagyvállalat nem szeret egyetlen beszállítóra támaszkodni egy ennyire kritikus és gyorsan változó területen.
Miért most?
Az AI ma már nem kísérlet. Nem innovációs laborkérdés. Az AI ma „core” platform komponens.
Ahogy korábban a virtualizáció, majd a cloud, most az AI vált infrastruktúra-szintű döntéssé. És infrastruktúrában senki nem szeret 100%-ban egy partnerre építeni. Ez egy stratégiai diverzifikáció.
Mit jelent ez az AI-piacnak?
Ahogy én jelenleg látom, ez a lépés három dolgot jelez felénk.
- az AI verseny élesedik: Nem egy domináns modell világa jön, hanem több erős szereplőé.
- csökkenő különbség: A foundation modellek (pl.: GPT, Claude, Gemini, Llama) közötti különbségek egyre kevésbé jelentenek majd valódi versenyelőnyt. Ha több nagy szereplő saját modellt fejleszt, az árversenyt és innovációt hoz.
- AI platformokká alakulás: A cloud szolgáltatók AI-first platformmá válnak. Az AI nem kiegészítő lesz, hanem a platform része.
Ez nem csak Microsoft történet. Ugyanez látszik a Google és az Amazon oldalán is, saját modellekkel, saját AI stackkel.
És mi lesz az OpenAI-jal?
Ez egy igazán fogós kérdés. Amit látunk: az OpenAI továbbra is jelentős befektetéseket von be, masszív compute igénnyel működik, és komoly piaci jelenléte van.
Az AI modellek fejlesztése extrém költséges. GPU, adat, kutatás, energia. Ez nem egy olcsó sport, és több korábbi előrejelzés és beszámoló szerint is, az OpenAI anyagi gondokkal küszködik.
A piac most abba az irányba halad, ahol a nagy szereplők saját infrastruktúrára és saját modellekre támaszkodnak. Ez nem feltétlenül gyengíti az OpenAI-t, de átrendezi az erőviszonyokat.
Miért fontos ez neked?
Ha cloud irányba tanulsz, ha AI-ban gondolkodsz, ha karrierváltóként nézed ezt a világot, akkor ez egy nagyon fontos jel. Az AI nem egy céghez kötött technológia. Az AI egy platformréteg.
És platformrétegben mindig az nyer, aki érti az architektúrát, nem csak a konkrét API-t.
Ha ma GPT-t tanulsz, jó úton jársz.
De még jobb úton jársz, ha azt tanulod meg:
- hogyan épül fel egy LLM-alapú rendszer
- milyen módon működik egy RAG architektúra
- miképp kezeljük a token költséget
- hogyan tervezzünk modell-agnosztikus rendszert
(Modell-agnosztikus: olyan megoldás vagy rendszer, ami nem függ egy konkrét AI modelltől, és több különböző modellel is működhet – pl. GPT, Claude, Gemini, Llama)
Mert ahogy Te magad is tapasztalod a modellek jönnek-mennek és csak az architektúra állandó.
Jön a folytatás
Ebben a cikkben a stratégiai képet néztük meg: mi történik a Microsoft és az OpenAI kapcsolatában, és mit jelent ez a piac számára.
A következő részben viszont konkrétan arról fogok írni:
Mit jelent ez nekünk, Azure és OpenAI felhasználóknak?
- Stabil marad az Azure OpenAI?
- Kell-e újratervezni az architektúrát?
- Változik a Copilot jövője?
- Hogyan gondolkodjunk a vendor lock-in jelenségről 2026-ban?
Abban az esetben, ha Azure-ban vagy AI-ban építkezel, azt a részt ne hagyd ki.
Ha kíváncsi vagy, hogyan folytatódik a történet akkor ne maradj me a folytatásról, ahol már kicsit gyakorlati szemmel is nézzük a kérdést.
Érdekelnek a hasonló Cloud és AI tartalmak?
- Iratkozz fel az InfoPack hírlevélre.
- Kövess LinkedIn-en.
- Iratkozz fel a YouTube csatornámra, ahol rendszeresen jelentkezem új szakmai videókkal.
- És ne feledkezz el megkeresni TikTok-on sem.