

Docling: Így készíts tökéletes adatot bármilyen RAG-hez
Aki rendszeresen fejleszt vagy oktat AI megoldásokat – legyen szó Azure OpenAI-ról vagy bármilyen LLM integrációról –, az pontosan ismeri a problémát: a Retrieval-Augmented Generation (RAG) rendszerek lelke az adat, de az adataink többsége „halott” formátumokban csücsül. Itt jön képbe a Docling.
PDF-ek, Word dokumentumok, Excel táblák – Ezek emberi olvasásra kiválóak és látványosak, de a gépek számára gyakran emészthetetlenek.
Az Mentor Klubos Azure oktatásaim során rendszeresen bemutatom a klasszikus „Enterprise Chat” felépítést:
- Feltöltünk fájlokat egy Azure Storage Account-ra.
- Létrehozunk egy Azure AI Search indexet.
- Az OpenAI Foundry Studio-ban összekötjük a modellt az adatokkal.
A demó mindig látványos, de a valóságban sokszor hiányérzete van a z oktatáson résztvevőknek. Miért? Mert ha egy PDF tele van táblázatokkal, hasábokkal vagy lábjegyzetekkel, a beépített „chunking” (daraboló) algoritmusok szétesett, értelmezhetetlen szövegmasszát adnak át a keresőnek. Ugyanez a probléma az Excel táblázatokkal is.
Nincs olyan képzés, amikor nem teszik fel a kérdést: „Excel táblában is képes keresni az AI?„
Korábban az volt a válaszom, hogy nem és valójában közvetlenül nem is tud benne keresni, még RAG esetén sem.
Az eredmény: a használt LLM hiába zseniális, ha a kereső rossz kontextust ad neki. Garbage In, Garbage Out.
A megoldás: Strukturált Markdown
A tapasztalatom az, hogy az LLM-ek imádják a Markdown formátumot. A Markdown tisztán leírja, mi a főcím, mi az alcím, és ami a legfontosabb: megőrzi a táblázatok szerkezetét. Ezért a gyors és látványos bemutatóknál, már előkészített fájlokkal érkezem
De ki akar kézzel konvertálni több száz, vagy több ezer vállalati PDF-et? Senki. Ezért hoztam létre egy egyszerű, bárki által használható megoldást, aminek a lelke a Docling.
Mi az a Docling?
A Docling egy új generációs, nyílt forráskódú megoldás, ami nem csak kiolvassa a szöveget a fájlokból, hanem látja és érti is az oldalak szerkezetét (Layout Analysis).
Míg a hagyományos konverterek (pl. PyPDF) gyakran sorról sorra olvassák a szöveget (így a kéthasábos cikkek összekeverednek), a Docling felismeri a blokkokat. Képes komplex táblázatokat, fejléceket és lábjegyzeteket is helyreállítani, és mindezt egy tiszta, strukturált Markdown fájlba menti.
Mondhatjuk, hogy ez a RAG szempontjából aranyat ér. Ha a Docling által generált .md fájlt adod oda az Azure AI Search-nek (vagy bármilyen más vektorkeresőnek), a válaszok pontossága drasztikusan javulni fog. Ezzel pedig időt és pénzt takaríthatunk meg.
A kész eszköz: Docling RAG Converter
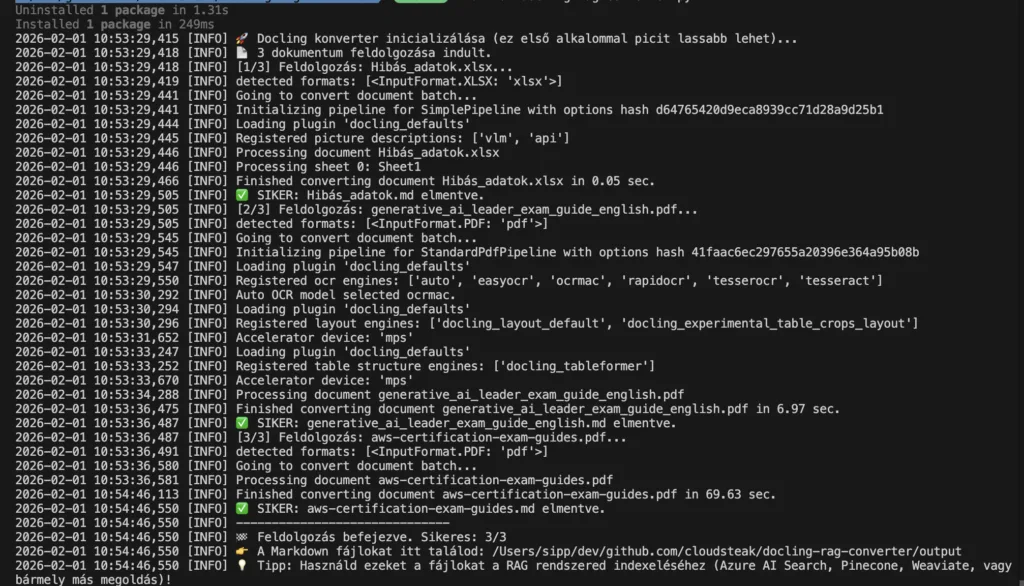
Ha szeretnéd kipróbálni, hogyan is teljesít és ne kelljen a nulláról kódolnod, készítettem egy Python alapú eszközt, amit a GitHub-on közzé is tettem. Ez az egyszerű projekt egy számomra kedvelt alapra épül: a Python mellett az uv csomagkezelőt használja, ami villámgyors és brutálisan egyszerű használni is.
A GitHub repo, ahol a megoldás van itt elérhető: https://github.com/cloudsteak/docling-rag-converter
Windows, Mac és Linux kompatibilis
Nem kell Python gurunak lenned. A célom az volt, hogy bárki, aki RAG rendszert épít, pillanatok alatt elő tudja készíteni az adatait.
1. Előkészületek
Szükséged lesz a git-re és az uv-re. Ha az uv még nincs fent, egy sorral telepítheted:
- Windows (PowerShell):
powershell -c "irm https://astral.sh/uv/install.ps1 | iex" - Mac/Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh
2. Töltsd le a kódot
Klónozd le a projektet a gépedre:
git clone https://github.com/cloudsteak/docling-rag-converter.git
cd docling-rag-converter
3. Futtasd a konvertert
Az uv zsenialitása, hogy nem kell manuálisan virtuális környezetet (venv) létrehoznod vagy pip-pel bajlódnod. A következő parancs mindent elintéz helyetted (letölti a Docling-ot, a függőségeket és a szükséges AI modelleket):
uv run docling-rag-converter.py
Hogyan működik?
- Az első futtatáskor a script létrehoz egy
inputés egyoutputmappát. (ha szükséges, de ez része a projektnek) - Másold be a feldolgozni kívánt fájljaidat az
inputmappába (PDF, DOCX, XLSX, HTML, PPTX). - Futtasd újra az
uv run docling-rag-converter.pyparancsot. - Dőlj hátra. A script végigmegy a fájlokon, és az
outputmappába generálja a tökéletesen formázott.mdfájlokat.
Miért jobb ez az Azure OpenAI-hoz?
Ha ezeket a generált Markdown fájlokat töltöd fel a Storage Account-ra a nyers PDF-ek vagy XLSX-ek helyett:
- Jobb Chunking: Az Azure AI Search a Markdown fejlécek (
#,##) mentén logikusan tudja darabolni a szöveget. Nem vág ketté mondatokat vagy gondolatmeneteket. - Táblázat-értés: A nyelvi modell (pl. GPT-4o-mini) a Markdown táblázatokat kiválóan értelmezi. Ha megkérdezed, hogy „Mennyi volt a bevétel Q3-ban?”, a modell pontosan ki tudja olvasni a cellát, míg egy szétesett szövegből csak találgatna.
- Kevesebb Hallucináció: Mivel a forrásanyag tiszta és strukturált, az AI kevésbé hajlamos kitalálni dolgokat.
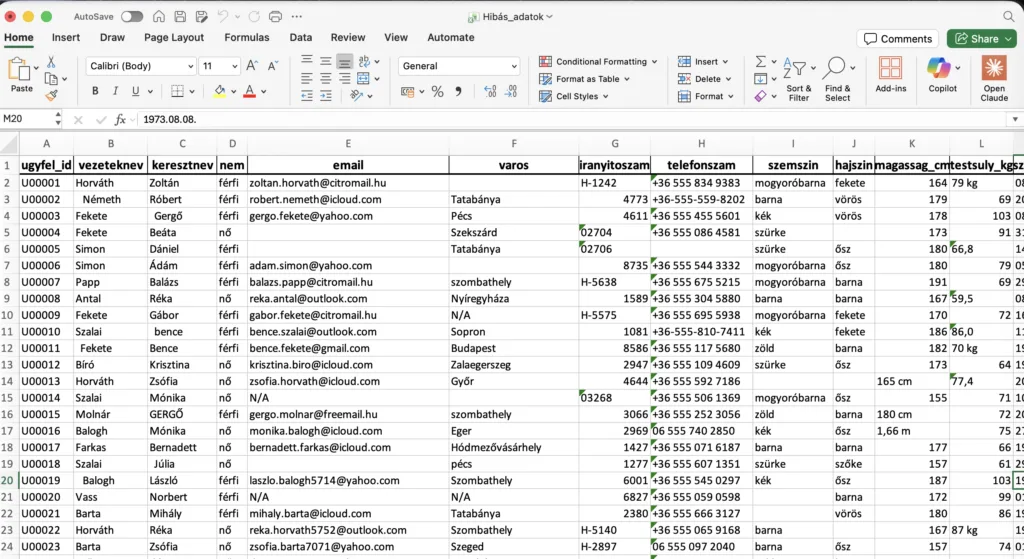
Eredeti XLSX:
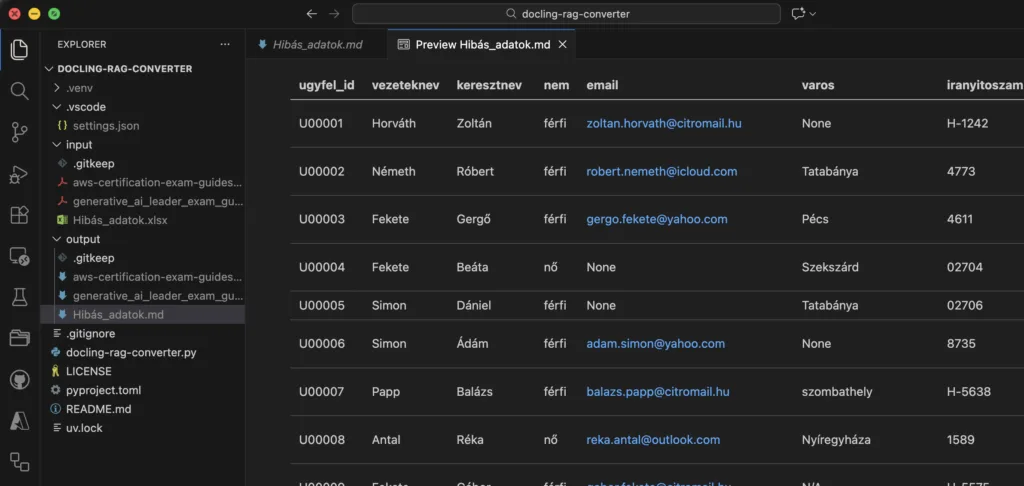
Konvertált md fájl (előnézetben), AI által támogatott formában:
Összegzés
A Docling használatával a „fekete doboz” PDF-ekből és Excel fájlokból strukturált, szemantikus Markdown-t csináltunk. Amikor ezt feltöltöd a Storage Account-ra, és indexeled a Foundry-ban, a kereső pontosan tudni fogja, hol kezdődik egy táblázat, és melyik adat melyik oszlophoz tartozik.
Az eredmény? Egy RAG alapú dokumentum keresési megoldás, amellyel az AI pontosan válaszol.
Ez a kis extra lépés a pipeline elején választja el a „játék” demókat a valódi, production-ready vállalati megoldásoktól. Próbáld ki a megoldást, és kezd el Te is AI-al kezelni a céges dokumentumokat, bármilyen RAG megoldással!
Te hogyan oldod meg az adat-előkészítést? Írd meg a véleményed vagy a tapasztalataidat kommentben!
Ha pedig érdekelnek a hasonló Azure és AI tartalmak:
- Iratkozz fel az InfoPack hírlevélre.
- Kövess LinkedIn-en.
- Iratkozz fel a YouTube csatornámra, ahol rendszeresen jelentkezem új szakmai videókkal.
- És ne feledkezz el megkeresni TikTok-on sem.


