OpenClaw már Lightsail-en: autonóm AI agent percek alatt
2025-ben látványosan megváltozott az AI rendszerek iránya. A fókusz egyre inkább az úgynevezett Agentic AI felé fordult. Ebben a folyamatban nagy szerepe volt az MCP (Model Context Protocol) megjelenésének is, amely jelentősen megkönnyítette az AI rendszerek és különböző eszközök közötti integrációt.
Korábban főleg chat alapú AI rendszereket használtunk. A működés egyszerű volt: kérdeztünk valamit, az AI válaszolt. Ez sok esetben hasznos, de nem mindenre alkalmas nekünk.
Azóta az AI agentek rengeteget fejlődtek. Egyre ügyesebbek lettek, és sokkal könnyebben integrálhatók különböző rendszerekkel. Ennek köszönhetően egy új szintre léptek: megjelentek az autonóm AI agentek.
Ezek már nem csak válaszolnak egy kérdésre. Folyamatosan futnak a háttérben, figyelnek, reagálnak, feladatokat hajtanak végre, és különböző rendszerekkel kommunikálnak.
Ha belegondolunk, ez valójában nem egy teljesen új koncepció. Inkább egy természetes következő lépés. Az eddig különálló technológiák – AI modellek, automatizációk, integrációk – most kezdenek igazán összeérni.
Pont ezt a hullámot lovagolja meg az OpenClaw is. Valójában semmi újat nem hoz, hanem okosan összerakja azokat az elemeket, amelyek eddig is léteztek. A különbség inkább az, hogy nagyon alacsonyra teszi a belépési küszöböt ebbe a világba.
És most már az Amazon Lightsail segítségével ezt még könnyebb kipróbálni az AWS-ben.
Mi az az OpenClaw?
Az OpenClaw egy nyílt forráskódú autonóm AI agent.
Korábban Clawdbot vagy Moltbot néven is ismert volt, de a projekt most már OpenClaw néven fut tovább.
A működési modellje eltér attól, amit a klasszikus chat AI rendszereknél megszoktunk.
Az OpenClaw:
- folyamatosan fut a háttérben
- üzenetküldő platformokon keresztül kommunikál
- képes feladatokat végrehajtani
- kódot futtatni
- fájlokat kezelni
- weboldalakat böngészni
- automatizált munkafolyamatokat kezelni
Alapvető kommunikációs csatornái például:
- Slack (én ezt használom)
- Telegram
- Discord
Ez azt jelenti, hogy a felhasználó egy üzenetküldő alkalmazáson keresztül kommunikál az agent-el, miközben az a háttérben egy szerveren fut.
Miért érdekes a Lightsail integráció?
Az OpenClaw eddig is telepíthető volt saját infrastruktúrára.
Például:
- saját szerverre
- VPS-re
- cloud VM-re
- Kubernetes clusterre
Viszont ezek sok esetben túl bonyolultak lehetnek egy gyors kipróbáláshoz.
Ahogy arról már írtam az Amazon Lightsail pont ilyen a problémákra ad egyszerű megoldást: A Lightsail egy leegyszerűsített AWS szolgáltatás, amely előre konfigurált szolgáltatásokat kínál fix havi áron.
Most már az OpenClaw egy előre elkészített megoldásként is elérhető ezen a platformon.
A 90 napos ingyenes lehetőség
Ahogy megszoktuk az egyes szoplgáltatásokhoz több csomagot is igénybe vehetünk. Így van ez most is, viszont a Lightsail egyik csomagja különösen érdekes.
A konfiguráció:
- 2 vCPU
- 2 GB RAM
- 60 GB SSD
- 3 TB adatforgalom
Normál esetben ez 12 USD / hó.
Most azonban az AWS 90 napos ingyenes időszakot kínál erre a csomagra.
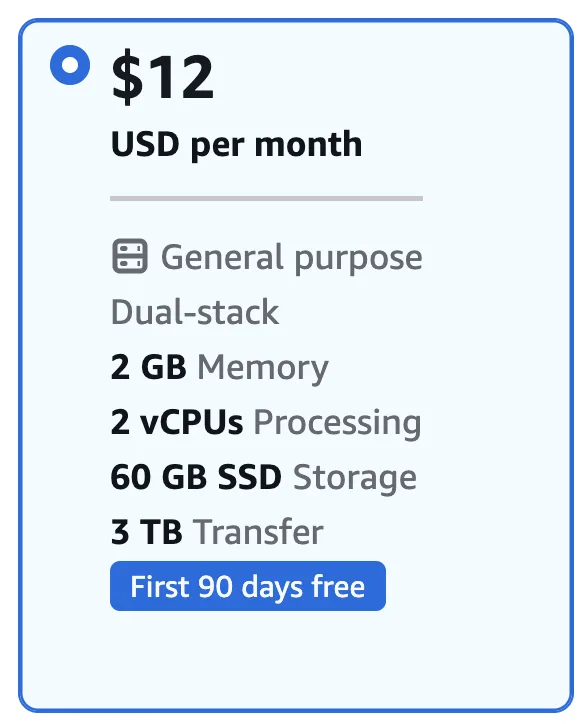
Ez gyakorlatilag azt jelenti, hogy három hónapig teljesen inygenesen lehet kipróbálni egy saját AI agent futtatását.
Hogyan illeszkedik ez a modern AI agent trendbe?
Az AI világában most egyre többet beszélünk az úgynevezett agentic AI rendszerekről.
A különbség egyszerűen megfogalmazva:
- Chat AI: A felhasználó kérdez, a modell válaszol.
- AI agent: A rendszer folyamatosan fut és feladatokat hajt végre.
Az agentek általában képesek:
- több eszközt használni
- API-kat hívni
- fájlokat feldolgozni
- automatizált workflow-kat futtatni
Az OpenClaw ebbe a kategóriába tartozik. Ezért sok érdeklődő, fejlesztő és AI mérnök számára érdekes projekt.
Mire lehet használni egy ilyen AI agentet?
Az OpenClaw mögött az az elképzelés áll, hogy az AI ne csak „beszéljen”, hanem dolgozzon is.
Néhány egyszerű példa:
- Automatizált Slack asszisztens: Egy csatornában figyeli a kérdéseket és segít dokumentációk alapján válaszolni.
- Fejlesztői workflow támogatás: Feladatokat gyűjt, fájlokat generál, scriptet futtat.
- Monitoring jelzések feldolgozása: Alert esetén információkat gyűjt és jelentést készít.
- Kisebb automatizációk: Weboldalak ellenőrzése, adatgyűjtés, riportok generálása.
Nyilván ezekhez további konfiguráció és integráció szükséges, de az alap koncepció már működőképes.
Mire figyelj az AI agenteknél!
Az AI agent rendszerek körül most nagyon nagy a hype.
Úgy látom, hogy túl gyorsan próbálnak valami nagyon komplex rendszert építeni. És ebben sokszor elvesznek.
Pedig az ilyen technológiáknál sokkal fontosabb: először kísérletezni. (valami egyszerűvel)
Ezért jó a Lightsail alapú megközelítés.
Egy kis VM-en el lehet kezdeni:
- tesztelni
- integrációkat kipróbálni
- promptokat finomítani
- agent workflow-kat építeni
Ha pedig megvan a tapasztalat, és komolyabb, kreatívabb megoldás kell, akkor lehet tovább lépni.
Én is ki fogom próbálni
Az OpenClaw bizonyos szempontból számomra is érdekes projekt, ezért a következő hetekben ki fogom próbálni a Lightsail alapú megoldást, és össze fogom hasonlítani azzal a környezettel, amit jelenleg itthon futtatok a saját mikro szerveremen.
Kíváncsi vagyok például:
- ugyanolyan stabil
- milyen teljesítményre képes
- mennyire egyszerű integrálni különböző rendszerekkel
- ugyanannyi hiba van-e benne mint a helyi szerveren futó verzióban
Ha lesznek érdekes tapasztalataim, arról külön cikkben is fogok írni.
Fontos: ezekkel az agentekkel óvatosan kell bánni
Szeretném azonban mindenki figyelmét felhívni, hogy felelősséggel használja.
Az autonóm AI agentek nem csak válaszolnak, hanem aktívan cselekszenek. Kódot futtathatnak, fájlokat kezelhetnek, API-kat hívhatnak, vagy akár külső rendszerekkel is kommunikálhatnak.
Ez hatalmas lehetőség, de egyben kockázat is.
Ha egy agent túl széles jogosultságot kap, vagy rosszul konfiguráljuk, akkor könnyen okozhat problémát – akár saját rendszereinkben, akár más szolgáltatásokban.
Ezért az ilyen rendszereket mindig:
- korlátozott jogosultságokkal érdemes futtatni
- izolált környezetben tesztelni
- és tudatosan felügyelni
Az AI agentek nagyon erős eszközök lehetnek, ezért felelősséggel kell használni őket.
Pont ezért érdemes először kísérletezni velük, mielőtt komolyabb rendszerekbe integrálnánk őket.
Összegzés
Az OpenClaw sokak szerint egy izgalmas új irányt képvisel az AI rendszerek világában. Ezzel kapcsolatban én kicsit szkeptikus vagyok. Az azonban tény, hogy felkavarta az állóvizet.
Akik eddig nem merték kipróbálni az autonóm AI agenteket, azoknak most jó lehetőség nyílik rá. Az Amazon Lightsail integráció jelentősen leegyszerűsíti az indulást.
A 90 napos ingyenes csomag kifejezetten jó lehet arra, hogy valaki elkezdjen kísérletezni ezekkel a rendszerekkel, és saját tapasztalatot szerezzen.
És egy dolgot érdemes mindig szem előtt tartani: az ilyen rendszereket mindig csak felelősséggel használjuk.